| Разработка приложений с помощью Mozilla / автор: Н.Макфарлейн | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
11. Глава:
RDF
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
В этой главе излагаются основы RDF - формата представления информации, который широко используется платформой Mozilla. RDF является приложением XML, принятым в качестве спецификации Консорциумом WWW (W3C). Это одна из наиболее непривычных технологий, лежащих в основе Mozilla, однако при правильном применении RDF оказывается мощным и удобным инструментом. Немногие приложения могут делать что-либо полезное, не получая информации извне, и приложения Mozilla не составляют исключения. RDF - удобный способ передачи и хранения небольших количеств информации, предназначенной для неоднократного использования. Платформа Mozilla располагает средствами обработки информации в формате RDF и сама частично основана на этом формате. В той или иной степени от него зависит функционирование большинства приложений, входящих в состав пакета Mozilla. Эта глава посвящена, прежде всего, концепциям, лежащим в основе RDF, и его синтаксису. Это весьма обширная тема сама по себе, поэтому конкретные вопросы поддержки RDF в рамках платформы Mozilla занимают в данной главе немного места. Эту лекцию следует рассматривать как введение в RDF, подобно тому, как глава 5 "Сценарии" представляет собой введение в JavaScript. Конкретные применения RDF подробно рассматриваются в следующих главах - в главе 12 "Оверлеи и chrome", главе 14 "Шаблоны" и в главе 16 "Объекты XPCOM". Для того чтобы понять смысл многих компьютерных технологий, часто достаточно беглого взгляда. Однако эта стратегия не работает при встрече с действительно новыми и необычными подходами. В этом случае приходится притормозить и заняться систематическим изучением материала. RDF - одна из таких технологий и одновременно ключ к разнообразным функциям Mozilla, которые кажутся простыми для понимания. Итак, что же такое RDF? Начнем с того, что существуют различные виды информации. Одна из классификаций подразделяет информацию на содержимое, данные и факты. Каждая из этих трех категорий обрабатывается по-разному. Содержимое обрабатывается как целое - отобразить эту HTML- страницу, воспроизвести этот музыкальный файл и т.п. Данные обрабатываются по отдельным фрагментам - добавить запись к базе данных, отсортировать список объектов. Информация в форме фактов реже встречается в информационных технологиях. Факты можно рассматривать как элементы данных, имеющие форму утверждений. Факты используются обычными людьми в повседневной жизни, учеными, а также специалистами в области, называемой инженерией знаний. Следующие утверждения представляют собой простые примеры фактов. Я ходил в магазин. Луна состоит из зеленого сыра. Том, Дик и Гарри - братья. Эта функция никогда не используется. Каждый человек должен найти собственный путь в жизни. Неважно, являются ли эти утверждения истинными. Неважно, каков их источник, и согласен ли с ними хоть кто-нибудь. Важно то, что их можно записать некоторым универсальным способом (в данном случае - на русском языке). Записывая факты, мы перемещаем их из своего сознания туда, где их можно зафиксировать в соответствии с определенными правилами или формальными спецификациями, что позволяет в дальнейшем работать с фактами различными способами. Только после того, как факты зафиксированы, можно заняться выяснением их истинности или значимости. В практическом разделе этой главы мы познакомимся с некоторыми приемами моделирования - одного из подходов к выявлению и фиксации фактов. Окружающий мир, включая сферу информационных технологий, насыщен "фактоподобной" информацией. Однако подавляющее большинство сведений не представлено в форме, удобной для обработки фактов. Лишь немногие программисты в своей практике сталкиваются со специализированными системами обработки фактов, однако код любого из них содержит множество подразумеваемых фактов. Эти подразумеваемые факты используются для решения других задач. Напротив, RDF целенаправленно разработан как формат для фиксации фактов. Примером крайне примитивной и тривиальной системы хранения "фактоподобной" информации, не использующей формата RDF, может служить файл закладок классического браузера, находящийся в каталоге профиля пользователя. Вот пример записи в таком файле: <A HREF="http://www.mozilla.org/" ADD_DATE="961099870" LAST_VISIT="1055733093" ICON="http://www.mozilla.org/images/mozilla-16.png" LAST_CHARSET="ISO-8859-1"> The Mozilla Organization </A> Этот фрагмент содержит ряд сведений об указанном URL: дату его добавления к списку закладок, дату последнего посещения и т.д. Атрибуты XML, в которых хранится эта информация, могут рассматриваться как простые данные или как описание фактов. Хотя для описания фактов можно использовать простой XML (или архаичный псевдо-HTML, как в этом примере), лучше использовать специализированное приложение XML с определенным синтаксисом. Как раз таким приложением является RDF. Файл закладок не использует RDF для обеспечения обратной совместимости. Многие специалисты называют информацию такого рода метаданными. Предполагается, что этот термин позволяет разграничить информацию (в данном случае - содержимое web-документа, на который указывает URL) и "информацию об информации" (описание документа и самого URL), которая и называется метаданными. На практике, если программист пишет код для работы с файлом закладок, единственной интересной для него информацией являются так называемые метаданные - содержание этого файла. С его точки зрения метаданные оказываются обычными данными, с которыми он должен работать. То, что для одного человека является метаданными, для другого - просто данные. Таким образом, при изучении RDF концепция метаданных может лишь запутать и без того сложную тему. Говоря коротко, термин "метаданные" часто используется без необходимости. С точки зрения программиста единственным элементом RDF, который заслуживает звания метаданных, является информация о типах. Все остальное следует рассматривать как простые данные или, точнее, простые факты. С точки зрения самого формата RDF нет какой-то отдельной категории фактов, имеющих статус "метафактов". RDF имеет свою терминологию. Вот пример факта, выраженного средствами RDF: <Description about="file:///local/writing/" open="true"/> Говоря попросту, эта строка утверждает, что папка /local/writing/ открыта. Более строгая интерпретация в терминах RDF такова: "Существует субъект (или ресурс) с именем file:///local/writing/, имеющий предикат open, значением (объектом) которого является анонимная строка литералов "true"". Это довольно неуклюжий язык, и сейчас нам предстоит разобраться, что все это означает. Наконец, следует сказать, что RDF не является визуальным языком. Mozilla не может непосредственно отобразить документ RDF подобно документам XUL или HTML. Для отображения данных RDF необходимо подключить файл или другой источник данных к элементам управления XUL. При этом собственно обработка HTML происходит внутри платформы незаметно для пользователя, а иногда и без участия программиста. Центральным понятием в контексте обработки RDF на платформе Mozilla является понятие источника данных. На схеме в начале этой главы показано, что поддержка RDF пронизывает всю платформу от инфраструктуры, скрытой от пользователя, до графического интерфейса. Часть инфраструктуры составляют компоненты XPCOM, которые разработчик приложений может использовать для работы с данными RDF. Существует удобная библиотека, которая облегчает работу с этими компонентами. Мы будем называть ее RDFlib, хотя, строго говоря, она является частью библиотеки JSLib. Технология RDF образует связующее звено между прикладной и интерфейсной частями платформы. Это возможно благодаря тому, что как XUL, так и компоненты объектной модели приложения (AOM) непосредственно поддерживают работу с форматом RDF. Системы шаблонов и оверлеев, созданные для более эффективной работы XUL, также основаны на RDF. К сожалению, производительность работы с RDF в версиях Mozilla 1.x оставляет желать лучшего. Не используйте RDF для работы с данными, состоящими из миллионов записей; это - не СУБД. Однако для небольших наборов данных производительность более чем удовлетворительна. 11.1 Использование RDF в MozillaКлассический пакет приложений Mozilla в значительной степени основан на RDF. В некоторых случаях работа с RDF подразумевает создание и хранение файлов в этом формате, а в других речь идет о потоках данных, которые создаются при работе приложения и передаются между его компонентами. Например, следующая информация хранится в RDF-файлах:
Классический браузер и Netscape 7 создают и используют RDF-файлы и для многих других целей. Многие расширения к браузеру, доступные на сайте www.mozdev.org и других сайтах, также используют RDF для хранения данных. RDF - не только формат файлов, но и модель данных. Инфраструктура платформы Mozilla использует факты RDF в различных местах, не обязательно читая или создавая файлы в этом формате. Например, информация, хранимая в другом формате, может автоматически преобразовываться в RDF для обработки внутри платформы. Вот некоторые элементы платформы, при работе с которыми используется модель данных RDF:
RDF не используется для решения следующих задач: хранение информации о подписках и паролях, хранение баз сообщений электронной почты и конференций, кэш просмотренных web-документов. 11.2 Стратегии изучения RDFИзучение RDF подобно полету. Оторваться от земли трудно, но если уж это получилось, перед вами открывается огромный простор. Почему это так, и как облегчить процесс первоначального освоения RDF? Вот некоторые соображения. Синтаксис XML отличается высокой избыточностью. Когда наши глаза и мозг поглощены разбором формального синтаксиса, без надлежащего опыта бывает трудно сосредоточиться на содержательных вопросах. Даже разработчики официальной спецификации RDF признают эту проблему. Следует пользоваться неформальным упрощенным синтаксисом при проектировании и задействовать формальный RDF только при кодировании и тестировании. В этой главе, за исключением примеров реального кода, используется упрощенный синтаксис. RDF как формат и модель данных часто смешивают с его применениями. Стоит иметь в виду, что природа самого RDF и цель его применения в том или ином случае, - вещи совершенно разные. Изучение принципов управления документами не поможет при освоении RDF. Это все равно что пытаться разобраться с сервером баз данных, изучая бухгалтерский пакет, использующий этот сервер. Лучше начать с изучения общих принципов фундаментальной технологии. Популярные введения в RDF предназначены для различных целевых групп. Поэтому не стоит тратить время, продираясь через объяснения, которые не соответствуют вашим целям или образу мыслей. Кроме того, RDF в полном объеме - довольно обширный стандарт, хотя и содержит всего лишь около десятка тегов. Фактически, он эквивалентен нескольким приложениям XML, упакованным в один стандарт. RDF охватывает широкий диапазон от простых данных до схем и мета-схем. Со всем этим многообразием довольно трудно освоиться, бегло прочитав один текст. Поэтому рекомендуем экспериментировать с RDF, начав с очень простых задач. Освойте основы, прежде чем состязаться с Эйнштейном. Как и любую масштабную технологию, RDF нельзя преодолеть одним прыжком - нужно двигаться постепенно. Наконец, RDF представляет собой специфическую сложность для тех, кто стремится к полной определенности и ясности. Концепции, лежащие в его основе, до сих пор переживают период становления. Идеология RDF продолжает развиваться, и пути этого развития могут быть весьма извилистыми. Вопросы о смысле некоторых сложных возможностей RDF до сих пор не имеют определенного ответа. Поэтому нужно принять RDF таким, какой он есть, и просто использовать его для своих целей. Тем не менее, RDF не является необычайно трудным для изучения. Существуют и более сложные приложения XML, например OWL. Тем, кто знаком с языком Prolog или подходами искусственного интеллекта, изучать RDF будет достаточно легко. 11.3 Введение в фактыВ основе синтаксиса любых приложений XML лежит концепция элемента, который часто соответствует одному тегу. В основе RDF лежит понятие факта, специфичное для этого приложения XML. Факт соответствует одному элементу, но не всегда соответствует одному тегу. Что же такое факт, и чем он может быть полезен? Эти вопросы обсуждаются в данном разделе. Специалисты по логике предикатов и дедуктивным системам могут лишь бегло просмотреть этот материал. Программист может получить первое представление о мире фактов по аналогии с известными технологиями, которые до некоторой степени "фактоподобны". В качестве примеров можно привести язык SQL и утилиту make. Управление записями в базе данных при помощи таких операторов SQL, как INSERT, DELETE и особенно SELECT до некоторой степени сходно с управлением фактами. Запрос к базе данных аналогичен запросу к системе обработки фактов. С другой стороны, правило командного файла утилиты make(1), на основе которого утилита определяет, какие файлы нуждаются в новой компиляции, также "фактоподобно". Правило из командного файла можно рассматривать как факт о файлах и "целях" (target) утилиты make. Еще один пример "фактоподобного" командного файла - конфигурационный файл программы sendmail, весьма сложный для чтения. У всех этих систем есть общее свойство: хранимые элементы данных независимы друг от друга и содержат несколько значений - каждый факт состоит из нескольких частей (полей в случае записи в базе данных, цели и зависимостей - в случае файла make). Работа с фактами подразумевает использование специального приложения, будь то сервер баз данных, утилита make или агент пересылки почты. Это приложение обрабатывает факты, после чего передает результаты пользователю или другой программе 11.3.1 Факты и структуры данныхФакты используются для описания и моделирования данных. Программисты, как правило, используют для моделирования структуры данных. Те программисты, которым приходится заниматься проектированием, могут использовать для этого словари данных и диаграммы UML. Пожалуй, простейший способ понять, чем факты отличаются от традиционных данных, - записать то и другое. Предположим, что мальчик и его собака играют с мячом на пляже. Описание этой ситуации, включающее четыре объекта реального мира (мальчик, пляж, собака, мяч), может храниться как структура данных или как факт. Начнем с обычных структур данных. В JavaScript эти данные можно сохранить в форме объекта1): {boy:"Том", dog:"Спот", ball:"теннис", beach:"Уайкики"}
Эта запись довольно близка и к структурам данных в C/C++ (struct). Ту же информацию можно сохранить и в виде массива JavaScript: [ "Том", "Спот", "теннис", "Уайкики" ] Все наши данные имеют один и тот же тип - строка, что соответствует идее массива. Массив с этими данными можно было бы создать и в C/C++. В программе на Perl можно было бы использовать список: ( "Том", "Спот", "теннис", "Уайкики", ) Существует много способов сохранить одни и те же данные, и каждый из них имеет свои достоинства и недостатки. Использование объекта или класса подразумевает, что все элементы данных (поля объекта) имеют общего владельца (объект), и во многих языках каждый из них имеет определенный тип. Использование массива подразумевает, что элементы пронумерованы и имеют один и тот же тип. Использование списка означает, что элементы упорядочены. Программист может выбрать наиболее подходящий вариант для конкретной задачи. Информация может быть записана и в виде факта - с использованием кортежа. Кортеж представляет собой группу из N элементов, где N - любое целое число. Как правило, каждый кортеж имеет фиксированное число элементов. Кортежи поддерживаются в явном виде лишь немногими языками программирования (SQL - одно из исключений), поэтому мы будем использовать математическую нотацию. Существует много вариантов такой нотации. Например, в спецификациях RDF иногда используется такая запись: < Том, Спот, теннис, Уайкики > Однако в этом варианте и других, подобных ему, кортеж легко спутать с тегом XML. Поэтому мы будем использовать следующую нотацию: <- Том, Спот, теннис, Уайкики -> Каждый из элементов кортежа называется терм. Позднее скобки в виде "птичьей лапки" будут напоминать нам о том, что некоторые кортежи (особенно интересные для нас) состоят из трех термов. Заключать термины в кавычки не нужно, поскольку это не язык программирования. Термы в кортеже считаются упорядоченными, но не пронумерованными (в отличие от массива), и не имеют заданных типов (в отличие от struct или класса). Смысл кортежа прост: эти термы связаны друг с другом. Каким именно образом они связаны - в общем случае неважно. Использование угловых скобок < и > намекает на существенную разницу между кортежами и другими структурами данных. Разница состоит в том, что кортеж представляет собой декларацию, утверждение, подобно тегу XML или определению класса. Примеры с различными структурами данных представляют собой выражения разных языков. Выражение может быть вычислено и присвоено переменной. Но невозможно вычислить декларацию или присвоить ее переменной. Декларация просто существует. Обработка декларации-кортежа состоит просто в том, что соответствующий факт признается истинным. Если кортеж для факта существует, то факт считается истинным, в противном случае - ложным. Значение для истинности факта нигде не хранится, оно вычисляется посредством сопоставления с существующими кортежами. Это позволяет не ограничивать заранее круг фактов, с которыми может работать система. Факты, для которых находится подходящий кортеж, признаются истинными, а все остальные - ложными. Пример кортежа, приведенный выше, обеспечивает истинность следующего факта "Том, Спот, теннис и Уайкики связаны друг с другом". Отметим, что кортеж содержит не всю информацию, которая заключалась в исходном утверждении. Например, он не отражает того, что Том и Спот были на пляже Уайкики одновременно. Это типичная ситуация для любой работы по сбору информации - приходится отбирать для фиксации наиболее важные сведения. В принципе, кортеж может содержать любое количество термов, в данном случае - четыре. Чтобы упростить наш пример, в дальнейших рассуждениях мы будем рассматривать только три из них - мальчик, собака и мяч. Мы считаем неважным, находились ли они на пляже или в каком-либо другом месте. Предположим, что нам необходимо зафиксировать эту ситуацию более подробно. Типичный подход к моделированию - начать с выявления существительных. На их основе могут быть спроектированы объекты, классы, сущности, таблицы или типы. То же самое может быть сделано и для фактов. В листинге 11.1 представлен пример объектов на Java Script, описывающих нашу ситуацию: var boy = { Pid:1, name:"Том", Did:null, Bid:null };
// name - имя
var dog = { Did:2, name:"Спот", Pid:null, Bid:null };
var ball = { Bid:5, type:"теннис", color:"зеленый" };
// type - тип, color - цвет
boy.Did = dog; // связать объекты друг с другом
boy.Bid = ball;
dog.Pid = boy;
dog.Bid = ball;
Листинг
11.1.
Объекты, моделирующие ситуацию с мальчиком и собакойPid, Did, и Bid означают идентификаторы человека, собаки и мяча соответственно (Person-id, Dog-id и Ball-id). Эти идентификаторы должны сделать объекты уникальными - возможно, существуют две собаки по имени Спот, или у Тома есть пять зеленых мячей. Помимо создания объектов, между ними установлены связи. Том и Спот имеют отношение к одному и тому же мячу, Спот - собака Тома, Том - человек (хозяин) Спота. Аналогичное моделирование может быть выполнено при помощи кортежей, как показано в листинге 11.2: <- 1, Том, 2, 5 -> <- 2, Спот, 1, 5 -> <- 5, теннис, зеленый ->Листинг 11.2. Кортежи, моделирующие ситуацию с мальчиком и собакой. Как и в случае реляционных данных, связи между объектами представлены парами одинаковых значений в разных кортежах. Если в предыдущем примере роль идентификаторов выполняли ссылки на объекты, здесь для этого используются целые числа. В листинге 11.2 есть одна пара единиц, одна пара двоек и две пары пятерок (5 в третьем кортеже участвует в двух парах). Как видно, кортежи являются довольно компактной нотацией, и в этом состоит одно из их преимуществ. В то же время существует проблема с именованием кортежей - их нельзя присвоить переменным и тем обозначить, к чему относится каждый из кортежей. Поэтому такой синтаксис сложнее для чтения. Тем не менее, как реляционные базы данных, так и системы, работающие с фактами, основаны на концепции кортежа. Обе попытки моделирования позволили описать некоторые существенные факты, но одновременно выявили ограниченность обоих подходов. Исходное описание ситуации таково: "Том и его собака Спот играют с мячом". Результаты двух попыток моделирования представлены в таблице 11.1:
Таблица 11.1 несколько приукрашивает ситуацию, поскольку учитывает подразумеваемое знание о назначении каждого объекта и кортежа. Тем не менее, она демонстрирует основную проблему обоих моделей - они отдают приоритет предметам (существительным), однако практически не могут отразить отношений между ними. В моделях не зафиксировано ни то, что Том является хозяином Спота, ни то, что Спот играет с мячом. Традиционное решение этой проблемы - создать дополнительные таблицы, объекты и т.п. Решение, подходящее для мира фактов, - сделать каждое существующее отношение термом в кортеже. Такой кортеж называется предикатом. 11.3.2 Предикаты и кортежиПредикатами называется особая группа кортежей. Поскольку все кортежи являются фактами, предикаты тоже являются фактами. Предикаты содержат как термы, представляющие предметы, так и термы, представляющие отношения между ними. Прямолинейная попытка добавления отношений могла бы выглядеть так, как показано в листинге 11.3, который является развитием листинга 11.2: <- 1, Том, хозяин, 2, играет-с, 5 -> <- 2, Спот, принадлежит, 1, играет-с, 5 -> <- 5, теннис, зеленый ->Листинг 11.3. Добавление отношений к модели с кортежами В этом примере отношения имеют тот же статус, что и другие данные. Первый кортеж можно даже прочитать почти как предложение на естественном языке: "Идентификатор-1 (Том) - хозяин идентификатора-2 (Спота) и играет с идентификатором-3 (мячом)". Ясно видно, что это более точное и полнее описание ситуации, чем наши предыдущие опыты. Этот процесс аналогичен моделированию с использованием метода "сущность - связь", который применяется при проектировании баз данных. Теперь добавим к нашему жаргону еще одно слово. Кортеж, содержащий информацию об отношениях, называется предикатом. Вместе с тем, предикатом называют и отдельный терм в кортеже, выражающий отношение между двумя другими термами. Чтобы избежать путаницы, мы будем стараться использовать термин "предикат" только в последнем смысле - для обозначения отдельного терма. Для группы связанных термов мы будем использовать термины "кортеж", "триплет" (для кортежа из трех термов) или "факт". Описание ситуации в листинге 11.3 все же не идеально, поскольку некоторые кортежи содержат более одного терма, выражающего отношение. Если кортеж может содержать более одного терма-предиката, это существенно усложняет обработку фактов. Поэтому мы можем улучшить наш пример. В листинге 11.4 показано, как можно разбить некоторые кортежи на два, так чтобы в каждом кортеже остался только один предикат. <- 1, Том, хозяин, 2 -> <- 1, Том, играет-с, 5 -> <- 2, Спот, принадлежит, 1 -> <- 2, Спот, играет-с, 5 -> <- 5, теннис, зеленый ->Листинг 11.4. Модель, основанная на кортежах с одним предикатом Ценой некоторого дублирования информации мы смогли разделить предикаты, и теперь наши кортежи еще удобнее читать. Эквивалентная процедура при проектировании баз данных называется нормализацией, а сходная операция над программным кодом - факторизацией. В любом случае, это управление информацией по принципу "разделяй и властвуй". Однако мы можем сделать наше описание еще более удобным для обработки. Для этого унифицируем кортежи так, чтобы каждый из них имел ровно три элемента (N = 3). Результат показан в листинге 11.5. <- 1, имя, Том -> <- 1, хозяин, 2 -> <- 1, играет-с, 5 -> <- 2, имя, Спот -> <- 2, принадлежит 1 -> <- 2, играет-с, 5 -> <- 5, тип, теннис -> <- 5, цвет, зеленый ->Листинг 11.5. Модель, основанная на триплетах с одним предикатом Теперь мы имеем дело только с триплетами. Триплеты с одним предикатом лежат в основе практически всех систем работы с фактами. Думая об обработке фактов, следует опираться на концепцию триплетов с одним предикатом, а не произвольных кортежей. Стоит отметить, что на пути выделения предикатов и отношений можно зайти слишком далеко. Последние два триплета в листинге 11.5 отличаются от остальных. Теннис и зеленый представляют собой простые описательные свойства, а не элементы ситуации, такие как мальчик или мяч. Подобно тому, как можно создать чрезмерно нормализованную базу данных со многими таблицами или множество тривиальных классов в случае объектного проектирования, можно сформулировать и избыточное количество тривиальных фактов. Однако все зависит от задачи - если тривиальные факты представляют интерес в ее контексте, можно смело фиксировать их. Поскольку триплеты широко используются, их элементы имеют специальные названия. Как уже было сказано, терм, выражающий отношение, называется предикат, первый терм - субъект, а третий (в нашей записи) - объект. Эти термины восходят к логике и лингвистике, и "объект" не имеет никого отношения к объектам в смысле объектно-ориентированного программирования. На вопрос, высказывание о каком из этих трех элементов представляет собой триплет, можно ответить по-разному. Чаще всего считается, что это высказывание о субъекте. В листинге 11.5 мы всегда записывали субъект триплета первым, а предикат - вторым. Это соглашение соблюдается всюду в этой книге. Факты об отношениях могут быть записаны различными способами. Например, в языке Prolog их можно записывать так: предикат(субъект, объект) plays-with(1,5) играет-с(1,5) В языках Lisp или Scheme то же самое может быть записано как: (предикат субъект объект) (plays-with 1 5) (играет-с 1 5) Можно записывать такие факты и на естественном языке субъект предикат объект 1 играет с 5 И, разумеется, факты об отношениях можно выразить на языке XML, для чего и был разработан формат RDF. Один из вариантов - записать факт в форме одного тега2): <Description about="субъект" предикат="объект"/> <Description about="1" играет-с="5"/> Наконец, для удобной и компактной записи фактов может использоваться нотация для кортежей, которую мы задействуем в этой главе, а также еще более простой синтаксис без пунктуации, используемый некоторыми специалистами по RDF: <- субъект, предикат, объект -> субъект предикат объект Если вы склонны придерживаться синтаксиса реального языка программирования, можете следовать простой и ясной нотации Prolog или Lisp, которая использовалась для записи и обработки фактов на протяжении десятков лет. Альтернативный вариант - применять RDF. Рис. 11.1 Граф связей между кортежами 1 играет-с 5 5 тип теннис 1 имя Том 1 хозяин 2 2 принадлежит 1 2 имя Спот 5 цвет зеленый 2 играет-с 5 11.3.3 Три способа организации фактовК настоящему моменту мы выработали подходящую структуру для описания факта. Какими же способами можно хранить ее в компьютере? Существует несколько вариантов. Первый способ - хранить факты как набор независимых элементов. В реляционной СУБД этому соответствуют отдельные записи в таблице с тремя полями; в объектной технологии - коллекция элементов (например, set или bag). Запись в листинге 11.5 соответствует такому подходу. Этот простой подход очень гибок. В любой момент можно добавить новые факты или удалить существующие. Не нужно поддерживать никакой внутренней структуры. Такое решение можно сравнить с обычным ведром - при необходимости вы просто "наливаете" в него факты или "выливаете" их. Одно из главных преимуществ "ведра с фактами" - легкость объединения фактов из разных источников. Вы просто "наливаете" их в ведро, получая в результате одну большую коллекцию фактов. Когда вы обращаетесь к ней, все факты имеют одинаковый статус независимо от происхождения. Это просто объединение двух множеств. Второй подход к хранению фактов основан на признании того, что между отдельными фактами существуют связи, образующие некую структуру. Она может храниться как традиционная структура данных, в которой связи между кортежами будут представлены указателями или ссылками. Поскольку связи могут носить произвольный характер, эту структуру следует рассматривать как граф, а, скажем, не как список или дерево. Именно граф является наиболее общим способом представления взаимосвязанных данных. Графы имеют ребра (линии) и вершины (узлы, пересечения ребер). И ребра, и вершины могут быть именованными. Граф можно и изобразить на рисунке. На рисунке 11.1 показаны связи между фактами, приведенными в листинге 11.5. 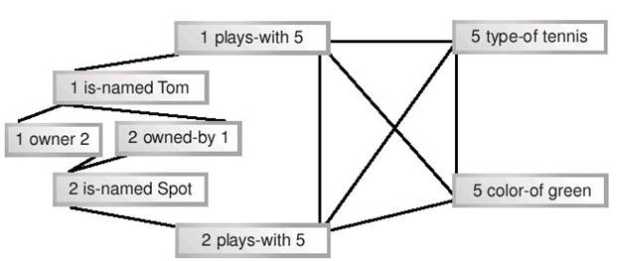 Рис. 11.1. Связи между фактами, приведенными в листинге 11.5. Пожалуй, это слишком сложная схема для простой системы, состоящей из мальчика, собаки и мяча. Более того, на ней недостает некоторых линий - нам следовало бы добавить еще три связи между фактами, содержащими "1" и три связи между фактами, содержащими "2", доведя их общее число до 18. Чтобы сделать схему менее громоздкой, добавим к ней вершины, вынеся идентификаторы из кортежей. Измененная схема, на которой осталось всего 12 ребер, показана на рисунке 11.2. 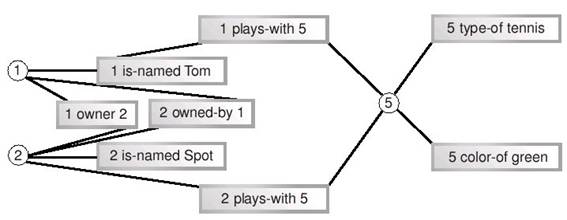 Рис. 11.2. Упрощенный граф связей между кортежами. Наш подход - выделение элементов из кортежей - позволил несколько упростить схему, поэтому продолжим двигаться в том же направлении. Мы можем не только выделить идентификаторы, но и разбить все триплеты на отдельные термы. Более того, можно заметить, что некоторые кортежи являются взаимно обратными, выражающими две стороны одного и того же отношения (в нашем примере - "хозяин" и "принадлежит"). Мы можем избежать такого дублирования информации, сделав ребра нашего графа направленными. Двигаясь по стрелке, мы получаем один предикат, двигаясь против стрелки - обратный ему. Результат всех этих усовершенствований показан на рисунке 11.3. 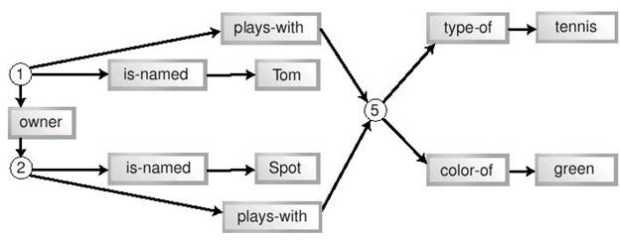 Рис. 11.3. Значительно упрощенный граф связей между кортежами. Наконец, мы можем заметить, что каждый предикат имеет ровно одну входящую и одну исходящую стрелки. Поэтому мы можем превратить предикаты в именованные стрелки (ребра), освободив граф от избыточных узлов (вершин). Результат этой процедуры показан на рисунке 11.4, на котором также изменено расположение некоторых элементов. 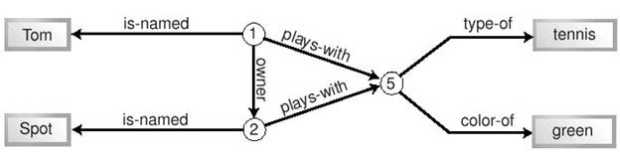 Рис. 11.4. Граф связей между кортежами в нотации RDF. На этом рисунке ясно видны отношения, выражаемые предикатами, и их характер. Существуют второстепенные предикаты, которые служат лишь для описания идентификаторов (имя, цвет, тип), и более важные предикаты (хозяин, играет-с), содержащие информацию об отношениях между интересующими нас идентификаторами. Таким образом, решения использовать идентификаторы для каждого моделируемого объекта реального мира (см. листинги 11.1 и 11.2) и выделить идентификаторы на схеме (см. рисунок 11.2) оказались продуктивными. Как мы видим, идентификаторы играют важнейшую роль в построении компактной и выразительной схемы. Граф на рисунке 11.4 соответствует официальной нотации RDF для графов. Круги и эллипсы изображают идентификаторы, а прямоугольники - литералы. В усовершенствовании нуждается система имен идентификаторов и предикатов. В качестве идентификаторов могут использоваться URL - вскоре мы обсудим этот вопрос. Данные RDF, представленные в форме графа, позволяют программам обработки фактов двигаться от одного факта к другому, выбирая ребра для перехода в зависимости от конкретной задачи. Наконец, существует третий способ организации фактов, часто используемый в RDF-документах Mozilla. Представьте себе, что факты беспорядочно рассыпаны по кухонному столу. Возьмите воображаемую иголку с ниткой и пропустите нитку через термы, имеющие отношение к определенной теме. Теперь, если понадобится информация по этой теме, достаточно потянуть за нужную нитку, и можно выбрать все термы и связанные с ними факты, относящиеся к теме. На рисунке 11.5 показана воображаемая линия, которая соединяет все идентификаторы на нашем графе. RDF не располагает синтаксисом для построения таких линий. Однако нужный результат может быть достигнут при помощи специальных тегов RDF, называемых контейнерами. Поскольку RDF может представлять только факты, контейнеры содержат факты. Любой терм любого факта может быть включен в один или несколько контейнеров. Чаще всего для этого используется субъект. Другие термы факта хранятся обычным образом. Рисунок 11.6 повторяет рисунок 11.5, однако вместо линии на нем показан контейнер, причем факт принадлежности к нему изображен на схеме наряду с прочими фактами. Контейнер представлен на схеме термом с соответствующей подписью. Единственное, что отличает факт принадлежности к контейнеру от прочих фактов - способ именования предикатов. Любой предикат, выражающий принадлежность терма к контейнеру, автоматически получает в качестве имени порядковый номер. В отличие от условных номеров, заменяющих на схеме идентификаторы субъектов и объектов, нумерованные предикаты действительно используются в синтаксисе контейнера RDF. 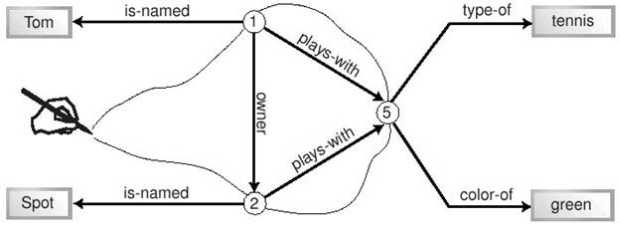 Рис. 11.5. Граф RDF, на котором сходные термы объединены при помощи линии. 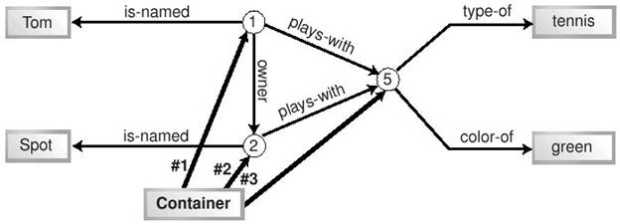 Рис. 11.6. Граф RDF, на котором сходные термы объединены при помощи контейнера. Контейнеры представляют собой простой механизм структурирования данных. Они также поддерживают запросы к коллекциям фактов. Разработчик приложения может использовать контейнер в качестве частичного индекса, итератора или реляционного представления. Любой документ RDF может иметь неограниченное количество контейнеров. Итак, факты могут храниться в виде простого набора триплетов или сложного графа, организованного вокруг идентификаторов. Между этими полюсами находится частичная структура, задаваемая контейнером, которую можно сравнить с маршрутом, нарисованным на карте. Набор фактов называется хранилищем фактов. Сложные хранилища фактов называются базами знаний, подобно тому, как хранилище данных называется базой данных. Простые документы RDF являются хранилищами фактов; документы, включающие схему RDF, являются базами знаний. 11.3.4 Факты о фактахФакты могут описывать другие факты. В некоторых особых ситуациях это следует иметь в виду, но в большинстве случаев полезнее игнорировать такую возможность. Некоторые базовые сведения о фактах, описывающих факты, приведены в этом разделе. Факты, зафиксированные в примере с мальчиком и собакой, неявно подразумевают множество других фактов, которые могут быть выражены в явном виде. Некоторые из них следуют из устройства нашей маленькой коллекции фактов, другие истинны почти автоматически. Все следующие примеры основаны на единственном факте: <- 1, имя, Том -> Одна из групп дополнительных фактов, следующих из устройства коллекции, - информация о типах. Программист, разрабатывающий коллекцию фактов, может решить хранить в ней типизированные данные. Например, следствием единственного факта, указанного выше, могут быть следующие факты: <- 1, тип, integer -> <- Том, тип, string -> Эти факты указывают типы для субъекта и объекта ранее приведенного факта. Они содержат дополнительную информацию о другом факте и являются аналогом словаря данных или схемы базы данных. Однако, в отличие от баз данных, информация о структуре которых хранится отдельно от самих данных, факты о фактах ничем не отличаются от "обычных" фактов и могут храниться вместе с ними. Эти факты могут использоваться, например, приложением на платформе Mozilla для моделирования данных. Здесь уместно повторить сказанное в начале этой главы. Многие специалисты называют информацию такого рода метаданными. Предполагается, что этот термин позволяет разграничить информацию (в данном случае - содержание web-документа, на который указывает URL) и "информацию об информации" (описание документа и самого URL), которая и называется метаданными. На практике, если программист пишет код для работы с файлом закладок, единственной интересной для него информацией являются так называемые метаданные - содержание этого файла. С его точки зрения метаданные оказываются данными, с которыми он должен работать. То, что для одного человека является метаданными, для другого - просто данные. Таким образом, при изучении RDF концепция метаданных может лишь запутать и без того сложную тему. Говоря коротко, термин "метаданные" часто используется без необходимости. С точки зрения программиста единственным элементом RDF, который заслуживает звания метаданных, является информация о типах. Все остальное следует рассматривать как простые данные или, точнее, простые факты. С точки зрения самого формата RDF нет какой-то отдельной категории фактов, имеющих статус "метафактов". Следующие три факта являются истинными автоматически: <- пример-факта, субъект, 1 -> <- пример-факта, предикат, имя -> <- пример-факта, объект, Том -> Здесь пример-факта означает факт, приведенный в начале этого раздела. Первый из трех фактов (с предикатом субъект) утверждает, что субъектом исходного факта является 1. Согласно второму факту, предикатом исходного факта является имя. Иными словами, все это факты об исходном факте. Процесс построения таких фактов называется реификация3). В данном контексте этот термин означает примерно следующее - что высказывания на языке (факты) становятся "вещами", о которых можно вести речь на этом языке (формулировать факты о них). Реификация сходна с извлечением метаданных, однако потенциально ведет к гораздо более запутанным следствиям. Рассмотрим, например, следующую проблему. Как было сказано выше, все существующие (зафиксированные) факты считаются истинными, а все прочие - ложными. Можем ли мы утверждать, что исходный факт (пример-факта) имеет субъект, если не сформулирован первый из фактов реификации? Поскольку факт о субъекте исходного факта отсутствует, ответ должен быть отрицательным. Однако исходный факт существует, и наличие субъекта следует из его структуры. Итак, мы пришли к противоречию - мнимому, поскольку в нашем рассуждении есть изъяны. Однако в любом случае размышления в этом направлении вряд ли представляют ценность для практически мыслящего разработчика. Немного пользы и в размышлениях о том, можно ли подвергнуть реификации сами факты реификации. Возможная область практического использования таких фактов ограничена приложениями Mozilla/RDF для анализа текстов или работы с естественным языком. Еще одна группа фактов, которые можно сформулировать на основе существующих фактов, связана с именами. Разработчик, формирующий группу фактов, может пожелать дать имена элементам этих фактов. Используя все тот же пример, можно присвоить имена субъекту или объекту, подобно тому, как даются имена полям записи в базе данных, или король жалует дворянские титулы своим подданным: <- 1, имя, идентификатор-лица-> <- Том, имя, имя-лица-> <- пример-факта, имя, определение-лица-> Эта процедура тоже создает возможности для путаницы. Исходный факт утверждает, что существует лицо по имени Том. Однако согласно первому из приведенных здесь фактов, строка "Том" имеет имя (тип) имя-лица, а исходный факт в целом - "существует лицо по имени Том" - имеет имя определение-лица. Итак, имя Тома - "Том", но оно, в свою очередь имеет имя имя-лица. Все эти тонкости не имеют практического значения для большинства разработчиков. Наконец, следует отметить, что большинство аспектов многих подходов к моделированию данных могут быть выражены при помощи фактов с предикатами. Например, при помощи следующих предикатов можно формулировать факты, описывающие объектно-ориентированную модель: является-подклассом имеет использует является-экземпляром А этот набор предикатов может использоваться для описания реляционной модели: имеет-ключ имеет-внешний-ключ один-ко-многим один-к-одному имеет-необязательный С помощью подобных предикатов можно надстраивать сложные слои семантики (например, объектную модель) над базовой системой простых фактов. Однако это сложный процесс, с которым вряд ли справится начинающий разработчик. Некоторые возможности такого рода предусмотрены в самом языке RDF, однако при решении обычных задач стоит избегать их использования. Факты с подобными предикатами могут выглядеть как метаданные, однако в последних "является- подклассом" отношения должны быть выражены объектом, а не предикатом. Корректный пример метаданных - "стрелка-UML-5 имеет- свойство является-подклассом", а не "сущность-UML-3 является-подклассом сущность-UML-2". Последний вариант представляет собой сложное, многослойное решение, которое может привести к большим трудностям. Наконец, новые факты могут быть выведены из существующих. В примере с мальчиком и собакой следующий факт может рассматриваться как следствие сформулированных фактов: <- Том, играет-с, Спот-> Следует ли рассматривать его как следствие, зависит от правил вывода и других допущений, принятых в конкретной системе. В конце концов, если мальчик и собака играют с одним и тем же мячом, они, вероятно, играют друг с другом. Вывод таких фактов является функцией дедуктивных систем. Mozilla не выполняет дедукции из фактов, записанных на языке RDF. Факты, собранные вместе для обработки, содержатся в хранилище фактов. Последнее является аналогом базы данных применительно к фактам и, как правило, находится в оперативной памяти, а не на диске. Подводя итоги этого введения, отметим, что триплеты с предикатом представляют собой полезное подмножество простых кортежей. Такие триплеты используются для выражения фактов. RDF-документы содержат факты. Факты представляют собой высказывания, а не просто данные. Сформулированные факты считаются истинными. Существуют сложные аспекты работы с фактами, но их практическая полезность ограничена. Использование фактов в качестве информации о другой именованной информации, не имеющей характера фактов (например, URL), не должно представлять сложности. Использование фактов в качестве информации о других фактах лучше оставить до тех пор, пока не освоены другие, более простые применения RDF. 11.3.5 Запросы, фильтры и определенные фактыХранилище фактов не имеет практического смысла, если нет возможности извлекать из него факты. Разработчику необходим способ получать нужные факты, игнорируя остальные. По документам RDF, как и по любым другим документам XML, можно перемещаться "вручную" или обращаться к ним с запросами. Универсальный способ перемещения по документам XML основан на использовании объектной модели документа (DOM). Возможные способы запроса - использование методов поиска, таких как getElementById(), или более сложных технологий, таких как XML Query или XPath. Однако ни один из этих способов не используется при работе с документами RDF. Вместо этого документы RDF читаются или создаются как потоки фактов. Любой разработчик предпочел бы получить лишь информацию, нужную ему, а не любую возможную информацию. В контексте RDF "нужная информация" означает "нужные факты". Чтобы ограничить получаемый поток фактов, используется процесс сопоставления с образцом, отбрасывающий ненужные факты. По сути, этот процесс представляет собой разновидность запроса или пропускания потока данных через фильтр, как в случае SQL или grep(1). Системы запросов не рассматриваются подробно в этой главе, однако они основаны на концепции определенного факта. Определенный факт (иногда называемый конкретным фактом), представляет собой полностью известный факт. Все факты, обсуждавшиеся в этой главе до настоящего момента, были определенными фактами. В качестве примера рассмотрим следующее высказывание: "Том - хозяин Спота". Мы можем установить субъект (Том), объект (Спот) и предикат (хозяин). Нам известно все об этом высказывании, поэтому его следует признать определенным. Мы легко можем записать и соответствующий определенный факт: <- Том, хозяин, Спот -> Мы можем сформулировать и другое высказывание: "Том владеет собакой". Эквивалентный факт можно записать как: <- Том, хозяин, собака -> Однако если принять во внимание, что в мире существует множество собак, нужно сделать вывод, что данное высказывание не позволяет ответить на вопрос "Какой собакой владеет Том?" В этом случае высказывание "Том владеет собакой" является неопределенным, поскольку оно не позволяет однозначно установить объект (конкретную собаку). Адвокат мог бы сказать: "Это утверждение необоснованно, поскольку вы не можете указать конкретную собаку, которой владеет Том". Таким способом он подчеркнул бы, что ваше высказывание слишком туманно, чтобы быть истинным. Лучший факт, который мы можем записать в такой ситуации, имеет следующий вид: <- Том, хозяин, ??? -> Знаки вопроса не являются какой-либо специальной синтаксической конструкцией, они лишь указывают на неопределенный объект. Вы вряд ли сможете сделать что-либо с таким неопределенным фактом, представляющим собой противоположность определенному. Однако если компьютер, в отличие от вас, знает, какая собака принадлежит Тому, вы можете передать неполный факт компьютеру в качестве запроса. Компьютер, исполняя соответствующую программу, может сопоставить неполный факт (называемый целью) со всеми зафиксированными фактами и возвратить лишь те факты, которые согласуются с ним. Этот процесс называется унификацией, в реализации Mozilla он представляет собой простое сопоставление с образцом. Таким образом вы найдете всех собак, принадлежащих Тому, или всех животных, принадлежащих Тому, или вообще все, что принадлежит Тому. То, что вы получите в ответ, зависит от того, какие факты содержатся в хранилище фактов. В любом случае, системы запросов и фильтрации Mozilla выполнят необходимые действия. Разработчик осуществляет поиск или фильтрацию определенных фактов RDF при помощи факта или фактов, которые не являются определенными и называются целью. С помощью RDF можно выражать как определенные, так и неопределенные факты, однако на практике неопределенные факты используются редко и, как правило, являются признаком ошибок проектирования. Для поддержки целей необходимы функции, специфичные для Mozilla. Подводя итоги, отметим, что факты могут храниться подобно данным и извлекаться при помощи системы сопоставления цели с определенными данными. 11.4 Синтаксис RDFСинтаксис RDF основан на нескольких стандартах и других документах. Разумеется, наиболее важными из них являются стандарты (спецификации), относящиеся собственно к RDF. Эта группа стандартов Консорциума W3C состоит из двух основных частей и разрабатывалась в два этапа. На первом этапе стандартизации RDF, имевшем место в 1999-2000 гг., были разработаны два основных документа: http://www.w3.org/TR/1999/REC-rdf-syntax-19990222. "Окончательная рекомендация по модели и синтаксису RDF 1.0". Под моделью понимается концептуальная модель, лежащая в основе языка. http://www.w3.org/TR/2000/CR-rdf-schema-20000327. Этот документ разрабатывался в течение нескольких лет. Он определяет схему RDF (RDF Schema) - способ задания словаря для документов RDF. Такой словарь задает допустимые теги и атрибуты, их сочетания и, в конечном счете, семантику документов. Схема RDF отличается от схемы XML (XML Schema). Второй этап стандартизации RDF состоял в расширении и завершении существующих документов. Новые версии документов были окончательно приняты в 2009г.: http://www.w3.org/TR/rdf-syntax-grammar/, "Спецификация синтаксиса RDF/XML (пересмотренная)", представляет собой обновленный вариант первого из двух документов, перечисленных выше. http://www.w3.org/TR/rdf-schema/, "Язык описания словаря RDF 1.0: RDF Schema", - развитие второго документа. Существует также ряд пояснительных документов, посвященных различным аспектам RDF и доступных на сайте Консорциума W3C: http://www.w3.org/. Из перечисленных спецификаций Mozilla практически полностью реализует первый документ (рекомендацию 1999 г.) и некоторые новые возможности, введенные третьим документом (пересмотренной рекомендацией). Другие стандарты, тесно связанные с RDF, - спецификации, относящиеся к пространствам имен XML и схемам XML. Mozilla поддерживает схемы XML, однако эта функциональность никак не используется при обработке RDF. Некоторая поддержка RDF встроена непосредственно в XUL. Эти стандарты предлагают способ описания фактов при помощи тегов XML. Субъекты и объекты фактов могут быть представлены атрибутами тегов или (в случае объектов) текстовыми узлами, заключенными в теги. Однако стандарты определяют лишь небольшое количество конкретных тегов. Предполагается, что дополнительные теги и атрибуты определяются разработчиком конкретного приложения. Эти дополнительные имена образуют словарь, который может быть формально описан в документе RDF или XML Schema или. Существуют широко известные словари, снабженные спецификациями и пояснениями для облегчения их использования. Наиболее известным словарем является Dublin Core ("Дублинское ядро"), содержащий ключевые слова для описания источников информации. Этот словарь используется, главным образом, для составления каталогов библиотек и архивов и содержит такие предикаты, как, например, "Title" (название) и "Author" (автор). Mozilla не использует Dublin Core в качестве словаря и не поддерживает использование схем XML для определения словаря. Вместо этого поддержка нескольких словарей встроена непосредственно в платформу. Система обработки RDF позволяет разработчику использовать в документах любые имена без какого-либо формального определения. Поэтому имена предикатов можно вводить "на лету", подобно именам переменных JavaScript. 11.4.1 Основные концепции синтаксисаДокумент RDF представляет собой документ XML, а сам RDF является приложением XML. Платформа Mozilla использует для RDF следующее пространство имен: http://www.w3.org/1999/02/22-rdf-syntax-ns# Файлы с документами RDF должны иметь расширение .rdf. Mozilla поддерживает следующие типы MIME для документов RDF: text/rdf text/xml Однако версия 1.4 еще не поддерживает официального типа MIME для документов RDF, установленного документом RFC 3023: application/rdf+xml 11.4.1.1 ТегиОсновная цель RDF - предоставить синтаксис для описания фактов. XML предоставляет различные возможности для выражения фактов. Некоторые гипотетические варианты показаны в листинге 11.6. <факт субъект="..." предикат="..." объект="..."/> <факт> <субъект .../> <предикат .../> <объект .../> </факт> < субъект ... предикат="..." объект="..."/>Листинг 11.6. Возможные варианты синтаксиса XML для описания фактов. Однако в RDF не используется ни один из этих вариантов. Синтаксис RDF имеет следующую форму: <факт субъект="..."> <предикат>объект</предикат> </факт> Эта запись отражает лишь общую концепцию синтаксиса RDF. Ниже приведено синтаксически корректное описание факта на языке RDF: <Description about="http://www.mozilla.org/"> <NC:LastVisited>10 января 2004</NC:LastVisited> </Description> Такой синтаксис допускает вложение одних фактов в другие. Он может служить основой для нескольких видов сокращенной записи и сходен с некоторыми web-технологиями. К сожалению, терминология RDF представляет серьезную трудность для начинающего пользователя. Она не использует таких терминов как "субъект" или "предикат" и вообще основана скорее на некоторых частных идеях, чем на общей концепции фактов, изложенной в этой главе. Это делает RDF весьма сложным для освоения. При разработке RDF его авторы стремились сделать синтаксис языка сходным с существующими web-технологиями, поскольку RDF был задуман как средство описания web-ресурсов. Вместо субъекта, отношение которого к объекту описывается предикатом, терминология RDF говорит о ресурсах, обладающих свойствами, которым, в свою очередь, присваиваются значения. С одной стороны, это может облегчить освоение RDF для некоторых разработчиков. С другой стороны, RDF, по сути, является средством работы с любыми фактами, и никакой выбор синтаксиса не может изменить этого, хотя и может дезориентировать разработчика. В таблице 11.2 терминология, используемая для описания фактов, сопоставлена с терминами RDF.
На практике полезно комбинировать оба подхода. С общей точки зрения, RDF представляет собой средство работы с фактами, и с ним целесообразно работать, имея в виду соответствующую концептуальную модель. В конкретных ситуациях, например, когда небольшой набор фактов образует компактное дерево, взгляд на него как на иерархию ресурсов и свойств может оказаться более продуктивным. Поскольку многие документы RDF невелики или сильно структурированы, этот подход часто оказывается эффективными. В качестве примера рассмотрим уже встречавшийся нам простой тег <Description>.4) В модели фактов он интерпретируется следующим образом. Тег <Description> определяет субъект факта (на который указывает атрибут about этого тега). Если тег имеет содержимое, оно представляет прочие термы данного факта и, возможно, вложенные факты. В приведенном выше примере тег <NC:LastVisited> представляет собой предикат, а его содержимое, простая строка "10 января 2004", - объект. В терминологии RDF Та же конструкция интерпретируется иначе. Тег <Description> определяет ресурс. Этот ресурс может иметь свойства, выраженные другими тегами. Тег <NC:LastVisited> - одно из таких свойств, значением которого является "10 января 2004". Терминология RDF удобна тем, что большинство имен предикатов, используемых в Mozilla, похожи скорее на свойства. Хотя color (цвет), как и любое другое слово, может использоваться в качестве предиката, оно напоминает скорее свойство DOM или CSS, а не отношение, выражаемое предикатом. В любом случае, применительно к RDF термины предикат и свойство являются полностью взаимозаменяемыми. Вот полный список основных тегов RDF: <RDF> <Description> <Seq> <Bag> <Alt> <li> Последние четыре тега являются избыточными - эквивалентные им конструкции могут быть выражены при помощи тега <Description> - так что RDF имеет очень ограниченный набор тегов. Хотя теги для выражения предикатов выбираются исходя из потребностей конкретного приложения, в RDF предусмотрено несколько таких тегов, а именно: <Statement> <subject> <predicate> <object> Эти теги предназначены для реификации фактов. <Statement> используется для реификации самого факта5), а остальные три тега - для каждого из трех термов триплета. Ни один из этих четырех тегов не поддерживается Mozilla. 11.4.1.2 Контейнеры.RDF поддерживает контейнеры - способ организации однотипных фактов. Контейнер состоит из обрамляющего тега <Bag>, <Seq> или <Alt>, а также тегов <li>, в которые заключаются элементы контейнера. Контейнер вместе со своим содержимым образует коллекцию. Эта коллекция может быть помещена вместо объекта какого-либо факта. Контейнер выглядит следующим образом: <Description>
<Bag>
<li>объект 1</li>
<li>объект 2</li>
<li>объект 3</li>
</Bag>
</Description>
В обычном факте между объектом и субъектом (или между ресурсом и значением свойства) существует отношение "один к одному". У каждого объекта есть один субъект. В случае контейнеров отношение между фактом и объектом имеет вид "один ко многим", причем минимально возможное число объектов у субъекта равно нулю. Контейнеры RDF являются аналогом списков или массивов в других языках. То, каким образом должны обрабатываться контейнеры, зависит от конкретного приложения. Одно из возможных применений контейнера - поддержка списка свободных мест в системе заказа билетов. Каждое место является ресурсом; в системе должно быть отражено состояние всех мест - как свободных, так и зарезервированных. Список свободных мест может быть организован отдельно от фактов о состоянии конкретных мест при помощи контейнера. Соответствующий фрагмент RDF приведен в листинге 11.7. <Description>
<Description id="место:A1">
<крайнее>true</крайнее>
</Description>
<Description id="место:A2">
<зарезервировано>Тим</зарезервировано>
<крайнее>false</крайнее>
</Description>
<Description id=" место:A3">
<крайнее>false</крайнее>
</Description>
<Description id=" место:свободные">
<Bag>
<li resource="место:A1"/>
<li resource="место:A3"/>
</Bag>
</Description>
Листинг
11.7.
Два факта, выраженных при помощи одного тега RDFВ этом фрагменте для каждого места указано, является ли оно крайним (у прохода) и в том случае, если место не свободно, имя того, кто его зарезервировал. Синтаксис место: относится к воображаемой схеме URL, разработанной для конкретного приложения. Пока зарезервировано только место A2. Контейнер <Bag> содержит ссылки на два свободных места. Синтаксис тегов <li> в этом примере - один из способов сокращения, допустимых языком RDF. Таким образом, контейнеры могут использоваться для того, чтобы предоставить программисту доступ к подмножествам фактов. Элементы контейнера указывают на субъекты подмножества какого-либо множества фактов, описанных за пределами контейнера. Просматривая контейнер, можно получить доступ к этим фактам. Контейнеры могут рассматриваться как простая структура данных для фактов и как простой механизм навигации. В системе заказа билетов программист может зарезервировать место, выбрав его из контейнера со свободными местами, добавив вложенный тег (предикат) <зарезервировано> к соответствующему тегу <Description>, а затем удалив место из контейнера. В объектно-ориентированной терминологии контейнер "использует" объекты - члены коллекции. Контейнер содержит лишь ссылки на них, а не сами объекты. Теги-контейнеры и соответствующие коллекции всегда могут быть заменены эквивалентной конструкцией из простых фактов. Об этом рассказано в описании отдельных тегов. 11.4.1.3 Идентификаторы.В примере с мальчиком и собакой мы стремились снабдить каждый элемент, моделируемый при помощи фактов, идентификатором. В отличие от многих других приложений XML, в RDF идентификаторы играют особую роль. Они могут использоваться двумя способами. Первый способ использования идентификаторов - обозначение целого факта. Для этого к тегу, выражающему данный факт, добавляется атрибут id. URL документа RDF, дополненный символом # и значением атрибута id какого-либо факта из данного документа, является уникальным идентификатором факта в глобальном масштабе. Согласно документу RFC 2369, URL такого вида указывает на фрагмент документа, а не на ресурс в целом. Однако в RDF ресурсом считается именно отдельный факт, даже если он является частью большего документа. Поэтому документ RDF может рассматриваться как группа или коллекция ресурсов. Этот подход значительно отличается от принятого в HTML, где теги <A> без атрибута HREF, на которые ссылается часть URL после символа #, маркируют лишь определенное место в едином документе-ресурсе. Вот пример идентификатора RDF: <Description ID="printEnabled" ... /> Возможно, этот файл содержит информацию о состоянии подсистемы печати, и атрибут ID позволяет обратиться к конкретному факту, используя осмысленное имя. Второй способ использования идентификаторов в RDF - замена локальных литералов, используемых в документе RDF. Так, в листинге 11.5 фрагмент информации "теннис", указывающий на тип мяча, хранится непосредственно внутри соответствующего факта. Однако такая непосредственность не обязательно должна иметь место. Так, на том же листинге записано несколько фактов о Томе. При этом сам Том - реальный мальчик - не присутствует в этих фактах непосредственно. Вместо этого мы используем число (1), имея в виду, что в данной группе фактов оно представляет Тома. RDF предлагает лучший идентификатор для Тома, чем простое число, - URL. В документе RDF этот URL будет представлять Тома точно так же, как и число 1 в нашем примере. Возможно, это будет адрес электронной почты (mailto:) или URL web-документа, содержащего запись о Томе. Любой факт, субъектом которого является строка, совпадающая с этим URL, является фактом о Томе. В терминологии web-разработчика Том является ресурсом, на который указывает URL. Однако RDF идет дальше в этом направлении. URL может быть идентификатором не только субъекта, но и объекта. И собака Тома, и его мяч имеют собственные URL (в примере в листинге - числовые идентификаторы). Примечательно, что RDF позволяет выразить с помощью URL и предикат/свойство факта. URL предиката рассматривается как ссылка на ресурс, в котором описан данный предикат. URL является идентификатором предиката, он замещает фактический предикат, который может находиться на сайте какого-либо учреждения или организации по стандартизации или, например, на корпоративном сервере. Фактически RDF позволяет описать предикат при помощи атрибута id, значением которого должен быть корректный URL. Для удобства чтения URL предиката как правило содержит слово, поясняющее его общий смысл, например www.example.com/#Owner (владелец). Таким образом, при необходимости факты можно выражать при помощи одних лишь идентификаторов-URL. Фактически такие идентификаторы являются указателями на термы, из которых составлены факты. Такие документы RDF являются одним из источников трудностей для начинающих пользователей, которым кажется, что документ должен автоматически взаимодействовать с уделенными ресурсами, на которые указывают URL. Это не так - URL в данном случае ничем, кроме своей структуры, не отличается от простой строки, которая могла бы содержать обычный почтовый адрес. Спецификация RDF не требует автоматического обращения к ресурсам Internet для обработки такого документа, хотя разработчик конкретного приложения может добавить такую функцию. Mozilla не содержит подобной функциональности и при обработке RDF-документов не обращается к URL-идентификаторам. URL в данном случае рассматриваются как простые данные, которые должны лишь однозначно идентифицировать термы фактов. Здесь, однако, существует одна сложность. Любой URL в документе RDF может указывать на другой RDF-файл. Таким образом, факты из разных документов могут ссылаться друг на друга. Это плохая практика для большинства приложений, поскольку в результате может возникнуть запутанный клубок зависимостей между файлами. В некоторых специальных случаях, например при реализации протоколов аутентификации, такая практика может быть оправданной. Кроме того, факты в одном документе могут содержать URL, указывающие на метаданные или элементы схемы, описанные в другом файле. В таких ситуациях ссылки между документами RDF могут иметь смысл, но лучше не злоупотреблять ими. Строго говоря, идентификаторы, заменяющие термы факта, могут иметь более общий синтаксис - URI (универсальный указатель ресурса). Синтаксис URI охватывает как URL, так и URN (универсальное имя ресурса). Возможные применения имен URN в качестве идентификаторов обсуждаются ниже в этой главе. RDF допускает наличие фактов, у которых тег <Description> или контейнер не имеют идентификатора. Это факты с неопределенным субъектом или анонимные факты. Документ RDF, не имеющий анонимных фактов, считается определенным. Для нормальной работы с запросами рекомендуется использовать только определенные документы. Поэтому не следует оставлять теги-контейнеры и <Description> без идентификаторов. 11.4.2 <RDF>Тег <RDF> является корневым элементом всего документа RDF, его наличие обязательно. Поскольку документы RDF, как правило, содержат теги из нескольких пространств имен, традиционно в этом теге определяется префикс для пространства имен RDF <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"> Для этого тега не определено никаких специальных атрибутов. В нем могут встречаться лишь декларации пространств имен XML, добавляющие словари (дополнительные наборы тегов) для использования в документе. Эти декларации играют ту же роль, что и указание DTD (определение типа документа) в документе HTML. В таблице 11.3 перечислены все пространства имен, которые используются в RDF-документах платформы Mozilla.
За исключением первой строки таблицы, ни одному из указанных URL не соответствует реальный документ. URL, содержащие "netscape", являются наследием Netscape Communicator 4.x. Префиксы представляют собой рекомендации, основанные на существующих соглашениях. Из перечисленных префиксов в различных компонентах Mozilla наиболее широко используются web, chrome и nc. Чтобы использовать пространство имен, нужно знать ключевые слова (теги), предоставляемые этим пространством. Эти ключевые слова обсуждаются ниже в разделе "Теги предикатов". Разработчик приложений может добавлять к RDF-документам любые другие пространства имен, включая в документ дополнительные декларации xmlns. Содержимым тега <RDF> являются теги-потомки. Его непосредственными потомками могут быть тег <Description> и теги- контейнеры <Seq> <Bag> <Alt>. 11.4.3 <Description>Тег <Description> является основой всего языка RDF. Этот тег представляет один или несколько фактов и может содержать любое количество тегов-потомков, в том числе ни одного. Каждый тег-потомок является предикатом (свойством RDF). Каждый тег-потомок выражает один факт, субъект которого указан в теге <Description>. В листинге 11.8 представлены два факта, выраженные с помощью одного тега <Description>. <факт субъект="..."> <свойство1 ...>объект1</свойство1> <свойство2 ...>объект2</свойство2> </факт>Листинг 11.8. Два факта, определенные с помощью одного тега RDF <Description> Этот фрагмент записан на псевдокоде, а не на синтаксически корректном RDF. Вместо термина предикат мы использовали свойство, поскольку эти термины взаимозаменяемы. Из этого примера видно, почему в терминологии RDF говорят о свойствах - факт здесь определяет два свойства субъекта. Более строгое утверждение состоит в том, что перед нами сокращенная запись двух различных фактов с одним и тем же субъектом. В RDF роль тега <fact> из этого примера играет тег <Description>, который по сути является контейнером. Он, однако, отличается от прочих контейнеров RDF тем, что не имеет никакой специальной семантики и содержит пары предикат/свойство, а не субъекты или объекты. Тег <Description> имеет следующие специальные атрибуты. ID about type Каждый тег <Description> должен иметь атрибут ID или атрибут about. Если тег не имеет ни одного из этих атрибутов, считается, что соответствующий факт имеет анонимный субъект. Этот субъект для внешнего мира невидим (для него невозможно определить уникальный URL), а в рамках данного документа он считается неопределенным термом. Считается, что атрибут ID имеет имя, которое совпадает с его значением. Это имя можно добавить к URL документа RDF, чтобы получить уникальный URL для факта как целого. Одновременно этот же URL рассматривается как URL субъекта данного факта. Использование атрибута ID тега <Description> имеет смысл в том случае, если у этого тега есть ровно одно свойство. Субъект факта, определенного с использованием атрибута ID, доступен для внешнего мира (как и в предыдущем абзаце, речь идет не о физической доступности документа, а о возможности адресации факта и его субъекта). Атрибут about определяет субъект факта. Его значением должен быть полный URL. Если атрибут about используется вместо атрибута ID, факт как целое не имеет собственного URL и недоступен из внешнего мира. Атрибут type указывает тип объекта факта (в терминологии RDF - значения свойства ресурса). Как правило, объектом/значением является содержимое XML, заключенное в открывающий и закрывающий теги элемента- свойства. Атрибут type указывает, какого рода этот объект. Если этот атрибут присутствует, его значение должно быть корректным URI. Mozilla никак не обрабатывает атрибут type в документах RDF; он не связан ни с какой схемой данных. Следует заметить, что атрибут type вместе со своим значением фактически образует пару свойство-значение (предикат- объект). Как мы увидим ниже, в RDF определен тег-предикат type; атрибут type может рассматриваться как сокращенная запись этого предиката. Mozilla не поддерживает следующие специальные атрибуты тега <Description>: aboutEach aboutEachItem bagID Два первых атрибута не рекомендованы к применению последними версиями спецификации RDF. Атрибут bagID используется для реификации фактов; Mozilla не поддерживает эту функциональность. 11.4.3.1 Сокращенная нотацияТег <Description> и его содержимое могут быть записаны как единственный тег <Description> без всякого содержимого. Это можно сделать, записав предикат и объект как атрибут XML тега <Description> и значение этого атрибута соответственно. Следующий фрагмент RDF выражает единственный факт, свидетельствующий о том, что Спот принадлежит Тому: <Description about="www.test.com/#Том"> <ns:Владелец>Спот</ns:Владелец > </Description> В данном случае субъект и предикат представлены с помощью URL; объект представлен с помощью литерала. Предикат принадлежит пространству имен XML с префиксом ns. Это пространство было декларировано в начале документа, поэтому полный URL предиката нельзя установить на основании одного лишь данного фрагмента. Сокращенная запись того же фрагмента выглядит следующим образом: <Description about="www.test.com/#Том" ns:Владелец="Спот"/> Обратите внимание на префикс пространства имен перед атрибутом. Эта возможность предусмотрена спецификацией XML, но не слишком часто используется на практике. Сокращенная запись допустима лишь в том случае, когда объект/значение является литералом, а не URI. 11.4.4 Теги предикатов/свойствПредикаты или свойства определяются разработчиком конкретного приложения. Лучше всего найти уже разработанный набор тегов, подходящий для конкретной цели. Разумеется, можно придумывать и собственные теги в процессе разработки. Однако использование корректно определенного пространства имен является признаком культуры разработчика и того, что он продумал назначение своих данных, представляемых в формате RDF. RDF определяет атрибуты XML, которые можно добавлять к тегам свойств. Эти атрибуты влияют на любой тег-свойство, к которому они добавлены, подобно тому, как добавление атрибута observes превращает любой тег в элемент-наблюдатель. Доступны следующие специальные атрибуты: ID parseType Атрибут ID имеет то же назначение, что и в теге <Description>. Если родительский тег <Description> содержит более чем один тег-предикат (т.е. представляет несколько фактов), атрибут ID может быть добавлен к тегам-предикатам, чтобы однозначно идентифицировать отдельные факты. Атрибут parseType является указанием для синтаксического анализатора RDF. Он отличается от предиката type, обсуждаемого в следующем разделе, и указывает, каким образом должна интерпретироваться текстовая строка, представляющая значение/объект. Атрибут parseType может принимать следующие значения: Literal Resource Integer Date Два первых значения предусмотрены спецификацией RDF. Literal - значение атрибута по умолчанию, оно подразумевает, что значение является произвольной строкой. Resource означает, что строка значения представляет URI. Значения Integer и Date являются дополнениями Mozilla и указывают, что строка должна интерпретироваться как 32-битное целое со знаком и как дата соответственно. Предполагается, что дата может быть в любом из нескольких форматов, однако не все из них поддержаны полностью. Самый надежный вариант - использовать формат UTC, выдаваемый командой UNIX date(1), но в полученной строке заменить "UTC" на "UT" или "GMT". Значение атрибута Date не должно содержать символов Unicode, выходящих за пределы набора ASCII. 11.4.4.1 Существующие предикатыВ RDF определен предикат type, соответствующий атрибуту type тега <Description>. Использование этого атрибута является сокращенным вариантом следующей записи: <rdf:type>value</rdf:type> В данном случае rdf является префиксом пространства имен RDF. Предикат type может применяться к субъектам любых фактов. Такое использование позволяет расширить базовую систему типов RDF с помощью либо фактов, определенных приложением, либо схемы RDF (RDF Schema), если приложение поддерживает такую функциональность. В приложениях на основе Mozilla эти возможности используются редко. Пространства имен, перечисленные в таблице 11.3, также обеспечивают дополнительные наборы предикатов. Поскольку предикаты, по сути, являются элементами данных, сами по себе эти имена ничего не "делают". В главе 9 "Команды" было сказано, что платформа Mozilla определяет множество команд, но все они связаны с тем или иным приложением - Навигатором, Компоновщиком или почтовым клиентом. То же самое справедливо и для предикатов. В файлах RDF, создаваемых Mozilla, используется множество предикатов, но все они связаны с конкретными фрагментами прикладного кода. Полного списка этих предикатов не существует ни в документации, ни даже в исходном коде. Чтобы ввести новый предикат, разработчику достаточно добавить его в файл RDF, а его обработку - к исходному коду. Поэтому поиск предикатов, используемых Mozilla - задача для самостоятельного исследования. Некоторые примеры таких предикатов приведены в главе 12 "Оверлеи и chrome". Вновь создаваемое приложение на платформе Mozilla должно иметь формально описанную модель данных и/или словарь, перечисляющий возможные предикаты. Разработчик может использовать существующие предикаты Mozilla в качестве образца или отправной точки для составления собственного словаря, но ему нет необходимости задействовать уже существующие имена. Существующим схемам данных нужно строго следовать лишь в том случае, когда приложение должно создавать или изменять файлы RDF в уже существующих форматах. Для знакомства с этими форматами можно изучить существующие файлы, созданные классическим браузером или другими приложениями Mozilla. Более сложный, но и более надежный способ - изучение исходного кода этих приложений. 11.4.4.2 Сокращенная нотацияТеги-предикаты могут иметь атрибут resource. Он аналогичен атрибуту about тега <Description>, но указывает на объект факта (значение свойства). При использовании атрибута resource тег-предикат может не иметь содержимого XML, а значением атрибута resource должен быть не литерал, а корректный URI, указывающий на объект. Полная форма записи может быть, например, такой: <ns:Владелец parseType="Resource">www.test.com/#Spot</ns:Владелец> Тогда ее сокращенная форма имеет следующий вид: <ns:Владелец rdf:resource="www.test.com/#Spot"/> Это применение атрибута resource не представляет трудностей для понимания. Однако данный атрибут имеет и более сложное применение. В простом случае, рассмотренном только что, значение атрибута resource участвует лишь в одном факте, на объект которого оно указывает. Однако этот же объект может быть субъектом другого факта. В данном случае применимо следующее весьма запутанное правило: если в теге-предикате встречается атрибут resource, а также другие пары атрибут-значение, эти пары интерпретируются так же, как если бы они принадлежали тегу <Description>, субъектом которого (значением атрибута about) был бы URI, являющийся значением атрибута resource тега-предиката. Иными словами, внутри тега-предиката одного факта могут быть определены другие, вложенные факты, причем объект объемлющего факта является субъектом вложенных фактов. Все это весьма сложно и запутанно, и не стоит тратить усилий на изучение всех тонкостей, если только вы не разрабатываете сложное и амбициозное приложение. Этот вариант сокращенной записи был предложен для того, чтобы уменьшить количество вложенных тегов в документе RDF. Предполагается, что его использование делает документ более удобным для восприятия, но это утверждение представляется спорным. Более подробная информация о различных вариантах сокращенной записи RDF содержится в разделе 2.2.2 описания синтаксиса RDF (спецификация 1999 г.). 11.4.5 Теги <Seq>, <Bag>, <Alt> и <li><Seq>, <Bag> и <Alt> - три тега-контейнера RDF. <Seq> представляет собой последовательность6) элементов или упорядоченный список. Предполагается, что элементы, находящиеся в этом контейнере, упорядочены. Этот контейнер может использоваться, в частности, для хранения информации о последовательности событий, например, списка недавно выполненных команд. <Bag> представляет собой простую коллекцию элементов без каких-либо ограничений на ее состав. <Alt> подразумевает список альтернатив. Это простая коллекция без ограничений, однако подразумевается, что все ее элементы являются альтернативами в смысле, зависящем от конкретного приложения. Так, в контейнере <Alt> могут содержаться варианты одного и того же сообщения программы на разных языках. Эти контейнеры позволяют организовывать субъекты и объекты в группы, а также компактно записывать несколько сходных фактов. В контейнерах всех трех типов могут встречаться повторяющиеся элементы. Контейнеры содержат элементы, каждый из которых заключен в тег RDF <li>, подобно элементам списков <UL> и <OL> в языке HTML. Каждый элемент контейнера является объектом. Поскольку объект в RDF может быть представлен контейнером или тегом <Description>, контейнеры могут быть вложенными. В листинге 11.9 приведен пример простого контейнера. <Description about="www.example.com/#Том">
<ns:Владелец>
<Bag ID="Собаки">
<li>Спот</li>
<li>Фидо</li>
<li>Цербер</li>
</Bag>
</ns:Владелец>
</Description>
Листинг
11.9.
Пример контейнера RDFСмысл этой записи прозрачен: Том - владелец Спота; Том - владелец Фидо; Том - владелец Цербера. Контейнер позволяет компактно записать несколько однородных фактов. К сожалению, интерпретация самого контейнера с точки зрения фактов является несколько неуклюжей. Эквивалентный набор фактов показан в листинге 11.10. <- "www.example.com/#Том", ns:Владелец, "Собаки" -> <- "Собаки", rdf:_1, "Спот" -> <- "Собаки", rdf:_2, "Фидо" -> <- "Собаки", rdf:_3, "Цербер" ->Листинг 11.10. RDF предназначен исключительно для выражения фактов, поэтому любой контейнер должен быть представлен как набор фактов. Для этого при интерпретации RDF-файла создается специальный терм, соответствующий контейнеру как целому. С точки зрения факта, задаваемого тегом <Description>, этот терм является объектом. Кроме того, как показано в листинге, создается ряд фактов по числу элементов контейнера, в которых этот новый терм является субъектом. Объектом в каждом из них является один из элементов контейнера. Это обычные факты, устанавливающие отношение "один к одному". Все эти термы и факты добавляются к хранилищу файлов, создаваемому при чтении и интерпретации документа RDF. Однако для того, чтобы этот подход мог работать, необходимо решить две проблемы. Во-первых, новому субъекту требуется идентификатор или, по крайней мере, соответствующий ему литерал. Кроме того, у вновь создаваемых фактов, помимо субъекта и объекта, должны быть также предикаты (имена свойств). Первая проблема решается просто - создатель документа должен снабдить тег-контейнер атрибутом ID или about. В противном случае контейнер будет анонимным, а документ RDF - неопределенным. Таких документов следует избегать, поскольку шаблоны Mozilla не могут работать с ними. Вторая проблема решается в процессе интерпретации документа RDF программой. Если программа отвечает спецификации RDF, она автоматически создаст предикаты для новых фактов. Эти предикаты будут иметь имена _1, _2, _3. Поскольку эти имена относятся к пространству имен RDF, они будут иметь вид rdf:_1, rdf:_2 и т.д., при условии, что префикс rdf присвоен этому пространству имен. Таково происхождение предикатов, использованных в листинге 11.10. в листинге 11.11 представлены факты, эквивалентные записи в листинге 11.9 (т.е. порождающие в хранилище фактов ту же структуру при интерпретации документов RDF). Спецификация RDF содержит ряд схем, иллюстрирующих приведение контейнеров к "обычным" фактам, с которыми полезно познакомиться. <Description about="www.test.com/#Том"> <ns:Владелец resource="Собаки"/> </Description> <Description about="Собаки" rdf:_1="Спот"/> <Description about="Собаки" rdf:_2="Фидо"/> <Description about="Собаки" rdf:_3="Цербер/>Листинг 11.11. Факты RDF, эквивалентные контейнеру с тремя элементами. Для факта с предикатом <rdf:_1> использована сокращенная запись, поскольку объектом является литерал. Мы не можем использовать аналогичную форму записи для первого факта, поскольку его объект, "Собаки", в данном случае рассматривается как фрагмент URL, а не как литерал. Использовать или не использовать контейнеры - выбор разработчика, однако они, как правило, выглядят аккуратнее, чем эквивалентный набор тегов <Description>. Все эти факты хранятся во внутреннем представлении документа RDF отдельно, и с формальной точки зрения они не связаны между собой. Приложение не может обнаружить в листинге 11.11 одного факта, указывающего на то, что Том - хозяин Спота. Это означает, что приложение, которому может понадобиться данный факт, должно быть способно восстановить структуру графа фактов и перемещаться по нему, распознавая контейнеры, либо анализировать содержание исходного файла каким-то другим способом. Первый подход представляется значительно более эффективным. Тег-контейнер может иметь следующие атрибуты: ID type Атрибут ID аналогичен тому же атрибуту тега <Description>. Значение атрибута type не определяется автором документа. Оно автоматически устанавливается равным имени тега-контейнера (например, rdf:Bag), которое и считается типом данного тега. Эта пара атрибут-значение образует отдельный факт, субъектом которого является значение атрибутов about или ID тега-контейнера. Однако считается, что предикатом этого факта является не type, а специальное значение instanceOf. В примере с тремя собаками этот факт имеет следующий вид: <- "Собаки", http://www.w3.org/1999/02/22-rdf-syntax-ns#instanceOf, http://www.w3.org/1999/02/22-rdf-syntax-ns#Bag -> С помощью данного факта разработчик приложения может определить контейнер и установит его тип. Однако в случае Mozilla необходимости в этом, как правило, не возникает, поскольку платформа предоставляет удобные вспомогательные объекты. В тегах-контейнерах также может использоваться та же общая форма сокращенной записи "свойство = значение", что и в теге <Description>. Для тега <li> определены следующие атрибуты: parseType resource Они аналогичны соответствующим атрибутам тегов-предикатов и допускают те же формы сокращенной записи. На этом мы заканчиваем обсуждение синтаксиса RDF и переходим к примерам использования RDF в Mozilla. 11.5. Примеры RDFВ этом разделе представлено несколько примеров практического применения RDF, иллюстрирующих использование синтаксиса и концепций этого языка. 11.5.1 Менеджер загрузок: использование URLМенеджер загрузок классического браузера представляет собой наглядный пример использования документа RDF для хранения информации о ресурсах Internet. Менеджер загрузок, который доступен в Mozilla начиная с версии 1.2.1, используется для того, чтобы отслеживать процесс загрузки файлов. Его можно активизировать в разделе Навигатор | Загрузки диалогового окна настроек Mozilla (пункт меню Правка | Настройки). Интерфейс Менеджера загрузок состоит из единственного окна XUL, а данные о загрузках хранятся в файле RDF. Окно открывается при сохранении web-документа в локальной файловой системе, например, при помощи пункта меню Навигатора Файл | Сохранить как. Кроме того, Менеджер загрузок можно открыть в любой момент при помощи пункта меню Инструменты | Менеджер загрузок. Файл RDF называется downloads.rdf и находится в каталоге профиля пользователя. Код Менеджера загрузок находится в файле comm.jar в chrome. В основе графического интерфейса этого компонента лежит тег XUL <tree>. Чтобы пронаблюдать работу программы с файлом RDF, следует открыть окно Менеджера загрузок и удалить все записи, выделив их и нажав на кнопку "Удалить из списка". Откройте файл downloads.rdf в любом текстовом редакторе. Вы увидите, что файл содержит лишь декларации пространств имен и пустой контейнер <Seq>, как показано в листинге 11.12. <?xml version="1.0"?> <RDF:RDF xmlns:NC="http://home.netscape.com/NC-rdf#" xmlns:RDF="http://www.w3.org/1999/02/22-rdf-syntax-ns#" > <RDF:Seq about="NC:DownloadsRoot"> </RDF:Seq> </RDF:RDF>Листинг 11.12. "Пустой" файл downloads.rdf Затем откройте любую страницу на удаленном сервере, например www.mozilla.org. Сохраните страницу в локальном файле и, когда сохранение будет полностью завершено, перезагрузите файл downloads.rdf в текстовом редакторе. Вы увидите, что к файлу были добавлены тег <Description> с содержимым, а также элемент коллекции <Seq>. Тег <Description> содержит восемь фактов о загруженном файле. Примечательно, что эти факты записаны с помощью различных видов нотации. Субъект факта с тегом <Description> одновременно является объектом в коллекции <Seq>. Эта коллекция позволяет найти все записи о файлах, включенные в документ. Файл downloads.rdf после загрузки одного документа показан в листинге 11.13. <?xml version="1.0"?>
<RDF:RDF
xmlns:NC="http://home.netscape.com/NC-rdf#"
xmlns:RDF="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
>
<RDF:Seq about="NC:DownloadsRoot">
<RDF:li resource="C:\tmp\test_save.html"/>
</RDF:Seq>
<RDF:Description about="C:\tmp\test_save.html"
NC:Name="test_save.html"
NC:ProgressMode="none"
NC:StatusText="Finished"
NC:Transferred="1KB of 1KB">
<NC:URL resource="http://www.mozilla.org/"/>
<NC:File resource="C:\tmp\test_save.html"/>
<NC:DownloadState NC:parseType="Integer">1</NC:DownloadState>
<NC:ProgressPercent NC:parseType="Integer">100</NC:ProgressPercent>
</RDF:Description>
</RDF:RDF>
Листинг
11.13.
Файл downloads.rdf после завершения загрузки одного файла.При использовании Microsoft Windows локальные пути записываются с префиксом C: (или другим именем диска). Это расширение синтаксиса URL, используемое компанией Microsoft, поддерживается Mozilla. Такая запись эквивалентна префиксу file:///C|/ и, с точки зрения Mozilla, допустима в составе URL. Попробуйте сохранять другие страницы, наблюдая изменения в файле. Также можно, закрыв окно Менеджера загрузок, аккуратно удалить из файла один из элементов контейнера <Seq> и соответствующий тег <Description>. Затем следует вновь открыть окно и посмотреть на результат. Менеджер загрузок мог бы быть реализован без использования RDF. Этот формат был выбран для хранения данных, поскольку платформа Mozilla включает развитую поддержку работы с ним. Поэтому чтение и сохранение данных в таком формате не представляет сложности для разработчика и не требует написания большого количества кода. 11.5.2 Использование URN для простых данныхRDF может использоваться не только для хранения информации о web- ресурсах, представляемых своими URL, но и при работе с обычными данными. Какой смысл в использовании RDF для обычных данных? Инфраструктура поддержки RDF, предоставляемая платформой Mozilla, позволяет объединять данные, хранимые в документах RDF, и динамически обновлять их. Эти объединенные данные могут одновременно использоваться в разных местах приложения или даже в нескольких приложениях. Кроме того, инфраструктура платформы обеспечивает автоматический анализ синтаксиса содержимого RDF и выполнение различных операций с ним. Разработчику приложения нет необходимости самостоятельно выполнять операции низкого уровня. Наконец, RDF лежит в основе системы шаблонов Mozilla, которая обеспечивает автоматическое отображение содержимого RDF. 11.5.2.1 Сводка типов, поддерживаемых реализацией RDF на платформе MozillaВыше мы уже обсуждали некоторые типы, используемые в документах RDF. Платформа Mozilla поддерживает следующие типы: Типы литералов: Literal, Resource, Integer, Date, Blob. Тип XMLLiteral не поддерживается. Типы компонентов фактов: Property, Bag, Seq, Alt. Тип List не поддерживается. Типы фактов: тип Statement не поддерживается. Типы, используемые для реификации: типы subject, predicate и object не поддерживается. Тип Blob используется для хранения массива бинарных данных. Этот тип нельзя указать из скрипта JavaScript - это расширение Mozilla, которое может быть использовано только из кода на C/C++. Литералы типа Blob используются, в частности, в почтовом клиенте Mozilla для представления файлов, вложенных в почтовые сообщения. Типы, поддерживаемые в документах RDF, указываются при помощи атрибута type тега <Description>, что эквивалентно использованию встроенного тега-предиката <rdf:type>. Платформа Mozilla не поддерживает типов RDF Shema. Как правило, разработчику приложений следует хранить свои данные в файле RDF в виде простых строк XML и выполнять необходимые преобразования в коде приложения. 11.5.2.2 URN.До сих пор при обсуждении идентификаторов в этой главе мы использовали в качестве примеров только URL. Этот формат идентификатора полезен при хранении информации о web-сайтах и других ресурсах Internet. Однако если приложение должно работать с простыми данными, вместо URL рекомендуется использовать URN. Строго говоря, идентификаторы в RDF должны иметь формат URI, а не URL. URI (универсальный идентификатор ресурса) может быть либо URL (универсальным указателем ресурса), либо URN (универсальным именем ресурса). URL связывает ресурс с точкой доступа к нему (адресом) и методом доступа, например протоколом HTTP. Ресурс, доступный по указанному адресу, например web-страница, может меняться со временем. URN, с другой стороны, представляет собой всего лишь имя какого-нибудь понятия, которое предполагается неизменным. Если понятию соответствует объект реального мира, URN удобно использовать для обозначения этого объекта. С точки зрения программиста, URN представляет собой имя переменной или, точнее, константы - неизменного фрагмента данных. Хотя предполагается, что URN должны быть уникальными в глобальном масштабе, можно назначать собственные имена при условии, что они используются только внутри вашего приложения, - точно так же, как можно назначать любые IP-адреса и имена доменов в локальной сети, не взаимодействующей с Internet. Механизм регистрации URN описан в документе RFC 2611. Платформа Mozilla использует короткие URN, что удобно для разработчиков. Эти имена имеют следующий синтаксис: urn:{namespace}:{name}
Как {namespace}, так и {name} представляют собой строку. Строка {namespace} не может иметь значения "URN", а также содержать двоеточие (:). Строка {name} может содержать любые символы ASCII, включая двоеточие, что поначалу может показаться странным. Точный синтаксис URN описан в документе RFC 2141, согласно которому строка пространства имен {namespace} может содержать алфавитно-цифровые символы ASCII и нечувствительна к регистру символов, а имя {name} может также содержать знаки пунктуации и тоже нечувствительно к регистру. Существуют некоторые ограничения на допустимые знаки пунктуации. URN не могут быть "относительными". В Mozilla строка {name} является необязательной. Вот два примера корректных URN: urn:myapp:runstate urn:myapp:perfdialog:response Во втором URN часть {name} выглядит так, как если бы она содержала второе пространство имен, вложенное в первое, и собственно имя. С точки зрения формального синтаксиса это лишь видимость - перед нами обычное имя, содержащее символ двоеточия. Однако программисты могут использовать этот пример для того, чтобы упорядочить большое количество URN, разбив их на категории. Таким способом можно создать любое необходимое количество уровней. URN, используемые в документе RDF, превращают его из описания web- ресурсов, рассматриваемых в глобальном контексте, в документ для хранения локальной информации произвольного характера. Вот пример факта, записанного на языке RDF с использованием URN: <Description about="urn:mozilla:skin:modern/1.0" chrome:author="mozilla.org"/> Здесь chrome: представляет собой префикс пространства имен XML, "mozilla.org" - литерал, а "skin:modern/1.0" - имя сущности, на которую в данном случае указывает URN. Хотя эта запись представляет собой факт, а не простые данные, то же самое можно легко выразить при помощи простой конструкции на JavaScript: mozilla["skin:modern/1.0"].author = "mozilla.org"; Или, чуть более подробно: urn.mozilla.skin["modern/1.0"].chrome.author = "mozilla.org"; Разумеется, факт в общем случае не сводится к операции присваивания, так что эти примеры отражают лишь один из возможных способов интерпретации приведенного факта. Существует специальная схема URL (ей соответствует префикс протокола "data:"), предназначенная для представления обычных данных в виде URL и описанная в документе RFC 2397. Может показаться, что это удобный способ именования ресурсов, основанный на их содержании. Однако такие URL не могут использоваться в RDF, по крайней мере, в качестве идентификаторов, поскольку они не являются уникальными. Их следует избегать. 11.5.3. Пример URN: типы MIMEТипы MIME, наряду с расширениями файлов, используются в классическом браузере для того, чтобы передавать полученные документы внешним приложениям для отображения или обработки. Например, для просмотра документа Microsoft Word с расширением .doc в системе Microsoft Windows будет вызвано приложение winword.exe. Типы MIME конфигурируются в разделе настроек Правка | Настройки | Навигатор | Вспомогательные приложения. Как и Менеджер загрузок, система настройки типов MIME имеет интерфейс пользователя, и хранит данные о типах в специальном файле RDF. Интерфейс представляет собой специальную панель диалога настроек, а файл называется mimeTypes.rdf и находится в каталоге профиля пользователя. Исполняемый код этой системы находится в архиве comm.jar в каталоге chrome, в файлах, имеющих префикс pref-application. Эту подсистему Mozilla можно изучать так же, как и Менеджер загрузок. Разница между ними в том, что модель данных RDF для типов MIME использует URN, а не URL. Эти данные представляют собой набор фактов, субъектами которых являются URN, образующие иерархию. Пример такой иерархии для конфигурации всего лишь двух типов представлен в листинге 11.14. urn:mimetypes urn:mimetypes:root urn:mimetypes:text/plain urn:mimetypes:application/octet-stream urn:mimetypes:handler:text/plain urn:mimetypes:handler:application/octet-stream urn:mimetypes:externalApplication:text/plain urn:mimetypes:externalApplication:application/octet-streamЛистинг 11.14. Иерархия URN для двух типов MIME Поскольку URN представляют собой всего лишь имена, их видимая "иерархия" не имеет никакого значения с точки зрения обработки данных. Она предназначена не для программы, а для человека, читающего документ RDF. Однако существует и реальная иерархия - состоящая из фактов. Если построить иерархию фактов, описанных в файле mimeTypes.rdf, увидим, что факты образуют простую иерархию с некоторыми перекрестными ссылками. Эта иерархия во многом аналогична расширению объектной модели документа (DOM) window.navigator.mimeTypes, используемому web-разработчиками. Фактически, источником данных для этого массива служит файл mimeTypes.rdf. Как и в случае с Менеджером загрузок, вся информация о типах находится в контейнере <Seq>, который обеспечивает легкий доступ к ней. Если одновременно открыто несколько окон браузера и загружается содержимое различных типов, все эти окна пользуются одним и тем же источником данных RDF для определения того, как следует обрабатывать полученное содержимое. 11.5.4. Области применения RDFMozilla использует технологии RDF для реализации нескольких различных функций, но те же функции могли бы быть реализованы и без использования RDF. Для чего же тогда был создан RDF? Дело в том, что существуют некоторые проблемы уровня приложений, и RDF был разработан для их решения. Согласно спецификации RDF, основная область его применения - библиотечные каталоги (и вообще каталоги информационных ресурсов). Такие каталоги нуждаются в формальной и одновременно гибкой общепринятой модели данных, поскольку каталоги все больше подключаются к Internet и взаимодействуют друг с другом. Наиболее известным результатом деятельности в этом направлении является так называемое "Дублинское ядро" (Dublin Core). Оно представляет собой модель данных, предназначенную для описания любых публикаций, включая ресурсы Internet, и признанную библиотечной отраслью. В терминологии RDF Дублинское ядро представляет собой набор предикатов для описания информационных ресурсов. См. также информацию на сайте www.purl.org. Еще одна область применения RDF, согласно спецификации, - "управление содержимым". Под этим подразумевается процесс добавления к содержимому информации о его оценке, на основе которой могут приниматься управленческие и другие решения. Простые примеры "информации об оценке содержимого" - уровни секретности и возрастные рейтинги. RDF предоставляет очевидную возможность связать такую информацию о содержимом с его URL, формулируя соответствующие факты. Используя эту информацию, программная система может принять решение об отображении содержимого в зависимости от уровня доступа или возраста пользователя. В реальности существует целый ряд механизмов "управления содержимым" в указанном смысле, и RDF не является ни лидирующим, ни даже значительным игроком на этом поле. Область, в которой RDF к настоящему времени достиг определенных успехов, - работа с информационными иерархиями. Поддерживаемый добровольцами каталог web-ресурсов www.dmoz.org хранит как классификатор ресурсов, так и отдельные URL в одном большом RDF-файле. Пока RDF не занял позицию одного из ключевых компонентов инфраструктуры Internet, оставаясь лишь одним из многих полезных инструментов. При разработке приложений на платформе Mozilla следует рассматривать его именно в этом качестве. На этом мы заканчиваем обсуждение примеров применения RDF. 11.6. Практика: модели данных в NoteTakerЭто практическое занятие посвящено процессу моделирования, результатом которого является набор фактов RDF. Мы много экспериментировали с интерфейсом NoteTaker и скриптами JavaScript, однако пришло время заняться проектированием. У нас до сих пор нет ясного понимания того, какими данными должен манипулировать NoteTaker. Мы выбираем RDF в качестве формата для хранения этих данных. В процессе моделирования нам предстоит разработать модель данных, чтобы понять, какие факты RDF для этого понадобятся. Нашим языком моделирования будут факты, выраженные в форме триплетов. На платформе Mozilla RDF лучше всего использовать для локального хранения данных, хотя документы RDF могут и передаваться через Internet. Кроме того, RDF особенно эффективен при работе с небольшими объемами данных. Обе эти особенности отвечают нашей задаче, поскольку NoteTaker будет хранить относительно небольшое количество заметок, созданных пользователем, на локальном диске, в каталоге профиля пользователя. Доступ к Internet не будет обязательным условием работы NoteTaker. Выбор фактов в качестве языка моделирования не является очевидным. Вместо этого мы могли бы выбрать объектно-ориентированный или реляционный подход. Однако факты имеют одно важное преимущество - они непосредственно отображаются на синтаксис RDF. Язык UML хорош для объектно-ориентированных систем; модель "сущность - связь" хороша для реляционных баз данных; факты хороши для RDF. При разработке и реализации модели данных мы будем придерживаться следующего плана:
Как правило, при моделировании данных приходится предпринять несколько попыток, прежде чем будет найден оптимальный вариант. Мы, однако, сразу же начнем с приемлемого подхода, обращая в процессе моделирования внимание на некоторые распространенные ошибки и тупиковые направления. Мы можем без труда описать модель данных NoteTaker на естественном языке. Каждая заметка связана с одним URL. Она имеет короткое и длинное описание (аннотация и подробности). Она занимает на экране определенное положение, которое характеризуется двумя координатами ее левого верхнего угла, высотой и шириной. Кроме того, с заметкой связаны ключевые слова. Ключевые слова - обычные слова, добавляемые пользователем для характеристики URL, к которому относится заметка. Если два ключевых слова были использованы для описания одной заметки, говорят, что эти слова связаны. Эта связь имеет значение и за пределами конкретной заметки - тот факт, что они появились вместе в каком-либо контексте, указывает на то, что эти слова связаны в широком смысле. Связи между ключевыми словами могут использоваться для контекстно-зависимой подсказки пользователю. Когда последний выбирает ключевое слово для заметки, одновременно отображается список всех слов, связанных с выбранным. Пользователь может отметить некоторые слова в этом списке, чтобы присвоить их заметке одновременно с первым. В приложение NoteTaker, которое разрабатывается в этой книге, будет включен лишь минимум функциональности, связанной с ключевыми словами, для демонстрации некоторых приемов работы с XUL и RDF. Мы можем представить себе следующую версию NoteTaker, написанную в процессе развития нашего приложения. Эта версия может включать специальное окно Менеджера заметок, используемое для отображения списка всех заметок, его сортировки, управления заметками, их поиска по ключевым словам, а также позволяющее открыть web-документ, связанный с выбранной заметкой. Интерфейс NoteTaker включает еще два элемента данных, которые отображаются как флажки "Отбросить запрос" и "Корневая страница" в диалоговом окне редактирования заметки. Эти данные не являются свойствами заметки, а скорее управляют процессом ее создания. Если установлен флажок "Отбросить запрос", то из URL новой заметки будет удалена любая информация, относящаяся к запросу GET. Например, этот URL http://www.test.com/circuits.cgi?voltage=240V;amps=50mA будет сокращен до следующего http://www.test.com/circuits.cgi При этом вновь созданная заметка будет появляться при просмотре любой страницы, чей URL начинается с этой сокращенной строки. Если установлен флажок "Корневая страница", то URL будет сокращен еще больше, до http://www.test.com/ В этом случае заметка будет соответствовать всем страницам данного сайта. Если URL содержит каталог отдельного пользователя, как в примере: http://www.test.com/~fred/mytests/test2.htm то при установленном флажке "Корневая страница" он будет сокращен http://www.test.com/~fred/ При использовании любого из этих вариантов при просмотре конкретного URL будет отображаться только наиболее специфичная для него заметка. Иными словами, если одновременно определены заметка для корневой страницы сайта и заметка для другой его страницы, то при просмотре этой страницы будет отображаться лишь последняя заметка. В любом случае, наличие этих флажков никак не влияет на модель данных NoteTaker, поскольку результатом установки любого из них является преобразование URL при создании заметки, а не сохранение дополнительных параметров вместе с заметкой. На этом выполнение первого этапа нашего плана завершено, и мы можем перейти ко второму. В результате процесса моделирования все наши данные должны быть представлены в виде фактов-триплетов. Пока же мы должны выбрать из описания значимые термины, которые в дальнейшем станут термами этих фактов. Поскольку факты включают информацию об отношениях, мы должны обращать внимание не только на существительные (потенциальные субъекты и объекты фактов). Однако выделение значимых существительных может быть хорошей отправной точкой для дальнейшей работы. Предположим, что при первой попытке анализа описания мы получили следующие результаты: заметка ключевое-слово URL аннотация подробности сверху слева высота ширина Здесь "сверху" и "слева" - расстояние левого верхнего угла заметки от верхнего и левого краев экрана соответственно. К этим существительным мы можем добавить следующие предполагаемые отношения: связанное-ключевое-слово данные-заметки заметка-для-url Теперь мы должны сконструировать факты на основе этих терминов. Факты могут рассматриваться как триплеты субъект-предикат-объект или, в терминологии RDF, как триплеты ресурс-свойство-значение. Для нашего анализа полезны обе точки зрения. Прежде всего, мы проанализируем каждый из терминов при помощи трех вопросов:
Третий вопрос поможет нам выявить "слабые" термины, чтобы ограничить число субъектов в нашей модели. Результаты анализа представлены в таблице 11.4 (цифры указывают на пункты обсуждения в последующем тексте).
На основе этого анализа мы можем сделать некоторые выводы, а ряд вопросов требует дополнительного обсуждения. Начнем с выводов: ключевое-слово представляет собой сущность; данные-заметки - отношение; аннотация, подробности, сверху, слева, ширина и высота - свойства для описания других сущностей. Мы можем быть уверены в этом, поскольку в каждой из соответствующих строк таблицы присутствует лишь одна отметка. Теперь обсудим проблемы, возникшие при анализе терминов. 1. Мы полагаем, что конкретные ключевые слова не могут рассматриваться как свойства другого термина, поскольку это означало бы, что на основе этих ключевых слов должны быть образованы свойства RDF (предикаты). Хотя с формальной точки зрения в этом нет ничего невозможного, обычно предполагается, что свойства имеют хорошо известные имена, например "цвет". Нам известно, что у каждой заметки может быть ноль или более ключевых слов, каждое из которых имеет собственное имя, указанное пользователем. Это означает, что для ключевых слов не существует постоянного хорошо известного имени и, следовательно, вряд ли имеет смысл использовать их в качестве свойств. Следует ожидать аналогичных проблем для любого элемента данных, который находится в отношении "многие к одному" с другим элементом данных. 2. Эти термины не имеют собственных свойств, поэтому нет оснований считать их самостоятельными сущностями. Очевидно, они являются свойствами каких-то других сущностей, например URL или заметки. 3. Нам не вполне ясна ситуация с заметкой и URL. Является ли один из этих терминов свойством другого или же они независимы? Пока лучше считать, что оба термина - сущности. 4. Смысл такого термина, как "данные заметки" не вполне ясен. Он не указывает ни на конкретные данные, ни на отношение между ними, ни на какую-либо другую определенную информацию. Можно сравнить этот неопределенный термин с "аннотацией", которая является конкретным фрагментом данных, связанным с заметкой. Фактически мы невольно привнесли в нашу модель элемент метаданных - "заметки имеют данные". Поэтому мы просто исключим этот термин из дальнейшего анализа - простые приложения не нуждаются в метаданных. На основе нашего анализа мы можем сформулировать факты, перечисленные в листинге 11.15. <- заметка, ?, URL -> <- URL, ?, заметка -> <- заметка, URL, ? -> <- URL, заметка, ? -> <- ключевое-слово, ?, ? -> <- заметка, аннотация, ? -> <- заметка, подробности, ? -> <- заметка, сверху, ? -> <- заметка, слева, ? -> <- заметка, ширина, ? -> <- заметка, высота, ? -> <- ?, связанное-ключевое-слово, ? -> <- ?, заметка-для-url, ? ->Листинг 11.15. Исходные факты для модели данных NoteTaker Первые четыре факта представляют собой четыре варианта разрешения неопределенности, с которой мы столкнулись. Мы должны сделать выбор, исходя из потребностей приложения. Мы вернемся к этой проблеме после того, как разберем более простые вопросы. Шесть следующих фактов с субъектом "заметка" тривиальны. Каждый из них будет содержать в качестве объекта простое значение, следовательно, этим объектом не может быть URI. Их объект должен относиться к одному из типов, поддерживаемых Mozilla (Literal, Integer, Date, Blob). Мы будем использовать тип Literal, который представляет собой простую строку. Тогда эти факты примут следующий вид: <- заметка, аннотация, Literal -> Факт с предикатом связанное-ключевое-слово связывает между собой два ключевых слова. Очевидно, что субъектом и объектом этого факта должны быть ключевые слова. Заменив для краткости предикат на "связано", получаем следующий факт: <- ключевое-слово, связано, ключевое-слово -> Использование ключевых слов в фактах создает проблему имен. Нам известно, что ключевое слово должно быть представлено посредством URI, поскольку оно является сущностью (ресурсом). Если не считать, что где- то существует сервер, определяющий все ключевые слова в мире (что вряд ли имеет практический смысл), для ключевых слов должны использоваться URN, а не URL. Откуда мы можем взять эти URN? Их можно построить на основании данных, предоставленных пользователем. Для этого мы добавим к строке ключевого слова, введенной пользователем, префикс urn:notetaker:keyword: (мы используем английское слово "keyword", поскольку синтаксис URL допускает лишь использование ASCII-символов7)). Например, ключевому слову foo будет присвоен следующий URI: urn:notetaker:keyword:foo Нам также понадобится доступ к самой строке ключевого слова. В последующих главах мы увидим, что извлечь подстроку из URI, используемого в RDF, довольно сложно. Поэтому мы введем свойство "метка" и будем хранить его как отдельную строку в составе следующего факта: <- urn:notetaker:keyword:{строка ключевого слова},
метка, "{строка ключевого слова}" ->
Наконец мы должны разобраться с вопросом о соотношении заметки и URL. Каждому URL соответствует одна заметка, и каждой заметке соответствует один URL. Необходимо решить, являются ли они отдельными сущностями. Если это так, нам понадобится каким-то образом описать связь между ними. Если их нельзя рассматривать как отдельные сущности, то одна из них, вероятно, будет свойством другой. Если считать URL и заметку отдельными сущностями, каждая из них должна иметь собственный URI. Необходимо подобрать для них эти URI. В случае URL выбор очевиден - это сам URL. Что же может использоваться в качестве URI для заметки? Это должен быть URN (мы могли бы использовать URL файла, но это было бы необычным решением). Поскольку заметка не имеет имени, мы можем сконструировать для нее произвольное имя (каким образом?) или оставить ее анонимной (но в этом случае документ RDF не будет полностью определенным). Оба решения довольно неуклюжи. Таким образом, мы приходим к выводу, что заметке недостает собственной идентичности, и она должна каким-то образом зависеть от URL. Поскольку заметка не имеет идентичности (не может быть поименована), она не может быть субъектом или объектом никакого факта. Поскольку она не имеет "собственного значения", она не может быть представлена литералом. Таким образом, заметка как сущность, самостоятельная или зависимая, просто не существует. Мы исключаем ее из нашей модели, оставляя только URL, к которому относится эта заметка. Это решает большинство проблем, связанных с первыми четырьмя фактами листинга 11.15. Такой результат может показаться странным, особенно для читателя, который знаком с объектно-ориентированным или реляционным моделированием. Разве заметка не является центральным объектом всего приложения NoteTaker? Разве мы не вправе создавать в нашей модели любые объекты или сущности, которые сочтем необходимыми? Ответ на первый вопрос - "да", а на второй - "нет". Да, заметка действительно является центром приложения, но, как выяснилось, не его модели данных. Нет, мы не вправе порождать сущности по своему усмотрению, поскольку мы работаем не с "чистой" системой обработки фактов, подобной Prolog, а с RDF. В RDF существует одна базовая концепция, которая предшествует любой конкретной модели - концепция ресурса, основанного на URI. Мы не вправе создавать любые объекты - мы можем использовать лишь сущности, имеющие URI, или литералы. Хотя наше приложение основано на идее заметки, в модели данных RDF любая значимая сущность должна иметь собственный URI. Например, мы смогли поместить ключевые слова в нашу модель данных лишь потому, что смогли подобрать URI для каждого из них. Итог этого рассуждения прост - чтобы использовать сущность в модели данных RDF, необходимо подобрать для нее URL или URN, или представить ее как литерал. В противном случае для этой сущности нет места в модели данных. В листинге 11.16 представлены факты после произведенных нами изменений: <- URL, аннотация, Literal -> <- URL, подробности, Literal -> <- URL, сверху, Literal -> <- URL, слева, Literal -> <- URL, ширина, Literal -> <- URL, высота, Literal -> <- ключевое-слово, метка, Literal -> <- ключевое-слово, связано, ключевое-слово ->Листинг 11.16. Окончательные факты для модели данных NoteTaker Очевидно, что в этом списке отсутствует факт связи между ключевым словом и заметкой (точнее, с URL, которому соответствует заметка). Мы не затрагивали этой связи в процессе анализа, поскольку нам не было ясно, являются ли ключевые слова сущностями или свойствами. Мы не можем использовать конкретные ключевые слова в качестве свойств (предикатов), поскольку каждое ключевое слово имеет свой URN. Мы можем попробовать один из вариантов: <- URL, ключевое-слово, urn-ключевого-слова -> <- urn-ключевого-слова, url-заметки, URL-> Каждому URL (и заметке) может соответствовать ноль или более фактов первого типа. Вместо этого (или в дополнение к этому), каждому ключевому слову может соответствовать ноль или более фактов второго типа. В предлагаемом решении каждая заметка (каждый URL) может иметь несколько свойств "ключевое слово". Можем ли мы использовать для их хранения контейнер RDF, например <Seq>? К сожалению, это не так просто. Пойдя по такому пути, мы должны будем использовать отдельный контейнер для каждого URL с определенной заметкой. Какое имя должен иметь такой контейнер? Это должен быть URN, и нам придется сконструировать его. В принципе, мы можем добавить URL, связанный с заметкой, к какому-либо префиксу. Это возможный, но громоздкий подход, и на этом пути мы столкнемся с трудностями обработки строк, речь о которых пойдет в следующих главах. Мы предпочтем придерживаться простых решений и обойтись без контейнера <Seq>. Мы будем использовать первый из предложенных вариантов: <- URL, ключевое-слово, urn-ключевого-слова -> Таким образом, мы завершили третий и четвертый этапы нашего плана - выразили всю необходимую информацию о модели данных при помощи фактов, включающих литералы и ресурсы, именованные при помощи URI. Пример набора фактов, описывающих заметку, которой присвоены два ключевых слова - "test" и "cool",- приведен в листинге 11.17. <- http://saturn/test.html, аннотация, "Моя аннотация" -> <- http://saturn/test.html, подробности, "Мои подробности" -> <- http://saturn/test.html, сверху, "100" -> <- http://saturn/test.html, слева, "90" -> <- http://saturn/test.html, ширина, "80" -> <- http://saturn/test.html, высота, "70" -> <- http://saturn/test.html, ключевое-слово, urn:notetaker:keyword:test -> <- http://saturn/test.html, ключевое-слово, urn:notetaker:keyword:cool -> <- urn:notetaker:keyword:test, метка, "test" -> <- urn:notetaker:keyword:cool, метка, "cool" -> <- urn:notetaker:keyword:test, связано, urn:notetaker:keyword:cool ->Листинг 11.17. Пример фактов, описывающих одну заметку NoteTaker. Последний факт выражает связь между ключевыми словами. Мы могли бы сформулировать и обратный факт, поменяв местами субъект и объект. Однако в этом случае мы получили бы множество избыточных фактов для заметки со множеством ключевых слов. Поэтому здесь мы ограничились минимумом фактов, необходимых для описания связи между ключевыми словами. Пятый и шестой этапы нашего плана связаны с эффективностью доступа к необходимым данным документов RDF. Более подробно эти вопросы обсуждаются в главе 14 "Шаблоны". Чтобы извлекать данные более эффективно, мы можем снабдить их дополнительной структурой, которую затем будут использовать скрипты и шаблоны. Единственные средства добавления такой структуры, которые поддерживает RED, - теги- контейнеры, ограниченный набор типов и возможность создавать неограниченное количество дополнительных фактов. Сценарии и шаблоны, входящие в состав NoteTaker, должны будут выполнять следующие задачи:
Мы хотим, чтобы помимо выполнения этих видов поиска, приложение могло легко и быстро добавлять, удалять и изменять заметки. Эти задачи достаточно просты, поэтому мы сосредоточимся на приведенном списке, который фактически представляет собой набор запросов. Mozilla может находить факты в документе RDF независимо от того, каким образом они организованы, но можно принять некоторые меры к тому, чтобы поиск работал быстрее. Кроме того, можно сделать документ RDF более удобным для чтения. В данном случае мы сделаем две вещи:
Запрос 5 очень сложен, поскольку он требует просмотра большого количества фактов, имеющих отношение к ключевым словам. На данном этапе мы вряд ли можем предпринять что-либо для ускорения этого запроса. Как бы он ни выполнялся, для этого понадобится посмотреть все факты о связях между ключевыми словами или большую их часть. Поскольку предполагается, что в документе RDF <Bag> и другие теги-контейнеры представляют собой субъекты фактов, мы добавим тег верхнего уровня <Description>, имеющий URN urn:notetaker:root. Оба наших контейнера <Bag> будут значениями свойств этого тега. К этому и сводится все необходимое нам моделирование. Седьмой этап плана представляет собой механическое преобразование модели данных в документ RDF. Каркас документа RDF (простейший документ, не содержащий информации о конкретных заметках и ключевых словах), показан в листинге 11.18. <?xml version="1.0"?>
<RDF xmlns="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmnls:NT="http://www.mozilla.org/notetaker-rdf#>
<Description about="urn:notetaker:root">
<NT:notes>
<Seq about="urn:notetaker:notes"/>
</NT:notes>
<NT:keywords>
<Seq about="urn:notetaker:keywords"/>
</NT:keywords>
</Description>
</RDF>
Листинг
11.18.
База данных NoteTaker в RDF в отсутствие заметок.Если добавить к этому документу факты о заметке, представленные в листинге 11.17, результатом будет документ, представленный в листинге 11.19.8) <?xml version="1.0"?>
<RDF xmlns="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmnls:NT="http://www.mozilla.org/notetaker-rdf#>
<Description about="urn:notetaker:root">
<NT:notes>
<Seq about="urn:notetaker:notes">
<li resource="http://saturn/test.html"/>
</Seq>
</NT:notes>
<NT:keywords>
<Seq about="urn:notetaker:keywords">
<NT:keyword resource="urn:notetaker:keyword:cool/>
<NT:keyword resource="urn:notetaker:keyword:test/>
</Seq>
</NT:keywords>
</Description>
<!-- одна заметка -->
<Description about="http://saturn/test.html">
<NT:summary>Моя аннотация<NT:summary/>
<NT:details>Мои подробности<NT:details/>
<NT:top>100<NT:top/>
<NT:left>90<NT:left/>
<NT:width>80<NT:width/>
<NT:height>70<NT:height/>
<NT:keyword resource="urn:notetaker:keyword:test"/>
<NT:keyword resource="urn:notetaker:keyword:cool"/>
</Description>
<!-- строки ключевых слов -->
<Description about="urn:notetaker:keyword:test label="test"/>
<Description about="urn:notetaker:keyword:cool label="cool"/>
<!-- связи между ключевыми словами, пока есть одна -->
<Description about="urn:notetaker:keyword:test">
<NT:related resource="urn:notetaker:keyword:cool">
</Description>
</RDF>
Листинг
11.19.
База данных NoteTaker в RDF с одной заметкой.Некоторые теги <NT:keyword> повторяются в этом файле. При разработке всегда существует выбор между простотой данных и простотой системы, которая должна делать запросы к этим данным. В данном случае мы допустили некоторое дублирование данных, чтобы сделать более простым выполнение запросов (см. лекцию 14 "Шаблоны"). Таким образом, мы завершили работу над моделью данных для NoteTaker и одновременно разработали формат файла для хранения этих данных. Мы используем RDF потому, что NoteTaker является приложением, работающим на стороне клиента (не получающим данные с сервера), и объемы хранимых данных будут, скорее всего, невелики. 11.7. Отладка: вывод документа RDFКак правило, обработка данных RDF происходит без выдачи каких-либо сообщений. Существует ряд приемов, позволяющих получить информацию о состоянии хранилища фактов или файлов RDF. Документы RDF, особенно сгенерированные автоматически, часто разбиты на строки не самым удобным для чтения образом; в них не всегда используются отступы, чтобы отразить уровень вложенности тегов. Авторы документов для своих целей могут добавлять дополнительные пробелы или переводы строк. Можно просмотреть документ RDF как чистый, иерархически организованный XML-документ без лишних пробелов и переводов строк. Для этого нужно изменить расширение файла на .xml (или создать символическую ссылку на него с таким расширением) и загрузить файл в окно Навигатора. Если вы из какого-либо скрипта модифицируете источник данных RDF, нет необходимости перезапускать Mozilla, чтобы сделать изменения доступными для других модулей и приложений, выполняемых на платформе Mozilla, - об этом позаботится система кэширования. Автоматическое построение графа произвольного RDF-документа (подобного тому, который показан на рисунке 11.5) - непростая задача. Не так сложно написать программу для рисования графа, структура которого проста или известна заранее. Такой граф может быть отображен при помощи версии Mozilla с включенной поддержкой SVG - вы можете работать с объектной моделью (DOM) документа SVG, чтобы динамически изменять граф. Действительно сложная задача - написать универсальную программу, которая гарантированно строила бы граф произвольного RDF- документа в виде, удобном для восприятия. Здесь существуют определенные теоретические ограничения, это сложная задача, и не следует пытаться решить ее за ограниченный промежуток времени. Страница RDF на сайте Консорциума WWW (www.w3.org) содержит обширный перечень программных инструментов для работы с RDF. Если вы не знаете точно, в каком состоянии находится ваше хранилище фактов (например, вы многократно модифицировали его из своей программы), существует легкий способ записать его текущее состояние на диск. Для этого используется код, приведенный в листинге 11.20. // подготовка ..
var Cc = Components.classes;
var Ci = Components.interfaces;
var comp = Cc["@mozilla.org/rdf/rdf-service;1"]
var iface = Ci.nsIRDFService;
var svc = comp.getService(iface);
var ds = svc.GetDataSource("file:///C|/tmp/test.rdf");
var rds = ds.QueryInterface(Ci.nsIRDFRemoteDataSource);
// .. обычная работа с хранилищем фактов ..
function dumpRDF()
{
// чтобы произошла запись в файл, должно быть
сделано хотя бы одно изменение
var sub = svc.GetResource("urn:debug:subject");
var pred = svc.GetResource("DebugProp");
var obj = svc.GetResource("urn:debug:object");
ds.Assert(sub, pred, obj, true);
rds.Flush(); // записать в файл
}
Листинг
11.20.
Запись текущего состояния хранилища фактов на диск.Этот код создает источник данных RDF на основе файла C:/tmp/test.rdf. Функция dumpRDF() может быть вызвана в любой момент после завершения загрузки источника (это можно проверить при помощи флага rds.loaded или используя объект-наблюдатель). Функция dumpRDF() всего лишь добавляет один факт к хранилищу фактов и записывает текущее состояние хранилища в исходный файл. Иными словами, файл синхронизируется с состоянием хранилища в памяти. Факт добавляется для того, чтобы состояние хранилища гарантированно изменилось, и произошла запись на диск. При просмотре файла этот факт будет выглядеть примерно следующим образом: <RDF:Description about="urn:debug:subject"> <DebugProp resource="urn:debug:object"/> </RDF:Description> DebugProp и debug - простые строки, не имеющие специального значения. 11.8. ИтогиСистемы обработки фактов отличаются от обычных систем обработки данных. Для их понимания необходимо усвоить целый ряд новых терминов: факт, кортеж, триплет, субъект, предикат, объект, хранилище фактов. Кроме того, существует и терминология, специфичная для RDF: описание, ресурс, свойство, значение, контейнер, URL, URN. RDF представляет собой не самое простое приложение XML, однако он основан на продуманных концепциях. Внутри платформы Mozilla содержится ряд относительно тяжеловесных структур и модулей, которые интенсивно обмениваются информацией в процессе обработки и отображения содержимого. Каналы и источники данных - разновидности таких структур, тесно связанные с RDF. Внутри платформы RDF широко используется в самых разных местах. Существует множество источников данных, компонентов и интерфейсов, связанных с RDF, которыми может воспользоваться разработчик приложений. И браузер, и другие приложения на платформе Mozilla широко используют RDF для хранения информации о своем состоянии в промежутках между сеансами работы. Если бы обработка RDF требовала меньших ресурсов, он мог бы стать универсальным форматом обмена сообщениями, однако в настоящее время он пригоден для задач, где производительность не является критичной. После всех сложностей RDF уместной была бы какая-нибудь легкая тема. В следующей главе мы рассмотрим систему оверлеев и chrome Mozilla. Для практической работы с ними достаточно лишь тегов XML и XUL. Однако, исключительно для полноты картины, мы рассматриваем и элементы RDF, лежащие в основе этих механизмов. 2) Description - описание; about - о (англ.). (Прим. пер.) 3) Англ. reification - буквально "овеществление". 4) Описание. (Прим. пер.) 5) Англ. "утверждение". (Прим. пер.) 6) Англ. sequence - последовательность. 7) Согласно документу RFC 2141, символы, выходящие за пределы диапазона ASCII, для использования в URN должны преобразовываться в кодировку UTF-8. Затем результат преобразования побайтово кодируется так же, как это принято для URL - каждый байт представляется с помощью символа "%" и двух шестнадцатеричных цифр. (Прим. пер.) 8) В окончательном документе RDF мы используем английские имена свойств: notes - заметки; keywords - ключевые слова; summary - аннотация; details - подробности; top - сверху; left - слева; width - ширина; height - высота; label - метка; related - связано. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||