| Разработка приложений с помощью Mozilla / автор: Н.Макфарлейн | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
13. Глава:
Списки и Деревья
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
В этой главе описывается устройство двух самых мощных инструментов (widget) XUL'а: <listbox> и <tree>. Эти теги сконструированы для приложений с большим количеством данных. Teг <listbox> дает нам пролистываемый, или скролируемый, список, который похож на меню, но может иметь несколько колонок. Тег <tree> дает (возможно, иерархически упорядоченный) список записей, имеющих древовидную структуру. Тег <tree> похож на Windows Explorer в Microsoft Windows, или даже еще больше, на Finder в Macintosh. Тег <tree> делает все то же самое, что и <listbox>, и сверх того, но <listbox> имеет более простой и более ясный синтаксис. Синтаксис <tree> может быть очень сложным. Чтобы увидеть <tree> в действии, достаточно посмотреть на классический Mail & News клиент. Это три панели, каждая из которых создана своим тегом <tree>. Подобную структуру можно увидеть в менеджере закладок, который представляет все доступные закладки в виде единого дерева. Дать представление о списке, <listbox>, даже труднее, потому что подобную функциональность дает и дерево, <tree>. Примером тега <listbox> может служить панель "Темы" в классической Mozilla. Приложения, предназначенные для ввода и редактирования данных, должны быть сконструированы более тонко, нежели web-страницы. В них на единицу площади окошка должно приходиться гораздо больше информации. Они не должны тратить место на излишние красоты. Графически плотное представление большого количества данных нуждается в соответствующих экономичных элементах управления (widget). И <listbox>, и <tree> подразумевают такой "плотный" дизайн. Оба тега управляют содержанием скролируемых, очень интерактивных окошек. Вторая их черта - графическое представление групп записей. Такие различные приложения, как почтовые клиенты, окошки ввода заказа или центр управления сетью должны уметь показывать множество записей за раз. Путешествие через множество структурированных данных - броузинг данных, в том же самом смысле, как путешествие по web-страницам - web-броузинг. Интерактивные и скролируемые теги <listbox> и <tree> очень подходят для такого использования. Эти последние XUL-виджеты вынуждают нас снова вернуться к GUI платформы Mozilla. Приблизительная диаграмма в начале этой главы показывает, как данные теги встроены в платформу. Оба тега затрагиваю множество элементов платформы. Они затрагивают все свойства пользовательского интерфейса с одной стороны, и инфраструктуру DOM, фреймов и CSS2 cтилей. Оба тега имеют такие свойства, которые позволяют нам проникнуть с помощью скриптов гораздо глубже в структуру фреймов, чем любой иной тег платформы. Еще одна новая для нас черта - то, что в них мы можем выбрать сразу несколько записей. В этой главе мы описываем все перечисленные свойства, но оставляем равный по сложности материал о наполнении этих виджетов реальными данными до главе 14, Шаблоны. Mozilla дает нам много других возможностей для представления структурированных данных. Перед тем, как обратиться к тегам <listbox> и <tree>, рассмотрим простые текстовые таблицы (text grid). 13.1. Текстовые таблицыПоля ввода текста могут быть организованы в текстовую таблицу. Текстовая таблица - неформальный термин для описания двуразмерных массивов редактируемых блоков (boxes). Очевидный пример текстовой таблицы - электронная таблица, с колонками и строчками. Небольшая текстовая таблица - идеальный инструмент для уточнения структуры данных и для работы с набором записей. XUL не имеет непосредственного инструмента для работы с текстовыми таблицами, но их легко создавать с помощью тега <textbox>. Web-странички, кажется, игнорируют гибкость тега <textbox>. На web мы обычно видим формы для ввода данных сконструированными так, что их поля отдалены одно от другого. Запросы персональной информации или деталей заказа зачастую представлены так, что под каждое поле вывода отводится целая строка. Это делает текстовые таблицы громоздкими. На деле же и HTML тег <INPUT>, и XUL тег <textbox> могут быть сконструированы весьма компактно. Для этого требуются очень простые стили: textbox {
border : solid thin;
border-width : 1px;
padding : 0px;
margin : 0px; }
input:focus {
background-color : lightgrey;
}
Второй стиль нужен лишь для того, чтобы поле, получающее фокус, было подсвечено. Вернемся к главе 7, "Формы и Меню", и вспомним, что <texbox> содержит также и тег <html:input>. На рисунке 13.1 показан пример такой компактной таблицы. Каждый <textbox> - содержание одной ячейки в теге <grid>. Код шаблонен. Навигационная модель XUL и управление фокусом ввода гарантирует, что при нажатии клавиши Tab мы будем переключены на каждый <textbox> по очереди, и что каждое поле будет подсвечиваться, получив фокус. В результате мы получаем привычные по виду и удобные для работы приложения. Набор тегов <textbox>, однако, не является законченным решением сам по себе, приложению требуется еще целый программный комплекс по их обслуживанию. Такая страничка на XUL может содержать множество обработчиков событий, единственная цель которых - координировать данные и поведение пользователя. Поэтому требуется значительная работа по программированию скриптов для подобных окошек (раньше их называли экранами). 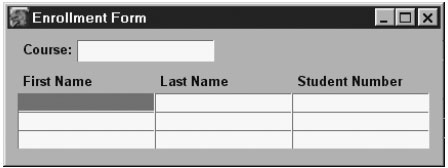 Рис. 13.1. Простая таблица списка, используется тэг <textbox> Web-системы не следуют этому типу оформления по нескольким причинам. Трудно поместить несколько записей одновременно в одну директиву POST; необходимо обеспечить особенное поведение для людей с ограниченными возможностями; сложность воплощения и высокая вероятность того, что сильно различаются размеры окон браузеров. XUL-приложения не столь ограничены в своих возможностях, и заманчиво попробовать усовершенствовать предоставляемые пользователю функции. Оба тега - и <listbox>, и <tree> - улучшают и уточняют концепцию текстовых таблиц. Текстовые таблицы - лишь наиболее простой и общий метод. Он, однако, может быть и самым удачным, если данных очень много. 13.2. СпискиТег <listbox> подобен по конструкции тегу <grid>, но по внешнему виду и поведению напоминает тег <menulist>. Список - это упорядоченное по вертикали множество записей, каждая из которых может иметь несколько полей. Тег HTML <SELECT rows= > подобен тегу XUL <listbox>. Этот HTML тег дает строковое, а не выпадающее меню. Тег <SELECT> ясный и стандартный, но <listbox> не обладает, увы, такими свойствами. В Mozilla версий до 1.4, <listbox> работает не очень стабильно, поэтому будьте аккуратны. Несмотря на такой недостаток, это мощный инструмент, если его правильно использовать. 13.2.1. Внешний вид списковЧтобы увидеть, как выглядит <listbox>, откройте вкладку (Edit | Preferences) в настройках Mozilla и посмотрите на панель "Темы" справа. Белая панель, на которой вы видите имена тем, такие как Classic и Modern, - это список. На рисунке 13.2 показаны два списка и их свойства. Список слева имеет одну колонку. Этот формат использует и тег HTML <SELECT>. Список имеет стили высоты и ширины, которые имеют по умолчанию 200px. Если площадь списка не позволяет вместить его содержание, появится вертикальная полоса прокрутки, и содержание тега <label> может быть обрезано. Как мы видим, каждая строка может иметь в начале пиктограмму и флажок. В реальном приложении пиктограммы и флажки могут иметь все строки, а не только некоторые, как показано здесь. В этом примере строка 4 была помечена кликом на флажке, а потом фокус получила строка 3.  Рис. 13.2. Два списка, демонстрирующие их свойства Список справа многоколонный. Он имеет две колонки, но их может быть сколько угодно. Верхняя строка - добавочная, для заголовков. Первая заголовочная строка имеет пиктограммы и слева, и справа от текста. Левая пиктограмма - необязательное изображение, добавляемое стилем. Правая пиктограмма имеет специальное значение, и показывает порядок сортировки всех нижележащих строк. Правая пиктограмма размещается с помощью XML-атрибута. Остальные строки (также называемые элементами) этого списка имеют по две ячейки каждая. Пиктограммы могут быть помещены в этих строках, хотя вряд ли это целесообразно. Флажки также могут быть размещены в этих строках, но нет способа выбрать их все автоматически, поэтому это тоже не имеет большого смысла. На снимке третья строка выбрана (она выделена серым), но второй список не имеет фокуса. Фокус имеет список слева - на снимке он темно-серый, а в реальности голубой. Содержанием ячейки может быть простой тег <label> или любой блочный тег с произвольным содержанием. Если используется произвольный контент, внешний вид контролировать нельзя, и список может обрезать строки, если изменять его размер. Это может вызвать трудности с CSS2 и другие неприятные последствия, поэтому благоразумно использовать простейшие теги <label>. Многоколонные списки могут иметь строки с меньшим числом ячеек, чем число колонок, и это будет работать (включая флажки), но делать так не рекомендуется. Если многоколонный список получает вертикальную полосу прокрутки, она не распространится на добавочную строку. 13.2.2. Строение списковРисунок 13.3 повторяет 13.2, но с включенной диагностикой. 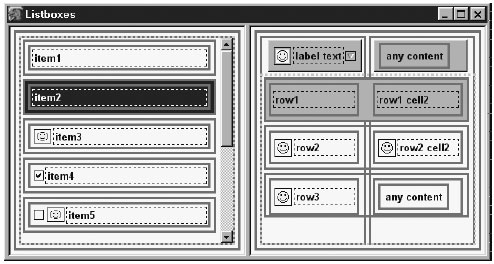 Рис. 13.3. Демонстрация внутренней структуры двух списков. Как всегда, тонкие прерывистые - теги <label>, тонкие сплошные - изображения, а толстые серые линии - блоки. Смайлики слева слегка сплющены только потому, что добавочные линии несколько исказили верстку. Список справа может показаться сложноватым, но приглядевшись, мы заметим, что эти блоки очень напоминают блоки тега <grid>, обсуждавшиеся в главе 2, "Проектирование с XUL". Табличная структура используется как базовая стратегия верстки списка, с тегом <button> для заголовков колонок и тегом <label> для содержания ячеек. Заголовок второй колонки и правая половина третьей строки списка показывают, что <label> может быть заменен на произвольный блок. Две затененные строки (по одной в каждом списке) показывают, что эти строки были выбраны. Такая подсветка - всего лишь стиль, применяемый к эквиваленту подтега <row> тега <grid>. Рисунок 13.4 также демонстрирует нам блок, специфичный именно для списков. Это серая, толстая, прерывистая линия в обоих списках. Данный блок ограничивает все строки каждого списка. Он интенсивно используется в реализации списков. Это отличает систему верстки тега <listbox> от системы верстки тега <grid>. Тег <listbox> и все относящиеся к нему теги, имеет XBL-определение, хранимое в файле listbox.xml из архива toolkit.jar в каталоге chrome. Платформа Mozilla имеет мощную C/C++ поддержку списков. Какой из списочных тегов выбрать, зависит от ваших задач. Теги, которые использует программист конкретного приложения, отличны от тегов, которые использует сама платформа, генерируя финальную верстку. Таблица 13.1 описывает все списочные теги и их статус для версии 1.4. <listbox> использует пару тегов <listcols> и <listcol> для описания колонок, но он использует <listrows> и <listhead> или <listitem> для строк. Тег <grid>, однако, не имеет точных соответствий тегу <listbox>. Специальный прерывистый блок, показанный на рисунке 13.3 - это граница тега <listboxbody>. Это ключевой момент в обеспечении поддержки скролинга в Mozilla.
<listbox>
<listhead>
<listheader label="Sole Column">
</listhead>
<listitem label="first item"/>
<listitem label="second item"/>
<listitem label="third item"/>
</listbox>
Листинг
13.1.
Простейший список, содержащий три элемента.В листинге 13.1 описан список с одной колонкой и тремя строками, имеющий заголовок, гласящий "Одна Колонка". Нет ни пиктограмм, ни флажков. Он подобен многим блокам диалога Настроек, например, панели "Внешний вид", "Темы" или "Навигатор", "Языки". Эти примеры не имеют заголовков. Mozilla, однако, умеет работать со многими дополнительными тегами, как показано на рисунке 13.4. Теги, соответствующие тегам листинга 13.2, в этом полном дереве тегов затенены. Светлые теги с префиксом "xul:" сгенерированы XBL- определением списка. Это полная структура списка, за исключением того, что если бы он имел две колонки, теги <xul:listcol>, <xul:listheaditem>, и <xul:listcell> появились бы дважды в каждой позиции дерева тегов, а не один раз. Это дерево демонстрирует, что листинг 13.2 использует весьма сокращенный синтаксис - многие теги подразумеваются, а не выписываются явно. 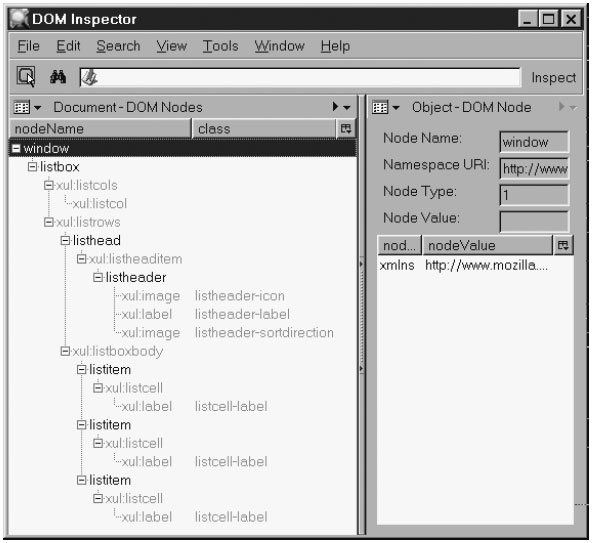 Рис. 13.4. Изображение списка из трех строк в инспекторе DOM. Рисунок также показывает нам подобие и разницу тегов <listbox> и <grid>. Оба тега имеют колонки и строки, <listbox> имеет всего две строки, в то время как <grid> может иметь любое их число. Строки в списке сгруппированы внутри второй основной строки, как если бы эта строка была тегом <vbox>. Первая, заголовочная, строка, может отсутствовать, если заголовков нет. Вот несколько основных правил построения списков:
Столь сложный процесс создания списка имеет свои внутренние ловушки. Главная ловушка состоит в том, что XUL не сможет обработать комбинацию тегов, которую сам же создает для тега <listbox>. Если вы создадите код, соответствующий дереву, показанному на рисунке 13.5, то он не будет интерпретирован как список, а Mozilla может даже упасть. Это значит, что XML-спецификация списка и ее XML-реализация существуют сами по себе и отличаются друг от друга. Mozilla может упасть также, если использовать любой из тегов, упомянутых в пункте 5. Она упадет и в том случае, если определить любое содержание в теге <listcol>. Не отступайте слишком от стандартного пути работы со списками, следуйте образцам, приведенным в книге. В противном случае платформа может вести себя некорректно, дать некрасивую верстку документа и даже упасть. В Листинге 13.2 дана полная спецификация тега "список", которую поддерживает XUL. <listbox>
<listcols> // tag and content optional
<listcol/> // can be repeated
</listcols>
<listhead> // tag and content optional
<listheader> // can be repeated
</listheader>
</listhead>
<listitem> // can be repeated
<listcell> // can be repeated
</listcell>
</listitem>
</listbox>
Листинг
13.2.
Тег "список" со всеми возможными опциями.Пары открывающих и закрывающих тегов <listitem>, <listcell> и <listheader> могут быть сокращены до одного тега с синтаксисом <tag/>, в этом случае содержимое помещается в атрибут тега. Обсудим эти атрибуты для каждого тега отдельно. Все эти теги имеют XBL-определения в файле listbox.xml архива toolkit.jar в каталоге chrome. 13.2.3 Тег <listbox>Тег <listbox> имеет следующие атрибуты: rows size seltype suppressonselect disableKeyNavigation rows и size определяют высоту списка числом строк. Вычисление size основано на высоте самой высокой строки, умноженной на значение атрибута. Это дает тот же результат, как если бы мы присвоили атрибуту minheight некоторое число пикселей для каждой строки. Каждая строка приобретет ту же высоту, что и самая высокая, т.е. все они будут равны по высоте. Атрибут size считается устаревшим, используйте вместо него rows. Тег <listbox> может изменять размер динамически, если определить атрибут rows в JavaScript. Значение атрибута rows (а также size и minheight) передается для вычислений в тег <listboxbody>, поэтому то место, которое занимает строка заголовка, в вычисление не включается. <listbox> плохо работает с атрибутом maxheight. Если теги <listbox> находятся внутри тега <hbox>, и какой-то из братских тегов <listbox> имеет атрибут maxheight меньший, чем у первого тега <listbox>, то это может вызвать ошибку и в результате плохую верстку. Если тег <listbox> имеет большие по размеру дочерние теги, рекомендуется установить величину параметра height и вообще не трогать размеры строк, Mozilla справится сама. Атрибут seltype определяет, может ли пользователь выбрать сразу несколько строк списка. Если его значение равно multiple, то это возможно. Если значение иное, может быть выбрана лишь одна строка. Атрибут suppressonselect может иметь значение true. Когда пользователь выбирает определенную строку, XBL-код этого тега генерирует событие, которое может уловить обработчик событий тега <listbox>. Этот атрибут препятствует возникновению события. Атрибут disableKeyNavigation также может иметь значение true. Это приведет к тому, что выбранная строка не изменится по сигналу с клавиатуры. Доступ к тегу <listbox> с помощью JavaScript обсуждается в разделе "Интерфейсы AOM и XPCOM". Поддержка тега <listbox> для шаблонов описывается в главе 14, "Шаблоны". 13.2.4 <listcols>Тег <listcols> является контейнером для тегов <listcol> и не имеет никакой иной цели. Он не имеет никаких специальных атрибутов и никак не отображается. Тег <listcols>, если он вообще есть, должен появиться перед любым иным содержанием <listbox>. Если этот тег есть в теге <listbox>, то это то же самое, что <listcols> <listcol flex="1"/> </listcols> В этом теге также применимы и атрибуты, свойственные шаблонам. 13.2.5 <listcol>Тег <listcol> никогда не отображается и не должен иметь никакого содержания. Он не имеет никаких собственных атрибутов. В правильно сформированном теге <listbox> число колонок определяется числом тегов <listcol/>. Тег <listcol> может использоваться еще для двух целей. Его можно использовать, чтобы присвоить колонке определенный id, и c его помощью колонке можно присвоить определенный стиль. Это можно сделать, добавив атрибут flex или присвоив атрибутам hidden или collapsed значение true. В этом теге также применимы атрибуты, свойственные шаблонам. 13.2.6 <listhead>Тег <listhead> - контейнер для тегов <listheader>. Если его нет, заголовка у списка не будет. Он не имеет никаких специальных атрибутов и иных целей. Этот тег группирует все теги <listheader> в один тег <listheaditem>. Это дает гарантию, что каждый заголовок заключен в блокоподобный тег. 13.2.7 <listheader>Тег <listheader> основан на теге <button>, он и есть по сути <button>. Колонка может иметь один тег <listheader>. Из его XBL определения видно, что если ему не приписано никакого содержания, он эквивалентен просто: <button> <image class="listheader-icon"/> <label class="listheader-label"/> <image class="listheader-sortdirection"/> </button> Только первый тег <image> может быть оформлен стилем. Атрибуты value и crop тега <label> берутся из соответствующих атрибутов тега <listheader>. Второй тег <image> оформляется стилем только одним атрибутом: sortDirection. Значение "ascending" даст стрелочку вверх. Значение "descending" стрелочку вниз. Значение "natural" (или что угодно еще) даст в результате отсутствие стрелочки. Если содержание определено, оно появится на кнопке. В этом теге также применимы и атрибуты сортировки, свойственные шаблонам. 13.2.8 <listitem>Тег <listitem> используется, чтобы определить строчку в списке. Применение любого другого тега здесь может привести к сбою Mozilla. Если тег <listitem> не имеет содержания, определенного пользователем, он имеет единственный тег <label> в качестве содержания. Вы можете определить ваше содержание как один или более вложенных тегов. В этом случае должен быть один вложенный тег на каждую колонку, и <listcell> - очевидный выбор для этого содержания. <listitem> имеет следующие специальные атрибуты: label crop flexlabel disabled type checked image selected current allowevents value Все эти атрибуты работают в одноколоночных списках, если не оговорено иное. label, crop, и disabled передаются вложенному тегу <label>. Значение атрибута flexlabel передается атрибуту flex тега <label>. Строка с атрибутом disabled, имеющим значение true, все еще может быть выбрана, но она высвечивается серым цветом. Атрибут type может иметь значение checkbox, в этом случае слева в строке появится флажок. Положение флажка не может быть изменено. Атрибут disabled со значением true даст флажок, подсвеченный серым, и в этом случае пользователь не сможет отметить его галочкой. Если тег <listitem> имеет атрибут listitem-iconic, этот тег может содержать изображение. URL этого изображения указывается атрибутом image. Оставшиеся атрибуты применимы как к одно-, так и к многоколонным спискам. Атрибут current устанавливается автоматически в значение true, когда мы выбираем строку. Если этот атрибут равен true, значит строка выбрана теперь, либо была выбрана ранее, в случае, когда разрешен множественный выбор строк. Атрибут selected также имеет значение true, если элемент выбран. Атрибут allowevents, установленный в true, позволяет событиям DOM от клика мыши передаваться сквозь тег <listitem> до содержания этой строки. Обычно тег <listitem> препятствует распространению подобных событий. Если этот атрибут установлен, текущая строка не может быть выбрана. Атрибут value хранит значение данных, представляемых тегом <listitem>. Он используется только в программах и никак не отображается. Тег <listcell> используется для определения одного элемента колонки (ячейки). Содержание колонок можно указать и с помощью тегов, определенных пользователем, но платформа Mozilla обращается к тегу <listcell> в нескольких местах, поэтому лучше использовать именно его. По умолчанию, XBL определение тега <listcell> - это единственный тег <label>, если его не заместит тег, определенный пользователем, с произвольным содержанием. Тег <listcell> поддерживает все атрибуты, которые имеет тег <listitem>, за исключением current, selected и allowevents. Чтобы добавить пиктограмму в <listcell>, используйте класс listcell-iconic. Если <listbox> имеет много колонок, флажок не будет работать, если он указан на единственном теге <listcell>. Атрибуты checkbox, icon, и label списка могут быть переопределены в обратном направлении с помощью dir="rtl". Иные атрибуты блока, например, orient, также могут быть применены к тегу <listcell>, если это, конечно, может иметь смысл. Итак, с тегом <listbox> мы на этом закончим. 13.2.10 RDF и сортировкаТег <listbox> и его "родственники" может быть подключен к RDF-документу. В этом случае тег получает содержание из данного RDF-документа. При этом данные в списке могут быть упорядочены. См. лекцию 14, "Шаблоны", где даны подробные инструкции. 13.2.11 Взаимодействие с пользователемСписки предоставляют пользователю больше возможностей для взаимодействия, нежели обычные формы. Они, как минимум, столь же гибкие, как меню. Списки поддерживают и ввод с клавиатуры, и управление мышью, и имеют специальные функции для людей с ограниченными возможностями. Навигационные клавиши включают Tab, Arrow, Paging, Home, End и пробел. Поддержка мыши включает клики и комбинации клавиша-клик, и поддержку колесика мыши. Чтобы получить доступ к специальным возможностям, определите содержимое тега <listitem> как атрибут label или тег <label>. Списки являются членами фокусного кольца текущей страницы. Если тег <listbox> не имеет выбранной строки, то, когда он получает фокус как очередной член фокусного кольца, его внешний вид не изменится, хотя он получит фокус. Выбор же строки - это тонкая материя. Если возможен выбор единственной строки, то выбор устроен так же, как в меню. Если же атрибут seltype имеет значение multiple, может быть выбрано несколько строк одновременно. Мышью можно выбрать непрерывный ряд строк, с помощью, как обычно, shift-клик, или произвольное подмножество строк, с помощью ctrl-клик. Непрерывное подмножество срок можно выбрать и с клавиатуры, с помощью комбинаций shift-стрелка. С клавиатуры нельзя выбрать произвольное подмножество строк. Только мышь способна сделать это. Одна строка списка может быть выбрана с клавиатуры с помощью нажатия клавиши символа. Список должен в этот момент иметь фокус. Нажатый символ сравнивается с атрибутом label тега <listitem> в теге <listbox>. Если первый символ атрибута label совпадает с нажатым символом, они соответствуют друг другу. Система отмечает данную строку как выбранную. Тег <listitems> считается замкнутым кольцом, подобно кольцу фокуса. Начальная точка кольца - текущий выбранный <listitem>, если он есть, в противном случае - первый <listitem> в списке. Список сканируется до тех пор, пока не найдется подходящая символу строка. Это позволяет пользователю циклично сканировать список несколько раз. Пользователь не может изменять размеры колонок многоколоночного списка, если только программист не усовершенствует тег "список" с помощью дополнительных обработчиков событий. То же самое верно и для скрытия и схлопывания колонок. 13.2.12 Интерфейсы AOM и XPCOMТег <listbox> можно использовать не только для того, чтобы представить данные, но чтобы управлять этими данными. Необходимость вводить, исправлять, уничтожать данные, получить или сохранить их означает, что спискам требуется и надежный программный интерфейс. XBL-определение тега <listbox> дает целый ряд свойств и методов, доступных на JavaScript. Многие из этих свойств имитируют действие стандартов DOM 0 и DOM 1. Они описаны в Таблице 13.2. Данная таблица соответствует версии 1.4 XBL-определения списка.
Эти свойства и методы приведены здесь, потому что графические элементы управления тега <listbox> обычно можно изменять программным путем, а эти интерфейсы отличаются от тех, которые привычны нам по web-разработкам. Нужно использовать именно эти свойства и методы, а не интерфейсы DOM 1 Node и Element, в противном случае тег <listbox> может реагировать неадекватно. Таблица не содержит ничего нового, это тот же XBL в иной форме и комментарии к нему. Важная особенность этого интерфейса - использование аргумента index. index относится ко всякому видимому элементу списка. Видимые элементы - это те прямоугольные блоки содержания списка, которые можно прокручивать для просмотра. index не соотносится ни с каким списком тегов во внутренней конструкции тега <listbox>. Для списков это различие вырождено, тривиально, поскольку каждый видимый прямоугольник содержания соотносится ровно с одним тегом <listitem>. Позже мы увидим, что подобный index в теге <tree> может не соответствовать ничему, хотя видимый блок содержания может присутствовать. В главах 7, 8, и 10 мы видели, что теги <menupopup>, <scrollbox>, и <iframe>, среди прочих, являются тегами специального, блокоподобного вида. Они примечательны тем, что поддерживают дополнительные возможности обработки их содержания. DOM-объекты этих тегов содержат свойство boxObjext, которое предоставляет особенный интерфейс. Этот особенный интерфейс и дает нам доступ к добавочным возможностям обработки контента. Тег <listbox> - еще один пример такого рода блокообразных тегов. Он поддерживает интерфейс nsIListBoxObject. Этот интерфейс дает возможность произвольного доступа к содержанию списка. Этот доступ можно также реализовать с помощью компонента @mozilla.org/layout/xul-boxobject-listbox;1 Одна из причин, почему Таблица 13.2 столь велика, заключается в том, что большинство (хотя и не все) свойства nsIListBoxObject были экспортированы в XBL-определение тега <listbox>. Они перечислены в последней трети Таблицы 13.2. В терминах объектно-ориентированного подхода, XBL-определение тега <listbox> является фасадом этого особенного интерфейса. Фактически, большинство методов и свойств в Таблице 13.2 соответствуют опубликованному XPCOM интерфейсу. Интерфейс nsIDOMXULSelectControlElement также реализован с помощью меню, радио- групп и вкладок. И лишь nsIDOMXULMultiSelectControlElement реализован с помощью объектов, которые XBL создает специально для тега <listbox>. На этом мы закончим обсуждение тега <listbox>. XUL-деревья, описываемые ниже, могут делать все то же, что и списки, и много больше. 13.3. ДеревьяЕсли тег <listbox> - это смесь концепций тегов <grid> и <menulist>, то тег <tree> - это смесь <listbox> и <iframe>. Так же, как и <listbox>, тег <tree> - это упорядоченное по вертикали множество записей. Тег <tree> позволяет графически подчеркнуть иерархическую структуру данных благодаря различной величине отступов и графическим украшениям- подсказкам. Если иерархическое выделение не используется, тег <tree> выглядит так же, как и тег <listbox>. Тег <tree> дает нам возможность управлять графическим представлением данных. Мы можем группировать и раскрывать ветви дерева интерактивно. Колонки можно переставлять, скрывать, изменять их размер, а их содержание можно сортировать и выбирать. Тег <tree> предоставляет программисту приложения множество возможностей. Свойства сортировки и отображения данных дают программисту непосредственный доступ к управлению представлением данных. Вместе с оверлеями и шаблонами тег <tree> дает в результате панель, в которой можно манипулировать данными очень динамично. Внешний вид деревьев можно модифицировать стилями в широком диапазоне. Если не рассматривать такой графический элемент управления, как <iframe>, то дерево - это самый сложный виджет XUL. 13.3.1 Внешний вид дереваЧтобы увидеть тег <tree> в работе, посмотрите на любое из следующих окошек классической Mozilla: "Настройки" (левая панель), две панели почтового клиента, окошко менеджера закладок, менеджер загрузок. Все эти окна содержат тег <tree>. На самом деле Mozilla использует в своей работе десятки деревьев. На Рисунке 13.5 показаны свойства деревьев. На этом снимке мы видим тему Modern.  Рис. 13.5. Пример <tree>, показывающий большинство особенностей. Дерево на картинке выглядит как набор колонок, подобно списку. В отличие от списка, в правом верхнем углу есть выпадающее меню. Это меню (не показано) - набор флажков, которые можно использовать, чтобы спрятать или вновь показать колонки. Дерево имеет несколько колонок специального типа. Колонка А - первичная. Первичная колонка отображает иерархическую организацию строк в дереве. Посмотрим на эту колонку поближе: мы видим четыре строки верхнего уровня: 1, 2, 7, и 9 (то есть это даже не дерево, а лес). Вторая строка имеет поддерево, которое видимо - раскрыто. Маленький направленный вниз треугольничек (стрелка) также свидетельствует о том, что поддерево раскрыто. Это поддерево имеет четыре строки, одна из которых сама имеет свое поддерево, которое также раскрыто. Наконец, это второе поддерево имеет единственную строку, также имеющую поддерево. Это последнее поддерево закрыто, схлопнуто (стрелка указывает вправо), так что из рисунка неясно, сколько строк имеет последнее поддерево. На стрелки можно кликать, открывая и закрывая поддеревья. Короткие линии между стрелками и строками обозначают для нас уровень дерева, к которому данная строка принадлежит. Наконец, мы видим, что колонка А имеет отступы, также обозначающие уровень дерева. Оставшиеся колонки не так сложны. Колонка B - обычная колонка. Колонка C - обычная колонка, но ее заголовок заменен пиктограммой. Колонка D может быть отсортирована: ее можно использовать, чтобы переупорядочить строки дерева, вопреки его исходной структуре. Это свойство сортировки обозначено маленькой стрелкой в заголовке колонки. Чтобы сортировка работала, к тегу <tree> необходимо добавить технологии, которые будут обсуждаться далее, в главе 14, "Шаблоны"; здесь она изображена только для полноты картины. Колонка E - маркер. Такая колонка содержит лишь одну пиктограмму и взаимодействует с пользователем особенным образом. Колонка F содержит тег <progressmeter>. Колонка G должна содержать флажок, но эта функциональность еще не закончена и не работает в версии 1.4. и более ранних. Скобки в названиях не являются частью конструкции, это просто часть заголовка. Полоса прокрутки справа появляется и исчезает по мере необходимости, в зависимости от количества контента в окошке. Полоса прокрутки на этом рисунке - часть тега <tree>, а не отличная от него часть chrome. Горизонтальные полосы прокрутки не поддерживаются. Мы можем теперь рассмотреть рисунок 13.5 строка за строкой. Первая интересная строчка - 3. Одна ее ячейка имеет иной цвет и рамку. Mozilla имеет специальную систему стилей для деревьев, которая описывается ниже, в разделе "Стилевые возможности" этой главы. Строка 6 является выбранной, так что дерево в настоящий момент получило фокус. Строка 7 показывает нам, что ячейка может содержать также и изображение; это не встроенная стилевая пиктограмма. На строке 7 видно также, что изображение может заместить все содержание строки и встроенное содержание тега <progressmeter> можно заместить своим. Строчка 8 (тонкая горизонтальная линия) - это <treeseparator>; он работает так же, как <menuseparator> в меню. Строчка 9 демонстрирует, что ячейка обрежет содержание, если места недостаточно. Если в ячейке очень мало места, то не будут отображены даже первые буквы содержания. Наконец, последняя строка пуста: не слишком удачная идея в реальном приложении, но технически это возможно. Ячейка дерева не может содержать произвольный код XUL. Она может содержать лишь строку текста и то, что было перечислено ранее. Она не может включать тег <box>. 13.3.2 Конструкция тега "дерево"Рисунок 13.6 повторяет Рисунок 13.5 с включенной диагностикой. С ее помощью мы можем узнать кое-что новое о внутренней структуре дерева. Заголовки колонок напоминают другие виджеты, такие как кнопки и лейблы. Очевидно, что тег <tree> не основывается на табличной структуре и отличен от тега <listbox>. 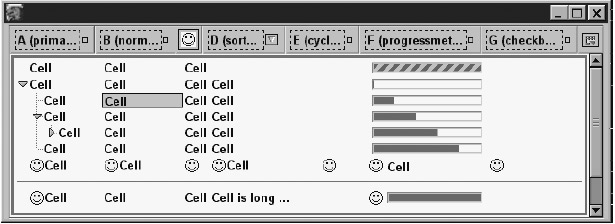 Рис. 13.6. Пример <tree> со стилями диагностики Фактически, область данных дерева напоминает тег <iframe>. Это прямоугольная область в XUL документе, чье содержание хранится отдельно от остального документа. В теге <iframe> содержание - это отдельный XUL документ. В случае дерева, контент не имеет отдельного XUL-документа, но все равно хранится отдельно от другого контента. Невозможно оформлять части дерева, используя обычные CSS2 стили. Вместо этого существует специальная система стилей. Причина в том, что каждая ячейка и строка имеют фреймы, которые не полностью описываются стандартными стилями. Так исторически сложилось при проектировании и разработке тега "дерево". Рисунки 13.5 и 13.6 требуют сотни линий кода для реализации, поэтому рассмотрим более простой пример, имеющий всего две строки, на рисунке 13.7. 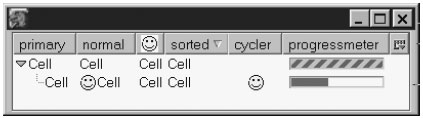 Рис. 13.7. Простой пример дерева с двумя строками. Фрагмент кода для этого рисунка приведен в листинге 13.3 <tree flex="1">
<treecols>
<treecol flex="1" id="A" label="primary" primary="true"/>
<treecol flex="1" id="B" label="normal"/>
<treecol flex="1" id="C" label="icon" class="treecol-image" src="face.png"/>
<treecol flex="1" id="D" label="sorted" sortDirection="ascending"/>
<treecol flex="1" id="E" label="cycler" cycler="true"/>
<treecol flex="1" id="F" label="progressmeter" type="progressmeter"/>
</treecols>
<treechildren id="topchildren" flex="1">
<treeitem container="true" open="true">
<treerow>
<treecell label="Cell"/>
<treecell label="Cell"/>
<treecell label="Cell"/>
<treecell label="Cell"/>
<treecell label="Cell"/>
<treecell label="Cell" mode="undetermined"/>
</treerow>
<treechildren>
<treeitem>
<treerow>
<treecell label="Cell"/>
<treecell src="face.png" label="Cell"/>
<treecell label="Cell"/>
<treecell label="Cell"/>
<treecell src="face.png" label="Cell"/>
<treecell label="Cell" mode="normal" value="40"/>
</treerow>
</treeitem>
</treechildren>
</tree>
Листинг
13.3.
Базовая конструкция тега <tree>Тег <tree> имеет вложенный тег <treecols>, в котором определены колонки, и вложенный тег <treechildren>. Идентификаторы колонок очень важны. Тег верхнего уровня <treechildren> напоминает <listbox> из <listboxbody>, за исключением того, что он определяется программистом приложения и может находиться внутри других тегов. "Элемент" дерева - это целое поддерево, тем не менее, список таких единиц - это последовательность строк. Код примера имеет единственный тег верхнего уровня <treeitem>. Атрибут container говорит нам, что эта единица - не просто строка, но тоже верхушка дерева. open говорит, что следующий уровень поддерева раскрыт. Если появится второй или третий теги верхнего уровня <treeitem>, они должны появиться после заключительного тега </treeitem>. Наше единственное поддерево верхнего уровня имеет две части: содержание строки и дочернее поддерево. Поддерево начинается со второго тега <treechildren>, но на этот раз это не поддерево, но лишь строка. Если бы было еще одно поддерево, оно появилось бы после внутреннего тега </treeitem>. XBL код тега <tree> хранится в файле tree.xml в архиве toolkit.jar в каталоге chrome. Есть и иные структурные аспекты деревьев: RDF, сортировка, кадры (views), конструкторы и шаблоны. Их описание будет дано после того, как мы рассмотрим XUL-теги деревьев. 13.3.3 Тег <tree>Все содержание дерева находится внутри тега <tree>. В одном XUL документе может содержаться более одного дерева. Тег <tree> имеет следующие особенные атрибуты: seltype hidecolumnpicker enableColumnDrag disableKeyNavigation seltype со значением multiple (значение по умолчанию) позволяет нам выбирать одновременно несколько ветвей дерева. Значение single означает, что может быть выбрана лишь одна ветвь. hidecolumnpicker со значением true схлопывает тег <treecolpicker> в правом верхнем углу дерева. enableColumnDrag со значением true позволяет нам менять колонки местами. disableKeyNavigation со значением true не позволяет выбирать колонки, используя клавиатуру. Тег <tree> и остальные подобные ему теги также поддерживают RDF и шаблоны. Атрибуты, необходимые для этого, рассматриваются в главе 14, "Шаблоны". Максимальная высота тега <tree> может быть определена с помощью стандартного для блоков атрибута height. Тег <tree> не поддерживает атрибут rows. 13.3.4 Тег <treecols>Описания колонок заключены в тег <treecols>. У него нет специальных атрибутов. Ему может быть присвоен идентификатор id, если дерево частично построено из оверлеев. Тег <treecols> - это простой тег-контейнер. Этот тег должен быть первым дочерним тегом внутри тега <tree>. Это обязательно. Тег <treecols> может содержать два типа тегов: <treecol> и <splitter>. Число тегов <treecol> в теге <treecols> дает нам число колонок в дереве. По меньшей мере один тег <treecol> присутствовать должен. Один из тегов <treecol> может иметь атрибут primary со значением "true". Если присутствует разделитель <splitter>, он должен находиться между двумя тегами <treecol>. Разделить - точка, передвигая которую мы можем изменять размеры колонок. Если присутствуют все возможные разделители, получается, что они должны чередоваться с тегами колонок. Результатом такого перетаскивания будет то, что размеры колонок по обе стороны разделителя изменятся. XBL код разделителя обеспечивает такое его поведение. Каждый разделитель должен быть оформлен классом class="treesplitter", благодаря чему этот тег имеет нулевую ширину. Если этого не сделать, заголовки колонок и сами колонки могут не соответствовать друг другу. В силу механизма, которым Mozilla идентифицирует текущий тег под курсором мыши, разделитель может быть текущим тегом, несмотря на то, что он не имеет видимого отображения. И его можно передвигать, несмотря на нулевую ширину. 13.3.5 <treecol>Тег <treecol> определяет колонку дерева. Он не может содержать тегов. Каждый тег <treecol> должен иметь уникальный id. Этот id используется платформой Mozilla. Заголовок колонки - это тег <button>, содержащий теги <label> и <image>, или только <image>, а именно те, что были оформлены классом treecol-image. Заголовки колонок могут иметь дополнительную пиктограмму, если оформлены классом list-styleimage. Тег <treecol> имеет следующие атрибуты: label display crop src hideheader ignorecolumnpicker fixed sortDirection sortActive sortSeparators cycler primary properties label определяет текст заголовка колонки. Тег <label> не может быть использован как содержание атрибута. display определяет текст, появляющийся в выпадающем меню (picker) для этой колонки. crop применяется к тегу <label> содержимого колонки. src заменяет label колонки изображением. Тег <treecol> должен быть оформлен стилем class="treecol-image", чтобы это работало. В результате использования hideheader="true" заголовок не ведет себя, как кнопка. Пространство для заголовка выделяется по-прежнему -- но заголовок больше не может быть ни схлопнут, ни спрятан. Если используется этот атрибут, атрибут label должен также отсутствовать. Этот атрибут может быть применен ко всем заголовкам колонок, и, вместе с атрибутом hidecolumnpicker, схлопнуть всю зону заголовков. ignorecolumnpicker="true" не позволит выпадающему меню прятать и вновь раскрывать колонки. fixed="true" не даст колонке возможности реагировать, если соседние с ней колонки меняют свой размер. Другими словами, эта колонка не изменит свой размер, если только все дерево не изменит размер. Это следствие поведения тега <splitter> в заголовке. Если sortActive="true", эта колонка может сортироваться. Значение sortDirection может быть ascending, descending, или normal. Если sortSeparators имеет значение true, имеет место специальный вид сортировки, когда строки, находившиеся между тегами <treeseparator>, так и останутся между этими тегами. Сортировка осуществляется автоматически, только если использовались RDF или шаблоны - см. лекцию 14, "Шаблоны". cycler="true" означает, что эта колонка является маркером и содержит только одну пиктограмму. Эта пиктограмма может вести себя подобно кнопке и иметь обработчик события onclick. Если мы кликнем маркер, строчка под указателем мыши не будет выбрана. primary="true" означает, что это первичная колонка дерева и она должна отразить иерархическую структуру данных. Этот атрибут может иметь только одна колонка в каждом дереве. атрибут properties поддерживает специальную систему стилей. См. раздел "Стилевые возможности" в этой главе. Колонки могут быть спрятаны или схлопнуты, при использовании стандартных атрибутов XUL. 13.3.6 <treechildren>Тег <treechildren> - одновременно тег для всех строк дерева и для каждого его поддерева. У него нет специальных атрибутов. Тег <treechildren> может содержать только теги <treeitem> и <treeseparator>. Его можно использовать двумя способами. Второй дочерний тег в теге <tree> обязан быть тегом <treechildren>. И дополнительный второй дочерний тег тега <treeitem> может быть только <treechildren>. Если его использовать вторым способом, <treechildren> должен иметь как минимум один тег <treeitem>. Если это не так, пиктограмма стрелочки будет вести себя непредсказуемо. Тег <treechildren> также использует специальную систему стилей. 13.3.7 Тег <treeitem>Тег <treeitem> описывает одну строку дерева. Строка это:
Этот тег может содержать либо тег <treerow> (случай 1), либо тег <treerow>, за которым следует тег <treechildren> (случаи 2 и 3). <treeitem> не может содержать несколько тегов <treerow> или <treechildren>. Специальные атрибуты тега <treeitem>: container open properties Если container имеет значение true, значит строка содержит поддерево и должна иметь тег <treechildren> как второй тег контента. Если open имеет значение true, поддерево раскрыто (случай 2). По умолчанию никакие атрибуты не установлены. Эти теги оформляются специальной системой стилей. Тег <treeitem> также поддерживает атрибуты шаблонов, например uri. См. лекцию 14, "Шаблоны". 13.3.8 Тег <treeseparator><treeseparator> прочерчивает горизонтальную линию через все дерево. Он может контролировать сортировку, как описано в главе 14, "Шаблоны". Эта горизонтальная линия не имеет отступов, так что <treeseparator> может заменить только строку верхнего уровня. Он имеет один специальный атрибут: properties Он используется в специальной системе стилей, описываемой в разделе "Возможности стилевого оформления". Подразумевается, что <treeseparator> имеет лишь визуальный смысл. 13.3.9 Тег <treerow>Тег <treerow> содержит одну строку дерева. Он может содержать только теги <treecell>. Должно быть столько же тегов <treecell>, сколько было определено колонок. Определить меньшее их количество можно, но делать это не рекомендуется. Сделав так, вы уменьшите количество видимых ячеек в строке. <treerow> имеет единственный специальный атрибут: properties Это атрибут имеет тот же смысл, что и для тега <treeitem>. 13.3.10 Тег <treecell>Тег <treecell> отвечает за содержание одной ячейки строки. В первичной колонке он не отвечает за отступы, стрелки или любые соединительные линии. <treecell> не может иметь никакого XUL-контента, за исключением специально случая, когда колонка содержит тег <progressmeter>. В этом случае автоматически добавляется тег <progressmeter>. <treecell> не может содержать тег <label>. Специальные атрибуты тега <treecell>: label src value mode allowevents properties label отвечает за содержание ячейки. Текст в ячейке не может сворачиваться змейкой, как происходит в теге <label>. src можно использовать, чтобы поместить в ячейку изображение. mode можно дать значение normal или undetermined, при условии, что данная колонка оформлена как type="progressmeter". Это дает доступ к атрибуту mode тега <progressmeter>. value - значение, в процентах, при mode="normal" для тега <progressmeter>. Если атрибут allowevents="true", событие, т.е. клик мышкой, например, который обычно высвечивает строку, будет передано глубже, к содержимому ячейки. В этом случае строка не будет выбрана. properties используется в специальной системе стилей. <treecell> также поддерживает атрибуты RDF, такие как resource и ref. См. лекцию 14, "Шаблоны". 13.3.11 Теги <treerows> и <treecolpicker>Эти теги используются только внутри XBL кода. Они применяются автоматически при верстке содержания тега "дерево". <treerows> содержит все строки дерева. Он играет ту же роль для <tree>, что <listboxbody> играет для <listbox>. <treecolpicker> содержит пиктограмму и выпадающее меню колонки. Выпадающее меню генерируется автоматически при создании дерева. <treecolpicker> имеет порядковый атрибут, установленный по умолчанию в очень большое число. Это гарантирует, что он всегда появится справа от колонок дерева. <treecolpicker> может быть оформлен стилями, как и любой XUL тег. Его пиктограмма имеет класс tree-columnpicker-icon. Нет необходимости использовать эти теги прямо в XUL документе. XBL код, воплощающий <treecolpicker> - полезное руководство, если вам будет нужно спроектировать подобный динамический виджет. 13.3.12 Более не существующие тегиКогда-то тег <tree> назывался <outliner>, но не теперь. Тег <outliner> больше не существует. Когда <tree> назывался <outliner>, <listbox> назывался <tree>, но то дерево <tree> было отлично от современного тега <tree>. Остерегайтесь путаницы с этими древними названиями в старой документации, которая иногда появляется на сайте Mozilla, в группах новостей или в базах ошибок. <treecolgroup> - старое название <treecols>. Оно еще существует в некоторых файлах chrome, но его не следует применять. Используйте вместо него <treecols>. Тег <treecolpicker> - часть XBL кода <tree>. Он используется только во внутреннем XBL коде и его не следует упоминать в XUL документах. Теги <treeindentation>, <treeicon>, <treehead>, <treecaption>, <treefoot> и <treebody> - не XUL теги. Все эти теги либо устарели, либо экспериментальны. Они не поддерживаются. 13.3.13 RDF и сортировкаКак и <listbox>, тег <tree> может быть подсоединен к DRF документу. В этом случае дерево получает содержание из этого документа. При таком условии данные дерева можно сортировать. См. лекцию 14, "Шаблоны". 13.3.14 Взаимодействие с пользователемДеревья имеют те же возможности взаимодействия с пользователем, что и списки, и много больше. Самые важные вещи из области взаимодействия с пользователем относятся больше к семантике приложения, чем к вводу с клавиатуры и нажатию кнопок мыши. Когда иерархические данные наглядно представляются в виде дерева, это позволяет нам раскапывать, суммировать и классифицировать их. Эти задачи и должны быть правильно поддержаны. "Раскапывание" данных порождает в процессе новые идеи. Когда мы кликаем по стрелочке, чтобы раскрыть поддерево, мы раскапываем данные. Таким способом мы ищем подробности об интересующем нас предмете. Иерархически представленные данные должны обладать возможностью предоставить нам эти подробности. Раскрываемая строчка не произвольна - она должна быть "о родительской строчке". Исследования показали, что человек плохо прослеживает в уме связи данных на множество уровней вниз. Лучше иметь широкое, мелкое дерево, чем глубокое, сильно структурированное, чьи поддеревья способны заполнить весь экран целиком каждое. Низкоуровневое взаимодействие, которое дает нам дерево, очень похоже на то, что дает список. Деревья поддерживают навигацию с помощью клавиатуры и мыши, и облегчают доступность (accessibility). Навигационные клавиши включают Tab, Arrow, Paging, Home, End и пробел. Мышь поддерживает клики, комбинации клавиша-клик и использование колесика. Доступность обеспечивается автоматически, поскольку тег <treecell> имеет атрибут label. Деревья - члены фокусного кольца текущей страницы. Если <tree> не имеет выбранной строки, то передача фокуса дереву от предыдущего члена фокусного кольца не даст никакого видимого эффекта, но дерево фокус получит. Ситуация может развиваться иначе в версиях старше 1.4. В качестве образца будет использовано поведение фокуса в классическом почтовом клиенте, где оно поправлено с помощью стилей. Выбор строки дерева может осуществляться по-разному. Если множественный выбор невозможен, выбор делается точь-в-точь как в меню. Если, однако, seltype имеет значение multiple, можно выбрать несколько строк одновременно. С помощью мыши это делается shift-кликом, чтобы выбрать непрерывную последовательность строк, или контрол-кликом, если нужно выбрать произвольную последовательность строк, не обязательно соседних. Непрерывная последовательность может быть выбрана и с клавиатуры, с помощью комбинации shift-стрелка. Если выбран <treeitem>, содержащий поддерево, то выбрана оказывается только первая строка, даже если поддерево схлопнуто. Определенную строку мы можем выбрать и нажимая символ клавиатуры, как в теге <listbox>. Для этого дерево уже должно иметь фокус. Нажатый единственный символ сравнивается с атрибутом label тега <treeitem> данного дерева. Если label начинается с того же символа, считается, что он подходит и строка выбирается. Такая система позволяет выбрать одну строку. Она работает следующим образом: последовательность тегов <treeitem> рассматривается как кольцевая, наподобие фокусного кольца. Начальная точка - либо уже выбранная строка, либо первая, если выбранной строки нет. Дерево сканируется до тех пор, пока не найдется подходящая строка. Это позволяет нам циклически сканировать дерево много раз. Если enableColumnDrag установлен, порядок колонок может быть переопределен просто перетаскиванием их мышкой. Просто кликните на заголовке колонки и тяните. Выпадающее меню не может передвигаться. Если между колонками присутствуют теги <splitter>, их можно использовать, чтобы изменить ширину колонок мышкой. Размер выпадающего меню не может быть изменен. Выпадающее меню, если оно не было выключено, можно использовать, чтобы скрывать и вновь показывать колонки. Скрытые колонки сохраняются все время сессии, если установлен атрибут persist="hidden". Наконец, можно осуществлять сортировку строк простым кликом мыши по заголовку колонки. 13.3.15 Интерфейсы AOM and XPCOMОсобенности скриптов в XUL-деревьях довольно сложны. Здесь мы рассмотрим их в общем и более конкретно в приложении к простым деревьям. Простые деревья - те, что не привлекают RDF или шаблоны. Все примеры в этой главе - простые деревья. Более сложные случаи рассматриваются в главе 14, "Шаблоны". Тег <tree> является примером специализированного блокообразного тега, наподобие <listbox>, <iframe> и <scrollbox>. Поэтому его DOM объект имеет свойство boxObject. Данный объект поддерживает интерфейс, специфичный для деревьев. Этот интерфейс отвечает за скролинг, навигацию, выбор и методы извлечения данных для дерева. Как и для тега <listbox>, XBL код дерева дает доступ к этому интерфейсу. К нему можно получить доступ и из компонента: @mozilla.org/layout/xul-boxobject-tree;1 nsITreeBoxObject Этот интерфейс подобен во многих отношения интерфейсу nsIListBoxObject. В отличие от тега <listbox>, лишь немногие его свойства были экспортированы в XBL код тега <tree>. Это значит, что придется работать непосредственно с nsITreeBoxObject. Этот объект доступен как свойство treeBoxObject DOM объекта тега дерево. Таблица 13.3 демонстрирует возможности этого интерфейса по управлению областью, занятой деревом на экране.
Деревья XUL имеют очень гибкие особенности реализации. Не только уже знакомые нам интерфейсы, но и некоторые важные концепции их строения также очень важно хорошо понимать. Деревья XUL сконструированы в рамках подхода, называемого Контроллер Модель-Представление (Model-View Controller, MVC), но используют свои термины для всех частей этой модели. Если коротко, этот подход означает следующее: Модель содержит данные, Представление их отображает, а Контроллер оба компонента координирует с внешним миром, т.е. пользователем. Дерево XUL воплощает концепцию MVC с помощью графического виджета, исходных (seminal) данных, конструктора (builder) и снимка (view). Снимок - это часть кода, обрабатывающая исходные данные так, чтобы их можно было отобразить графически в данный момент. В терминах MVC исходные данные и снимок - это MVC-модель, а не MVC-представление. Виджет - часть MVC-представления, комплектуемая конструктором. Конструктор также играет роль Контроллера в модели MVC. Существует единственный виджет - дерево; он изображен на рисунке 13.6. Создавая дерево, программист приложения должен работать со всеми тремя частями модели MVC: конструктором, снимком и исходными данными. Некоторые из этих концепций требуют обращения к шаблонам. В последующем обсуждении замечание, заключенное в круглые скобки (глава 14, "Шаблоны") означает, что данный вопрос подробно рассматривается в следующей главе. 13.3.15.1 Исходные данныеИсходные данные - это данные, из которых появляется содержание дерева. Это не технический, а описательный термин, введенный для того, чтобы избежать повторения технических терминов. Чтобы создать дерево, необходим тег <tree>, но данные для строк и ячеек могут появляться из трех источников: XUL, JavaScript, или RDF. Листинг 13.4 - пример данных для дерева, описанных в XUL. Содержание находится там же, где и тег <tree>. Это самый прямой путь определения содержания. Даже если мы используем оверлеи, чтобы подгрузить контент из другого документа, это все еще чистое XUL-решение. Контент дерева может быть определен и в JavaScript. Есть два способа сделать это. Первый способ - использовать интерфейс DOM 1, чтобы создать объекты элемента, обратившись к document.createElement(). Модифицируя дерево DOM, можно добавлять контент к существующему XUL-дереву. Листинг 13.4 - это пример добавления строки к дереву, созданному в Листинге 13.3. Это обычная DOM 1 операция, с помощью которой создается и добавляется новый тег. var tree = doc.getElementById("topchildren");
var item = doc.createElement("treeitem");
var row = doc.createElement("treerow");
for (var i=1; i=7; i++) // there are six columns {
var cell = doc.createElement("treecell");
cell.setAttribute("label","NewCell"+i);
row.appendChild(cell);
}
item.appendChild(row);
tree.appendChild(item); // item, row and cells now appear
Листинг
13.4.
DOM манипуляции XUL деревом.Другой способ использовать JavaScript как исходные данные для заполнения дерева содержанием - создать пользовательский снимок. Снимок - это множество методов JavaScript, которые могут использоваться для обработки контента дерева. Наконец, исходные данные могут появиться из RDF-документа. Это достигается с помощью шаблонов, используется лишь немного XUL кода (глава 14, "Шаблоны"). 13.3.15.2 Конструкторы дереваТема "конструкторы" не слишком проста, в основном потому, что они явно используются только с XUL-деревьями. А в этом случае "за деревьями не видно леса", то есть скрыты основные причины, по которым конструкторы вообще существуют. Рассмотрим простейшие случаи. Любой тег XUL начинает свою жизнь как простая текстовая строчка. Если это отображаемый визуально тег, например, <button>, в конце концов он должен проявиться пикселями на экране. Внутренний механизм Gecko отвечает за верстку, рендеринг, стилевое оформление этой трансформации. Если тег относительно прост, как <box>, его информация может быть послана непосредственно в этот механизм. Однако существует всего несколько простых XUL-тегов. Например, уже тег <button> может быть сочетанием тегов и включать в себя теги <label> и <image>. XBL код тега <button> обрабатывает эти теги и посылает результат в отображающий механизм Gecko. Таким образом в коде XBL выполняется некоторый дополнительный предварительный шаг, необходимый, чтобы Gecko мог получить что-то для своей работы. А некоторые XUL-теги требуют преобразований еще сверх тех, которые может выполнить XBL. Например, <menulist>. Какая-то часть платформы должна сконструировать и потом уничтожить выпадающие окошки тега <menulist> в момент их использования. XBL за это не отвечает. Эта функциональность должна быть частью самой платформы. Такая функциональность и называется конструктором, просто потому, что он собирает и разбирает тот контент, который должен быть отображен (или убран с экрана). Каждый XUL-тег имеет свой конструктор, по крайней мере концептуально, но в большинстве случаев конструктор тривиален. Почти всегда конструктор невидим для приложения и работает автоматически. Лишь самые сложные теги имеют конструктор, доступный в приложении. <listbox> имеет сложный конструктор, но он невидим. Только теги <tree> и <template> имеют доступные программисту конструкторы, но даже эти конструкторы доступны не всегда, а лишь часть времени. В Mozilla есть два конструктора для деревьев. Конструктор XUL-контента, или конструктор дерева по умолчанию, используется при верстке XUL-деревьев и деревьев, конструируемых с помощью DOM. Усилий программиста в этом случае не требуется. Этот конструктор сам создает дерево, используя пакетный (batch) процесс, и все дерево создается за один проход. Если DOM- операция модифицирует дерево, созданное XUL, конструктор вообще не требуется. Уже созданный код сам по себе достаточно умен, чтобы реагировать на эти изменения самостоятельно. Этот конструктор деревьев невидим. У него нет XPCOM-компонента или интерфейсов. Он не программируем. Ему присвоено имя, только чтобы отделить его от конструктора шаблонов. Контент-конструктор, или конструктор дерева по умолчанию, это часть Mozilla, которая выполняет функции конструктора, когда никакого специализированного, доступного конструктора нет. Конструктор XUL-шаблонов (глава 14, "Шаблоны") используется для создания любого контента, основанного на шаблоне, включая деревья. Он возникает автоматически при использовании шаблонов. Он имеет специализированную версию, применяемую при верстке деревьев, которая и называется конструктором дерева. Конструктор дерева должен был бы иметь какое-то более описательное имя, например, builder-for-special-combination-of-template-and-tree. Конструктор дерева может создавать дерево "лениво", то есть части дерева остаются несозданными и неотображенными до тех пор, пока реально не понадобятся. Конструктор дерева доступен программисту. Для своей работы он может использовать контент-конструктор. Но конструктор дерева может выполнять свою работу и самостоятельно, полагаясь на иные части кода. Он имеет программируемый компонент: @mozilla.org/xul/xul-tree-builder;1 Интерфейс конструктора (глава 14, "Шаблоны") для этого объекта: nsIXULTemplateBuilder nsIXULTreeBuilder Второй конструктор - то, что мы используем в работе с деревом. Если конструктор существует для конкретного дерева, то свойство builder соответствующего DOM-элемента будет содержать этот конструктор. 13.3.15.3 СнимкиКонструктор должен сделать всю работу, чтобы создать дерево из исходных данных. Но он может и передать часть работы субподрядчику, который специализируется именно на подготовке данных к отображению. В этом случае конструктор освобождается и может тратить свое время более эффективно, руководя процессом. Этот субподрядчик в данном случае называют снимок (a view). Он дает нам представление, или взгляд на исходные данные, это не взгляд на требуемый графический (GUI) результат. В терминах объектно-ориентированного программирования такой подход называется делегированием. Без части, называемой снимок, конструктор неполон и не может выполнить никакой работы. Без конструктора снимок готов к работе, но у него нет "начальника", который скажет, что, собственно, делать. Снимок используется конструктором, но его может задействовать и программист. В некоторых случаях снимок может быть программистом создан. В любом случае, снимок должен иметь интерфейсы: nsITreeView nsITreeContentView В таблице 13.4 приведены свойства, создаваемые XBL-определением тега <tree> для поддержки снимков.
Если один снимок заменяется другим, теоретически следует обновить все эти свойства. На практике достаточно обновить свойство treeBoxObject.view или свойство view и избегать использования остальных. Таблица 13.5 описывает интерфейс, представляемый снимком.
Mozilla имеет полдюжины снимков, написанных на C/C++, и дюжину - на JavaScript. Один специальный снимок принадлежит конструктору XUL- контента. Его называют просто "tree content view", это снимок для доступа к содержимому дерева, построенному на XUL-контенте. Этот простой снимок - не полный XPCOM компонент; это просто часть конструктора XUL-контента. Он, однако, полностью поддерживает описанные выше интерфейсы. Когда конструктор XUL контента строит дерево, объект с этим интерфейсом присоединяется к свойству view DOM объекта <tree>. Этот снимок доступен программисту приложения. Он используется конструктором во время конструирования дерева, и может быть использован им после того, как дерево появится на экране. Существует одно ограничение по использованию этого снимка. Он - read-only система. Метод снимка isEditable() вернет значение false; это означает, что метод снимка set-CellText() не сделает ничего. Методы, способные изменять данные, могут быть вызваны внутри системы, но не программистом. Также, из-за того способа, каким эта система взаимодействует с деревом, методы данного интерфейса не могут быть заменены методами, определенными пользователем. Все, что мы можем делать с этим интерфейсом - извлекать информацию о дереве. Если снимок должен быть перезаписываемый, или мы создаем свой, он должен быть основан на шаблонах (глава 14, "Шаблоны"). Не только снимок содержания дерева, но и многие специфичные для конкретного приложения XPCOM-компоненты имеют доступ к интерфейсу nsITreeView и могут использоваться как готовые к употреблению снимки. Это, однако, очень специфичные для каждого приложения компоненты. Их использование требует внимательного изучения кода существующих приложений, например, почтового клиента. В версии 1.4 компоненты, имеющие снимок содержания дерева, это: @mozilla.org/addressbook/abview;1 @mozilla.org/filepicker/fileview;1 @mozilla.org/inspector/dom-view;1 @mozilla.org/messenger/msgdbview;1?type=quicksearch @mozilla.org/messenger/msgdbview;1?type=search @mozilla.org/messenger/msgdbview;1?type=threaded @mozilla.org/messenger/msgdbview;1?type=threadswithunread @mozilla.org/messenger/msgdbview;1?type=watchedthreadswithunread @mozilla.org/messenger/server;1?type=nntp @mozilla.org/network/proxy_autoconfig;1 @mozilla.org/xul/xul-tree-builder;1 Чтобы использовать эти компоненты, за исключением последнего (используемого по умолчанию), мы настоятельно рекомендуем сначала внимательно изучить, как они применяются в файлах chrome. Директория chrome классической Mozilla также содержит множество реализаций nsITreeView на чистом JavaScript, их тоже можно изучить. Функциональность панели Navigator View | Page Info имеет пять снимков (в файле pageInfo.js архива comm.jar в директории chrome) и ее легче всего изучить, см. также страницу Info.xul. DOM-инспектор имеет два снимка (в jsObjectView.js и stylesheets.js), XUL <textbox type="autocomplete"> имеет один (файл autocomplete.xml) и Navigator about:config UR - один (в файле config.js). Дебаггер JavaScript и некоторые другие инструменты, например, Component Viewer также имеют реализации функции снимка на JavaScript. Некоторые приложения на JavaScript тоже реализовывали собственные снимки, которые мы можем использовать. Эти примеры помогут уменьшить количество работы, необходимой для реализации снимка. 13.4 Возможности стилевого оформленияMozilla имеет специальную систему стилей для деревьев. Списки, напротив, оформляются обычными стилями. 13.4.1 Тег <listbox>Система списков в Mozilla не имеет дополнений, отличных от системы стилей CSS2. Но она, однако, имеет множество стилевых правил и тегов, к которым эти правила применимы. Правила можно посмотреть в файле xul.css в toolkit.jar и в listbox.css глобальной темы (т.е. в classic.jar). Все эти файлы находятся в каталоге chrome. 13.4.2 Тег <tree>Язык XUL имеет одну дополнительную характерную функциональность. Эта функциональность используется для оформления деревьев, которые оформляются не так, как все иные теги. Тело данного дерева, описанное как тег <treechildren>, может быть оформлено прямо из селектора тега <treechildren>. Такую возможность дают стилевые расширения. Оформление реализуется с помощью новых псевдо-классов. Вот пример стиля дерева, изображающего граф персонала компании. Если служащий был нанят недавно, то строка с его или ее информацией подсвечена желтым: treechildren:-moz-tree-row(hired) { background-color : yellow };
Псевдо-класс -moz-tree-row указывает то, что должно быть оформлено, в данном случае строку дерева. Этому селектору передается список из нуля или более параметров. Каждый из параметров - текстовая строка. Эта же текстовая строка может быть в числе аргументов ключевого слова properties. Например, <row properties="hired,causeNewDept,dateJune">...</row> Любая и каждая из строк дерева, имеющая в property аргумент hired будет оформлена согласно данному правилу, в том числе строка из нашего примера. Если правило будет выглядеть так: treechildren:-moz-tree-row(hired,dateJuly) { background-color : yellow };
Тогда строка не будет оформлена, потому что она не содержит обоих свойств, перечисленных в правиле. Чтобы встроенные в систему стили работали, требуются три части информации:
13.4.2.1 Псевдо-классы деревьевТаблица 13.6 перечисляет псевдо-селекторы дерева, которые являются дополнением Mozilla к стандарту CSS2.
13.4.2.2 Встроенные имена свойствCSS2 использует зарезервированные ключевые слова, а не произвольные строки для большинства целей. Важно помнить, что свойства в стилевом оформлении дерева - наоборот, просто произвольные строки, назначаемые разработчиком приложения. Они зависят от приложения и не имеют специального значения в стилевой системе. Некоторая работа по именованию свойств все же проделана. Специальные имена свойств автоматически присваиваются содержанию дерева в момент его создания и когда вы с ним взаимодействуете. Эти имена, тем не менее, ничего не означают в системе стилей. Они имеют смысл только для использования в определенных пользователем псевдо- селекторах. Эти имена автоматически добавляются к списку свойств Mozilla и могут быть выбраны точно так же, как и свойства, определенные самим пользователем. Таблица 13.7 перечисляет их.
Вспомним, что в простой древовидной структуре есть два вида узлов, или нод. А именно, внутренние ноды, содержащие другие ноды, и листья, содержащие данные. Узлы в деревьях XUL либо внутренние, либо листья, но не то и другое вместе. Существует вторая группа автоматически доступных свойств. Все id всех колонок дерева доступны тем же методом, что и свойства строк. Нужно только следить, чтобы эти id были правильными именами в смысле CSS2. Несмотря на то, что встроенные свойства можно использовать, вы вправе придумать собственные. 13.4.2.3 Соответствующие свойства CSSТретий аспект этой особенной стилевой системы довольно хитрый. Каждый из псевдо-классов поддерживает лишь небольшое число стилевых свойств CSS2. Если выбрать неподдерживаемое свойство, ожидаемого эффекта не будет. В таблице 13.8 описывается, какие свойства CSS2 доступны для каждого псевдо-класса.
Совмещая таблицы 13.6, 13.7, и 13.8, получим следующий пример, содержащий только имена, присвоенные Mozilla: treechildren:-moz-tree-cell(leaf,focus) { background-color : red; }
Этот правило означает, что каждая строчка, являющаяся листом дерева и имеющая фокус, изменит цвет фона на красный. Поскольку стили фона поддерживаются ячейкой дерева, это правило сконструировано верно и даст желаемый эффект. Сравним этот пример с предыдущим, который использовал стиль, определенный пользователем, состоящий из известной цели и правильного псевдо-селектора, но использующий строку имени свойства, характерную только для данного приложения. 13.4.3 Встроенная поддержка темВплоть до версии 1.4 в деревьях не реализована встроенная поддержка тем на платформе Microsoft Windows XP. Если бы темы поддерживались, стилевое свойство -moz-appearance могло бы иметь следующие значения: listbox listitem treeview treeitem treetwity treetwistyopen treeline treeheader treeheadercell treeheadersortarrow 13.5 Практика: Вкладка keywordsЭтот раздел "Практика" посвящен стандартному XUL, использующему обычные скрипты, на котором мы смастерим теги <listbox> и <tree>. Сначала напишем статическую страничку на чистом XUL, а затем усовершенствуем ее, включив скриптовые эффекты. И еще немножко поэкспериментируем. Наконец, пришло время завершить верстку и содержание диалогового окна NoteTaker. До этих пор вкладка Keywords тега <tabbox> содержала только место для тега. Мы это поправим, добавив список, дерево и еще некоторые элементы формы. Вкладка Keywords позволяет нам добавлять и удалять ключевые слова из текущей заметки. Она также перечисляет текущие ключевые слова. Наконец, она высвечивает ключевые слова, связанные с текущими, т.е. что-то вроде подсказки для пользователя. Чтобы спроектировать эту вкладку, мы должны вернуться к главе 2, "Верстка XUL", начать с грубого наброска и затем разработать внешний вид, статический контент, элементы формы и так далее. Мы не будем повторять здесь весь процесс, но лишь суммируем основные результаты. <textbox> позволяет нам ввести ключевое слово. <listbox> высвечивает текущий набор слов Кнопка Add копирует содержание тега <textbox> в список <listbox> как новый элемент. Кнопка Delete убирает содержание <textbox> из списка, если оно там есть. Клик на строке списка <listbox> копирует ее в <textbox>. Тег <tree> будет высвечивать слова, связанные с текущим словом в списке <listbox>. Оба тега, и <listbox> и <tree>, будут иметь динамически изменяемый контент. Здесь мы реализуем это с помощью JavaScript, DOM и снимка содержания дерева. Пока что слова, связанные с текущим, мы будем брать из небольшого, фиксированного множества слов. В следующей главе мы заместим часть кода решением получше, основанным на шаблонах. Суммируя все требования, мы получим блок диалога на рисунке 13.8. 13.5.1. Верстаем <listbox> и <tree>Не откладывая дела в долгий ящик, покажем структуру панели Keywords в Листинге 13.5. <tabpanel>
<vbox>
<hbox>
<vbox>
<description value="Enter Keyword:"/>
<textbox id="dialog.keyword"/>
<hbox>
<button id="dialog.add" label="Add"/>
<button id="dialog.delete" label="Delete"/>
</hbox>
</vbox>
<vbox>
<description value="Currently Assigned:"/>
<listbox/>
</vbox>
</hbox>
<description value="Related:"/>
<tree/>
</vbox>
</tabpanel>
Листинг
13.5.
Содержание новой панели диалога Edit.Вкладка сверстана из двух блоков, сложенных вертикально. Верхний блок имеет левую и правую половины. В этом листинге теги <listbox> и <tree> для краткости не заполнены. Содержание тега <listbox> приведено в листинге 13.6. <listbox id="dialog.keywords" rows="3"> <listitem label="checkpointed"/> <listitem label="reviewed"/> <listitem label="fun"/> <listitem label="visual"/> </listbox>Листинг 13.6. Статический контент тега <listbox> для текущих ключевых слов NoteTaker. В полной версии NoteTaker эти слова будут извлечены из RDF-файла, полученного из тех слов, которые нам предстоит ввести вручную. Здесь мы начнем с нескольких фиксированных слов. Подобным образом, для тега <tree> мы начнем с фиксированного набора связанных слов. Содержание тега <tree> показано в Листинге 13.7. Рисунок 13.8. Приблизительная диаграмма, демонстрирующая <list> и <tree> технологии. 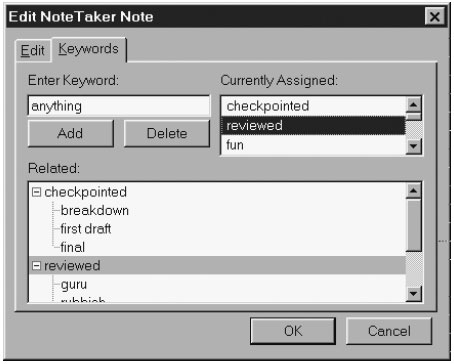 Рис. 13.8. Приблизительная диаграмма, демонстрирующая <list> и <tree> технологии. <tree id="dialog.related" hidecolumnpicker="true" seltype="single" flex="1">
<treecols>
<treecol id="tree.all" hideheader="true" flex="1" primary="true"/>
</treecols>
<treechildren flex="1">
<treeitem container="true" open="true">
<treerow>
<treecell label="checkpointed"/>
</treerow>
<treechildren>
<treeitem>
<treerow>
<treecell label="breakdown"/>
</treerow>
</treeitem>
<treeitem>
<treerow>
<treecell label="first draft"/>
</treerow>
</treeitem>
<treeitem>
<treerow>
<treecell label="final"/>
</treerow>
</treeitem>
</treechildren>
</treeitem>
<treeitem container="true" open="true">
<treerow>
<treecell label="reviewed"/>
</treerow>
<treechildren>
<treeitem>
<treerow>
<treecell label="guru"/>
</treerow>
</treeitem>
<treeitem>
<treerow>
<treecell label="rubbish"/>
</treerow>
</treeitem>
</treechildren>
</treeitem>
<treeitem container="true" open="true">
<treerow>
<treecell label="fun"/>
</treerow>
<treechildren>
<treeitem>
<treerow>
<treecell label="cool"/>
</treerow>
</treeitem>
</treechildren>
</treeitem>
</treechildren>
</tree>
Листинг
13.7.
Статический контент тега <tree> для слов, связанных с текущим.Слова в этом дереве сгруппированы в иерархическую структуру, но мы не подразумеваем, что дочерние ключевые слова являются уточнениями родительских. Заманчиво так думать о них. Однако они просто связанные, родственные концепции. Web-страничка может получить пометку с ключевым словом "гуру", но не словом "просмотрено", если мы решим, что автор странички широко известен, а вовсе не то, что содержание странички нам хорошо известно. Иерархическое представление данных как нельзя лучше подходит для иерархически организованных данных, но может использоваться и для данных другого типа. Мы используем его, чтобы представить связи, формирующие простую сеть. Вместо того чтобы рассматривать сеть целиком, мы раскрываем ее части шаг за шагом, начиная из различных точек. Это соответствует RDF запросам, описываемым ниже (глава 14, "Шаблоны"), но здесь реализуется знакомыми нам XUL и JavaScript технологиями. 13.5.2. Систематическое использование обработчиков событийВот как этот диалог будет работать. Левая верхняя часть - место, где мы вводим новое ключевое слово. Клик по кнопке Add добавит набранное слово в список вверху справа; клик по Delete удалит его из списка. Клик по слову в списке скопирует его в <textbox>. Если в списке выбрано слово, то соответствующее слово выбирается в дереве и дерево прокручивается так, чтобы высветить его. Клик по слову в дереве также копирует его в форму ввода. Все эти действия можно реализовать как команды. Некоторые из них тривиальны. Это был бы перебор - делать каждый фрагмент кода командой. Никакие из описываемых действий не выглядят как формальные "транзакции", "инструкции", "операции". Это просто клики по кнопкам. Мы реализуем их с помощью обычных обработчиков событий. Мы могли бы добавить обработчики событий в каждый тег <listbox> и <tree> вот так (onclick= ...), но мы этого делать не будем. Снимок содержания дерева также поддерживает обработку определенных действий, что напоминает приспособленные к случаю команды (см. методы снимка дерева, начинающиеся с префикса performAction). Для наших простых событий нам нужно: onclick on the Add <button> onclick on the Delete <button> onselect on the <listbox> onselect on the <tree> Вместо того чтобы использовать XUL синтаксис, мы можем сделать более интересную вещь. Будем использовать "EventTarget" интерфейс DOM 2 Events, в частности, addEventListener() метод. Этот метод доступен для каждого объекта DOM Element, чему соответствует большинство тегов XUL. Используя только скрипты, мы установим все обработчики событий, когда диалоговый блок Edit впервые загружается. В Листинге 13.8 показано, как это сделать. var ids = {};
function init_handlers() {
var handlers = [
// id event
["dialog.add", "click", add_click],
["dialog.delete", "click", delete_click],
["dialog.keywords", "select", keywords_select],
["dialog.related", "select", related_select]
];
for (var i = 0; i < handlers.length; i++) {
var obj = document.getElementById(handlers[i][0]);
obj.addEventListener(handlers[i][1], handlers[i][2], false);
ids[handlers[i][0]] = obj;
}
// also spot this final tag
ids["dialog.keyword"] = document.getElementById "dialog.keyword");
}
window.addEventListener("load",init_handlers, true);
Листинг
13.8.
Установка обработчиков событий.Функция init_handlers() - это обработчик событий, стартующий, когда документ впервые загружается. Стартуя, он запускает еще пять обработчиков, используя id тегов, названия событий и функции, перечисленные в массиве обработчиков. Эти функции зависят от единственного аргумента, а именно объекта Event. В случае нашей простой панели каждый обработчик используется только в одном месте, так что объект Event не так уж и полезен. Функция также сохраняет в объекте ids DOM-объекты для каждого обработчика. Это сделано для удобства получения в дальнейшем таких объектов. Опишем эти обработчики по очереди. Списки и деревья - объекты более сложные, чем простая кнопка, поэтому закатаем рукава - там очень много кода. Другие программные среды предоставляют свои библиотеки, заголовочные файлы, модули; для Mozilla же существует документация на XBL, DOM - и эта книга. В листинге 13.9 приведен код функции обработчика add_click(): function add_click(ev) {
var listbox = ids["dialog.keywords"];
var textbox = ids["dialog.keyword"];
// getRowCount() workaround
var items = listbox.childNodes.length;
if (textbox.value.replace(/^ *$/,"") == "" )
return; // don't add pure whitespace
for (var i = 0; i < items; i++) {
if (listbox.getItemAtIndex(i).label == textbox.value )
return; // already exists
}
listbox.appendItem(textbox.value, textbox.value);
listbox.scrollToIndex(items > 1 ? items - 2 : items);
}
Листинг
13.9.
Обработчик add_click() для ключевых слов.Эта функция добавляет набранное слово в список существующих слов. Она просматривает элементы списка, чтобы проверить, нет ли там уже такого элемента, и если нет, то добавляет его и прокручивает список так, чтобы мы могли видеть появившийся элемент. Большинство вызовов этой функции взяты из Таблицы 13.2, но нам пришлось заглянуть и в XBL-код тегов <listitem> и <textbox>, чтобы обнаружить свойства label и value. Нет в мире совершенства, и в то время когда мы собирали материал для этого курса, в XBL методе getRowCount() тега <listbox> была ошибка, которая, вероятно, уже исправлена к настоящему времени. Эта функция возвращает полное число элементов списка (когда работает правильно). Чтобы обойти эту ошибку, мы обратились к уровню AOM, то есть использовали базовые XML методы из стандарта DOM 1. Третья строчка кода возвращает объект DOM 1 Core NodeList, чье свойство "длина" является числом дочерних элементов тега <listbox>. В данном случае это работает правильно, поскольку мы знаем, что в нашем списке нет тегов <listcols>. Листинг 13.10 показывает код обработчика delete_click(). function delete_click(ev) {
var listbox = ids["dialog.keywords"];
var textbox = ids["dialog.keyword"];
var items = listbox.childNodes.length;
for (var i = 0; i < items; i++)
if ( listbox.getItemAtIndex(i).label == textbox.value ) {
listbox.removeItemAt(i); return;
}
}
Листинг
13.10.
Код обработчика delete_click().Этот обработчик не слишком отличается от add_click(). Он удаляет элемент из списка. Листинг 13.11 показывает код обработчика keywords_select() function
keywords_select(ev) {
var listbox = ids["dialog.keywords"];
var textbox = ids["dialog.keyword"];
var tree = ids["dialog.related"];
var items = document.getElementsByTagName('treecell');
var item = null,
selected = null;
try { listbox.currentItem.label; }
catch (e) { return; }
textbox.value = listbox.currentItem.label;
var items = document.getElementsByTagName('treecell');
for (var i = 0; i < items.length; i++) {
if (items.item(i).getAttribute("label") == textbox.value) {
item = items.item(i).parentNode.parentNode; break; }
}
if ( item ) { selected = item;
if ( tree.view.getIndexOfItem(item) == -1 ) {
while (item.tagName != "tree") {
if (item.getAttribute("container") != "")
item.setAttribute("open","true");
item = item.parentNode.parentNode;
}
}
// tree.currentIndex = tree.view.getIndexOfItem(selected);
// only supplies the focus,not the selection.
i = tree.view.getIndexOfItem(selected);
tree.treeBoxObject.selection.select(i);
tree.treeBoxObject.ensureRowIsVisible(i);
}
}
Листинг
13.11.
Код обработчика keywords_select()Данная функция копирует label текущего выбранного элемента списка в текстовый блок. Это занимает одну строчку кода. Остальные ищут и высвечивают это же слово в дереве, если оно существует. Интерфейс снимка дерева, описанный в Таблице 13.4 работает только на раскрытых элементах дерева (не включая те, что скрыты в результате скролирования). Если слово невидимо в настоящий момент, интерфейс осмотра не найдет его. Поэтому нам приходится использовать DOM для поиска по дереву. Когда мы находим подходящий элемент, мы можем работать со снимком дерева, чтобы управлять его картинкой. При копировании выбранного слова мы получаем еще одну неприятную проблему со списком. XBL-свойство currentItem реализовано некорректно. А именно, оно неверно работает, если список не имеет текущего выбранного элемента. Хотя это и не очевидно, но обращение к данному методу даст сообщение об ошибке в консоли, если не принять специальных мер. Эта ошибка возникает, потому что обработчик onselect вызывается и в том случае, когда список скролируется. Блок try{} этот специальный случай обрабатывает и отключает обработчик за ненадобностью. Когда мы ищем слово, нам нужно показать строку, его содержащую. Мы начинаем с <treeitem> и достигаем вершины дерева, раскрывая все встретившиеся контейнеры с помощью open="true". Опять же это делается средствами DOM 1 Core. После того, как элемент дерева с искомым словом становится видимым, он становится видимым и через интерфейс снимка. В конце концов, мы выбираем строчку дерева с клавиатуры. Мы видим ее и соседние слова, которые тоже могут быть значащими, на один уровень выше и ниже нашего слова. Чтобы это сделать, мы используем интерфейс снимка дерева, который предоставлен нам свойством XBL tree.view. Мы могли бы достичь того же результата так же просто (чуть более многословно), используя метод AOM tree.treeBoxObject, но тогда пришлось бы обращаться и к методу XPCOM's QueryInterface(), для доступа к интерфейсу этого объекта. Так что мы выбираем короткий путь. Мы не можем задействовать XBL-свойство tree.currentInde, чтобы выбрать строку дерева, потому что в этом свойстве хранится строка, имеющая фокус, но не высвеченная строка. Если мы поэкспериментируем, то увидим прерывистую линию, появившуюся вокруг правильной строчки, показывающую, что фокус на месте. Приходится вместо этого использовать объект AOM treeBoxObject.selection, который реализует интерфейс nsITreeSelection. Простой метод select() высвечивает нужную строку. Наконец, мы возвращаемся к AOM treeBoxObject и прокручиваем строку так, чтобы она не была обрезана краем окошка окружающего дерево. Листинг 13.12 показывает код обработчика related_select(). function related_select(ev) {
var textbox = ids["dialog.keyword"];
var tree = ids["dialog.related"];
textbox.value = tree.view.getCellText(tree.currentIndex, "tree.all");
}
Листинг
13.12.
Код обработчика related_select().После keywords_select() код обрабртчика related_select() выглядит очень просто. Он подбирает текущее выбранное слово из снимка дерева и копирует его значение в текстовый блок. Никаких DOM-операций. На этом мы закончим описание логики работы обработчиков событий для панели Keywords. Некоторые команды, такие как notetaker-save и notetaker-load, нуждаются в обновлении, чтобы учесть эту новую вкладку. Это мы отложим до тех пор, пока не реализуем обработку данных на основе RDF в следующей главе. 13.5.3. Списки и деревья под управлением данныхТеперь мы создали блок диалога так, что основная его нормальная функциональность реализована, но начальные ключевые слова ограничены статически определенными тегами XUL. Наша конечная цель - заполнять этот контент из RDF, но для краткого эксперимента мы воспользуемся JavaScript. Достаточной причиной для такого эксперимента служит проблема связанных слов. Если A родственник B, то B тоже, конечно, родственник A. Хотя иерархический XML - не лучшее средство для представления таких двунаправленных связей, мы хотим, чтобы наш виджет дерево показывал связи в обоих направлениях. Картинка дерева по-прежнему будет организована иерархически (иначе и не может быть), но наши предварительные преобразования позволят заполнить виджет более качественно организованной информацией. До сих пор для нас единственным средством заполнить дерево информацией остаются DOM операции нижнего уровня. Это иногда называют динамическим списком. Чтобы заполнить дерево, мы можем использовать его снимок. Поскольку мы сами создадим этот снимок, это будет снимок дерева для конкретного приложения, или пользовательский снимок. Существует несколько способов сделать это. Например, библиотеки JavaScript в cview и DOM Inspector tools имеют такие объекты JavaScript, чтобы можно было легко разрабатывать снимки дерева для конкретного приложения. Некоторые древоподобные данные, такие как данные IMAP и SNMP, накладывают ограничения на производительность обработки или функциональность, что необходимо учитывать при реализации. Но здесь мы сталкиваемся с чистым, базовым случаем. В терминах подхода MVC, "Контроллер Модель-Представление", мы реализуем MVC-модель как простую JavaScript структуру данных и для <tree> и для <listbox>. MVC-Представление будет построено как (a) базовая система рендеринга Mozilla, (b) DOM иерархия и (c) специальные блочные объекты для тегов <listbox> и <tree>. Для тега <listbox> стандартный DOM интерфейс - это плоть и кровь того, на чем будет основано наше MVC-представление. В случае дерева нам нужно лишь создать конкретный снимок, чтобы реализовать MVC-представление. Наконец, MVC для списка нам предстоит создать, в то время как для дерева это уже существующий конструктор, так что нам ничего не придется здесь делать вообще. Перед тем как действовать, нужно выключить созданные ранее обработчики событий. Здесь они не потребуются. // window.addEventListener("load",init_handlers, true)
Также нужно удалить существующий статический контент для тегов <listbox> и <tree> в XUL документе. Эти теги уменьшатся до вот такого XUL фрагмента: <listbox id="dialog.keywords" rows="3"/>
<tree id="dialog.related" hidecolumnpicker="true" seltype="single" flex="1">
<treecols>
<treecol id="tree.all" hideheader="true" flex="1" primary="true"/ >
</treecols>
<treechildren flex="1"/>
</tree>
Как обычно, нам нужен некий инициализационный код, чтобы все установить. Этот код показан в Листинге 13.13. var listdata = ["checkpointed", "reviewed", "fun", "visual" ];
var treedata = [
[ "checkpointed", "breakdown" ],
[ "checkpointed", "first draft" ],
[ "checkpointed", "final" ],
[ "reviewed", "guru" ],
[ "reviewed", "rubbish" ],
[ "fun", "cool" ],
[ "guru", "cool" ]
];
function init_views() {
var listbox = document.getElementById("dialog.keywords");
var tree = document.getElementById("dialog.related");
listbox.myview = new dynamicListBoxView();
listbox.mybuilder = new dynamicListBoxBuilder(listbox);
listbox.mybuilder.rebuild();
tree.view = new customTreeView(tree);
}
window.addEventListener("load",init_views, true);
Листинг
13.13.
Инициализация виджета ключевых слов под управлением данных.Массивы listdata и treedata содержат исходные данные для контента списка и дерева. В этом примере контент все еще статический, но такой код легко модифицировать, так чтобы динамические изменения данных также передавались в виджет. Пары значений в переменной treedata - это пары родственных слов. Если первую из них слегка изменить, получится: <- "checkpoint", related, "breakdown" -> А это, заметим, потихоньку ведет нас в сторону RDF. Тем не менее, в этом примере RDF еще нет. Функция init_views() создает три пользовательских JavaScript объекта - два для списка и один для дерева. Для дерева эдесь дела нет, потому что оно имеет встроенный конструктор, который вызывается автоматически, когда тег <tree> показывает картинку. Список тоже имеет конструктор, но он не будет доступен для программиста приложения, до тех пор пока мы не узнаем про шаблоны. Мы использовали свойства myview и mybuilder, чтобы подчеркнуть, что в случае списка мы ничего не перезаписываем. Этот инициализационный этап выполняется в тот момент, когда документ загружается, и нет никаких обработчиков событий, которые стартуют позже; см., однако, раздел "Пользовательский снимок дерева". 13.5.3.1. Динамический списокВсе строчки динамического списка порождаются скриптом. Скрипт должен реализовать обе части, и снимок, и конструктор. Они не только выполняют свою работу, но и дают нам представление о том, как устроен более сложный случай дерева. В случае дерева конструктор (а иногда и снимок) спрятаны в коде платформы. Список полностью выявляет для нас эти объекты (поскольку мы их сами и создаем), и мы можем представить по аналогии, как они работают в случае дерева. Первый объект, показанный в листинге 13.14 - это снимок объекта "список". function dynamicListBoxView() {}
dynamicListBoxView.prototype = {
get rowCount () {
return listdata.length;
},
getItemText: function (index) {
return listdata[index];
}
};
Листинг
13.14.
JavaScript-объект для снимка динамического списка.Этот объект является простым случаем абстрактного представления данных. Исходные данные спрятаны за интерфейсом снимка. Однако данный объект делает не только это. Он дает нам интерфейс, выраженный в терминах видимых нам в списке строк или единиц. Эта ассоциация с видимым прямоугольником строк списка и делает его снимком. Нам удобно, чтобы объект оперировал с массивом данных, и чтобы каждый элемент массива в точности соответствовал единице списка. Если, однако, массив будет заменен другой, более сложной структурой данных, наш объект все еще останется снимком. Потому что его неизмененный интерфейс будет предоставлять внешнему миру ряд единиц списка, выглядящий как простой ряд видимых строк. Сам по себе снимок ничего не делает. Его использует конструктор. Конструктор описывается в Листинге 13.15. function dynamicListBoxBuilder(listbox) {
this._listbox = listbox;
}
dynamicListBoxBuilder.prototype = {
_listbox : null,
rebuild : function () {
var rows, item;
while (_listbox.hasChildNodes())
_listbox.removeChild(_listbox.lastChild);
rows = _listbox.myview.rowCount;
for (var i=0; i < rows; i++) {
item = document.createElement("listitem");
item.setAttribute("label",
listbox.myview.getItemText(i));
_listbox.appendChild(item);
}
}
}
Листинг
13.15.
JavaScript-конструктор для динамического списка.Конструктор так же прост - он содержит всего один метод: rebuild(). Когда вызывается rebuild(), он обрабатывает DOM 1 Core Element объект. Сначала он уничтожает все существующие строчки; затем вновь наполняет его списком обновленных строк. Здесь мы предполагали, что тег <listbox> имеет только дочерние теги <listitem> и не имеет заголовков колонок. В нашем случае это верно. И вновь заметим, что удобно, но не необходимо, чтобы каждая высвечиваемая строчка соответствовала в точности одному DOM элементу (элементу тега <listbox>). Когда конструктор выполняет работу, он основывается полностью на снимке. Все, что конструктор знает о контенте, который нужно отобразить на экране, он получает из снимка. И снимок, и конструктор можно улучшить так, чтобы список можно было изменять после того, как он создан. В нашей реализации обновление списка требует, чтобы (a) массив был бы изменен и затем (b) вновь была бы вызвана функция rebuild() конструктора. Каждое такое изменение перерисовывает список с нуля. Чтобы сделать частичное изменение, в объект "конструктор" следует внести дополнительные методы и создать целую систему, чтобы конструктор знал, когда, куда и какие изменения вносить. 13.5.3.2. Пользовательский снимок дереваДерево сложнее для понимания, чем динамический список. Некоторые его части для нас уже реализованы: конструктор и снимок. И оба они нужны, когда мы мышкой раскрываем и схлопываем части дерева, или скролируем его. Когда раскрываются и схлопываются поддеревья (но не когда дерево скролируется), изменяется число видимых строк, даже если сами исходные данные не меняются. Поэтому обычное XUL дерево более динамично, чем список, поскольку в нем число видимых строк меняется, а в списке - нет. Чтобы выполнить эту задачу, мы можем использовать существующий конструктор контента дерева и лишь заменить снимок контента дерева нашим собственным. Это значит - создать объект с интерфейсом nsITreeView. Это довольно большой объект, так что выполним задачу по частям. Общий вид структуры объекта приведен в листинге 13.16. function customTreeView(tree) {
this.calculate();
this._tree = tree;
}
customTreeView.prototype = {
// 1. application specific properties and
methods calculate : function () { ... }, ...
// 2. Important nsITreeView features
getCellText : function (index) { ... }, ...
// 3. Unimportant nsITreeView features
getImageSrc : function (index) {... },
...
}
Листинг
13.16.
Прототип JavaScript-объекта снимок дереваПроизведем анализ этого объекта. Конструктор customTreeVew() создается специально для нашего приложения. Он обрабатывает некоторую внутреннюю информацию и обеспечивает связь с объектом <tree>. Это просто подготовительная работа. Прототип объекта содержит все стандартные свойства и методы. Мы вольны добавить все, что нам нужно, поскольку интерфейс nsITreeView у нас также реализован. Часть 1 прототипа - это добавочные свойства, о которых конструктор ничего не знает и которые не использует. Часть 2 - порция интерфейса nsITreeView. Этот интерфейс имеет множество методов для работы с контентом дерева: drag and drop, стили, специализированный контент наподобие счетчиков и так далее. Некоторые аспекты интерфейса критически важны, либо для конструктора, либо для наших целей - и эту часть интерфейса мы реализуем соответствующим образом. Часть 3 - оставшаяся часть nsITreeView. Для этой части мы напишем заглушки, не делающие ничего или почти ничего. Фактически, можно избавиться и от некоторых не слишком сильно используемых методов nsITreeView также. Если конструктор решит обратиться к этим отсутствующим методам, что может случиться, а может и нет, на консоли JavaScript появится сообщение об ошибке. Но лучше подстраховаться. Давайте теперь займемся этими тремя частями нашего объекта "снимок". Первая часть, специфичная для нашего приложения, также и самая сложная. Она сложна, потому что в этом примере мы собираемся реализовать в ней большинство требований конструктора. Она сложна также и потому, что наши начальные данные (массив treedata) совсем не похожи на иерархическое дерево данных. Это нужно поправить. Наша конечная цель - преобразовать исходные данные в другие структуры. Первая структура должна соответствовать тому, что может отобразить тег "дерево". Она должна представлять все возможные данные, или, по крайней мере, текущее раскрытое и готовое к отображению поддерево данных. В нашем примере есть только раскрытые поддеревья. Вторая структура - индексированный список отображаемых строк дерева. Несмотря на то, что первичная колонка дерева отображает иерархическую структуру, прямоугольная колонка ячеек данных все равно образует простой упорядоченный список. Именно значения индекса этого простого списка передаются от конструктора к снимку и обратно, именно это и делает снимок снимком. Точно так же, как и в случае динамического списка. Снимок, который мы реализуем, должен уметь обрабатывать эти индексы. Ниже описана наша тактика реализации этих структур данных. Создать структуру данных relatedMatrix, которая представляет все пары слово-слово. С ней будет удобнее работать, чем с простым списком, который мы имеем в начале. Создать структуру данных openTree так, чтобы мы могли видеть, на что похоже дерево в каждый момент. Нам нужно синхронизироваться с воздействием пользователя на дерево. Создать структуру viewMap. Это массив, связывающий индекс строк дерева со структурой openTree. Эти структуры приведены в Листинге 13.17, который соответствует части первой нашего прототипа снимка дерева. _relatedMatrix : null,
_openTree : null,
_viewMap : null,
calculate : function () {
this.calcRelatedMatrix();
this.calcTopOfTree();
this.calcViewMap();
},
calcRelatedMatrix : function () {
this._relatedMatrix = {};
var i = 0, r = this._relatedMatrix;
while (i < treedata.length ) {
if ( ! (treedata[i][0] in r) )
r[treedata[i][0]] = {};
if ( ! (treedata[i][1] in r) )
r[treedata[i][1]] = {};
r[treedata[i][0]][treedata[i][1]] = true;
r[treedata[i][1]][treedata[i][0]] = true;
i++;
}
},
calcTopOfTree : function () {
var i;
this._openTree = [];
for (i=0; i < listdata.length; i++) {
this._openTree[i] = { container : false,
open : false,
keyword : listdata[i],
kids : null,
level : 0 };
if (listdata[i] in this._relatedMatrix )
this._openTree[i].container = true;
}
},
calcViewMap : function () {
this._viewMap = [];
this.calcViewMapTreeWalker(this._openTree, 0);
},
calcViewMapTreeWalker : function(kids, level) {
for (var i=0; i < kids.length; i++ ) {
this._viewMap.push(kids[i]);
if (kids[i].container == true && kids[i].open == true )
this.calcViewMapTreeWalker(kids[i].kids, level + 1);
}
},
Листинг
13.17.
Специфичная для NoteTaker часть объекта "снимок"Здесь много кода, но он ясный. Сначала три свойства, все они отмечены подчеркиванием, чтобы показать, что их не должны касаться пользователи объекта. Они должны содержать внутренние структуры данных снимка. Затем метод calculate(), который строит эти структуры данных, используя свой метод для каждой структуры. Остальное - три конкретные метода. Функция calcRelatedMatrix() дает лучше организованную копию исходных данных. Для данных из Листинга 13.13 она предоставляет структуру Листинга 13.18. _relatedMatrix = {
"checkpointed" : {
"breakdown" : true,
"first draft" : true,
"final" : true
},
"reviewed" : {
"guru" : true,
"rubbish" : true
},
"fun" : { "cool" : true },
"guru" : { "cool" : true,
"reviewed" : true
},
"breakdown" : { "checkpointed" : true },
"first draft" : { "checkpointed" : true },
"final" : {"checkpointed" : true },
"rubbish" : { "guru" : true },
"cool" : { "fun" : true,
"cool" : true }
};
Листинг
13.18.
Пример матрицы keyword-to-keywordКаждое ключевое слово в исходном списке пар описано как свойство объекта _relatedMatrix object, а каждое связанное ключевое слово является подобъектом этого ключевого слова. В такой организации и прямые, и обратные связи без труда прослеживаются, и для каждого легко найти связанные слова. Эта структура данных - официальное представление данных в снимке. Следующий шаг - создать иерархическую версию этих связанных ключевых слов. Каждый элемент дерева имеет ноль или более дочерних элементов, и все дочерние элементы упорядочены. Это значит, что каждый узел дерева (узел структуры данных, а не узел DOM) является списком дочерних. Для каждого узла мы используем массив. В корне структуры - calcTopOfTree(). Структура описана в Листинге 13.19: calcTopOfTree : function () {
var i; this._openTree = [];
for (i=0; i < listdata.length; i++) {
this._openTree[i] = {
container : false,
open : false,
keyword : listdata[i],
kids : null,
level : 0
};
if ( listdata[i] in this._relatedMatrix )
this._openTree[i].container = true;
}
},
Листинг
13.19.
Создание корневого узла в иерархическом дереве данных:Этот метод создает массив записей ключевых слов как узел верхнего уровня и помещает в него слова из списка, которые являются массивом listdata. Таким образом, ключевые слова списка занимают верхний уровень дерева на экране. Каждая запись ключевого слова является объектом, содержащим строку ключевого слова, ссылку на непосредственные дочерние объекты и некоторую служебную информацию. Служебная информация - это: является ли элемент контейнером (container="true" в записи XUL), открыт ли данный контейнер (open="true" в записи XUL), какова глубина расположения данного узла в дереве. Когда настанет соответствующее время, другие методы снимка будут добавлены к этому дереву. Наконец, нам нужно иметь проиндексированный список строк, видимых в дереве. В Листинге 13.20 показано, как это делается. calcViewMap : function () {
this._viewMap =[];
this.calcViewMapTreeWalker(this._openTree, 0);
},
calcViewMapTreeWalker : function(kids, level) {
for (var i=0; i < kids.length; i++ ) {
this._viewMap.push(kids[i]);
if (kids[i].container == true && kids[i].open == true )
this.calcViewMapTreeWalker(kids[i].kids, level + 1);
}
},
Листинг
13.20.
Создание корневой ноды в иерархии данных дереваМетод calcViewMap() - стартовая точка в конструировании этого списка. Он передает корень иерархии дерева рекурсивной функции calcViewMapTreeWalker(). Она проходит по раскрытой части дерева слева направо, что то же самое, что сверху вниз для тега <tree>. Для каждого найденного ключевого слова она добавляет ссылку на это слово в индексируемый список элементов. Таки образом каждая запись ключевого слова отслеживается и собственно деревом, и списком. Эти утилиты создают структуры данных, которые пока не использовались. Такие структуры существуют внутри объекта "снимок". Структура relatedMatrix статична, до тех пор, пока не будет пересоздана заново. Остальные две структуры изменяются с течением времени. Теперь обратимся к важным частям интерфейса nsITreeView. В Листинге 13.21 показано большинство этих методов. Встроенный конструктор дерева вызывает эти методы, когда ему нужно получить доступ к данным, предоставляемым снимком. Если нам понадобится позже какой-либо скрипт, он также сможет использовать данные методы. get rowCount() {
return this._viewMap.length;
},
getCellText: function(row, column) {
return this._viewMap[row].keyword;
},
isContainer: function(index) {
return this._viewMap[index].container;
},
isContainerOpen: function(index) {
return this._viewMap[index].open;
},
isContainerEmpty: function(index) {
var item = this._viewMap[index];
if ( ! item.container )
return false;
return ( item.kids.length == 0); // empty?
},
getLevel: function(index) {
return this._viewMap[index].level;
},
getParentIndex: function(index) {
var level = this._viewMap[index].level;
while ( --index >= 0 )
if (this._viewMap[index].level < level )
return index;
return -1;
},
hasNextSibling: function(index, after) {
var level = this._viewMap[index].level;
while ( ++index < this._viewMap.length ) {
if ( this._viewMap[index].level < level )
return false;
if (this._viewMap[index].level == level && index > after )
return true;
}
return false;
},
Листинг
13.21.
Наиболее важные методы интерфейса nsITreeView.Эти методы и свойство rowCount демонстрируют, насколько важен viewMap - теперь мы можем непосредственно получать нужные нам результаты. Поскольку записи ключевых слов содержат заранее вычисленное значение уровня, даже самые сложные из методов, наподобие hasNextSibling(), имеют очень простую реализацию. Все, что нам требуется, это смотреть выше или ниже в viewMap, до тех пор, пока нужная запись не обнаружится. В случае getParentIndex() это означает заглянуть в список на один уровень выше. В случае hasNextSibling() - на уровень ниже, но не обращаться к иным уровням. Последний важный метод - toggleOpenState(). Он вызывается, когда пользователь открывает или закрывает поддерево. Это действие сложное, потому что изменяется число строк в списке видимых строк дерева. Реализация toggleOpenState() должна обновлять структуру данных снимка, когда это случается, а также должна предписывать нижележащей системе отображения виджета обновить, или перерисовать дерево. Если хоть что- то из этого не реализовать, программный снимок перестанет соответствовать видимому изображению. В Листинге 13.22 приведен код данного метода. toggleOpenState: function(index) {
var i = 0;
var node = this._viewMap[index];
if ( !node.container )
return;
if ( node.open ) {
node.open = false;
node.kids = null;
i = index + 1;
while ( this._viewMap[index].level > this._viewMap[i].level)
i++;
i = i - index;
}
else {
node.open = true;
node.kids = [];
for (var key in this._relatedMatrix[node.keyword]) {
node.kids[i] = {
container : false,
open : false,
keyword : key,
kids : null,
level : node.level + 1
};
if (typeof(this._relatedMatrix[key]) != "undefined" )
node.kids[i].container = true; i++;
}
}
this.calcViewMap();
this._tree.treeBoxObject.rowCountChanged(index,i);
},
Листинг
13.22.
Важный метод toggleOpenState() интерфейса nsITreeViewФункция завершает работу, если рассматриваемый элемент не является контейнером; в противном случае она умеет открыть закрытое поддерево и закрыть открытое. В одних случаях она выполняет следующие задачи: обновляет запись ключевого слова так, чтобы та соответствовала новому состоянию, обновляет иерархию openTree, убирая лишние или добавляя дочерние записи, вычисляет число удаляемых или добавляемых строк с помощью viewMap. После каждой операции viewMap пересчитывается целиком, чтобы сохранить соответствие программного снимка видимому снимку экрана. Последний шаг - команда дереву обновить изображение на экране. Чтобы этого добиться, нужно отдать команду специальному объекту дерева - box. Обычно мы используем этот объект лишь для скролирования, но его метод rowCountChanged() (принадлежащий интерфейсу nsITreeBoxObject) - в точности то, что нам нужно. Он требует массив строк (index) и число строк из этого массива как параметры, описывающие ту часть дерева, которую необходимо перерисовать. В простых деревьях, когда мы сами пишем код снимка, как в данном случае, единственный способ динамически изменять список видимых в настоящее время строк - открывать и закрывать поддеревья. Если же добавить дереву обработчики событий, они также смогут создавать динамические изменения. Например, клик мышкой по строке, который удаляет эту строку. Чтобы это реализовать, конструктор дерева должен манипулировать структурами данных снимка и вызывать методы calcViewMap() и rowCountChange() так же, как это делает метод toggleOpenView(). Самый очевидный способ это осуществить - добавить соответствующие методы снимку, выполняющие эту работу, и затем вызывать их из обработчика события. Описав специфичные для нашего приложения методы программного снимка и важные методы nsITreeView, обратимся к менее важным. Для другого приложения они могут быть критически важны, но не в нашем случае. В Листинге 13.23 приведена их реализация. canDropBeforeAfter: function(index, before) { return false; },
canDropOn: function(index) { return false; },
cycleCell: function(row, column) {},
cycleHeader: function(col, elem) {},
drop: function(row, orientation) { return false; },
getCellProperties: function(row, prop) {},
getCellValue: function(row, column) {},
getColumnProperties: function(column, elem, prop) {},
getImageSrc: function(row, column) {},
getProgressMode: function(row, column) {},
getRowProperties: function(row, column, prop) {},
isEditable: function(row, column) { return false; },
isSeparator: function(index) { return false; },
isSorted: function() { return false; },
performAction: function(action) {},
performActionOnCell: function(action, row, column) {},
performActionOnRow: function(action, row) {},
selectionChanged: function() {},
setCellText: function(row, column, value) {},
setTree: function(tree) {}
}; // end of customTreeView.prototype
Листинг
13.23.
Менее важные методы nsITreeViewЭти методы либо говорят "Нет", либо не делают ничего. Наш снимок не поддерживает drag-and-drop в дереве. Нет свойств ячеек, строк, колонок, нет значений ячеек, нет изображений, счетчиков состояния, редактируемых полей, либо каких-то действий с полями. У нас нет сортируемых колонок или тегов <treeseparator>, и мы не обращаем внимания на то, что пользователь может высветить строку. Метод setTree() запускается во время инициализации дерева, и больше нас не интересует, хотя мы и могли бы вызвать calculate() в этом методе, если бы захотели. Мы просто вызываем calculate(), когда создается снимок. После такого количества кода наш эксперимент по программированию самостоятельного снимка дерева завершен. Мы получили несколько результатов, достойных упоминания. Первый результат очевиден: с помощью снимка и JavaScript мы можем базировать дерево на отличном от XML контенте. Это может быть предпочтительно для манипулирования DOM, особенно в случае не- иерархических данных. Второй результат не столь очевиден. Программный снимок, сконструированный нами, имеет бесконечный размер. Если слово A связано с B, то и B тоже, очевидно, связано с A, так что открытие поддерева на первом слове ведет к открытию поддерева на втором и наоборот. Ясно, что подобные бесконечные деревья не могут быть созданы средствами статического XUL. В следующей главе мы увидим, что построенные лишь частично (а, значит, возможно, и бесконечные) деревья - обычное свойство системы шаблонов. Последний результат: мы увидели кое-что из внутренней механики тега <tree>. Платформа предоставляет для этого тега некоторые интерфейсы и структуры (такие как конструктор дерева) и на эту механику очень рекомендуется взглянуть. На этом мы заканчиваем конструирование модели данных и графического интерфейса утилиты NoteTaker. В разделах "Практика" мы займемся шаблонами и RDF. Это будут последние вносимые нами изменения в способ хранения данных в рассматриваемой утилите. 13.6. Отладка: как заставить <listbox> и <tree> работатьТеги <listbox> и <tree> сложнее элементов форм и могут очень разочаровать, если с самого начала не взяться за дело правильно. Тег <listbox> имеет много нюансов, а это требует осторожности в обращении. Несмотря на внешнюю сложность, тег <tree> - не столь хрупкое существо. Он работает стабильно, и если в дереве не появляется данных, ищите ошибку у себя в коде. По мере того, как Mozilla "взрослеет", эти теги, без сомнения, будут все более и более надежны и дружественны к пользователю. Главная проблема с ними в том, что они "растут" из XUL. Нет ни подробной диагностики времени выполнения, ни синтаксиса, ни сведений о возможных ошибках верстки. Хотя некоторую диагностику средства отладки платформы предоставить могут. Другими словами, успех в работе с этими виджетами принесут хорошие программистские привычки, в частности, структурное тестирование. Рекомендуется всегда начинать со статического и максимально простого виджета и двигаться в сторону желаемого результата последовательно, небольшими шагами. Тестируйте каждый шаг, чтобы удостовериться, что в результате происходит именно то, чего вы ожидаете. Если возникают неожиданные результаты, "откатитесь" назад, и начните снова из безопасной позиции. Ни при каких обстоятельствах не вставляйте в текст программы новый код экранами, даже если это работающий код. Множество проблем с этими виджетами - следствие простого недосмотра. Приведем примеры. Отсутствие атрибутов flex="1". Теги, окружающие <tree> и <listbox>, сами эти теги, спецификации колонок сильно выиграют от использования данного атрибута. Использование сокращенного синтаксиса для <tree>. Тег <tree> и его контент не имеют сокращенного синтаксиса. Все теги обязательны и должны быть полностью выписаны. Тег <listbox> может допускать некоторые сокращения. Отсутствие идентификаторов ids. Если теги <treecol> не имеют атрибутов ids, вы ничего не сможете выбрать в дереве. Не указана высота height в дереве. Значения по умолчанию у этого атрибута нет. Либо он должен диктоваться тегу из окружения, либо должен быть задан явно. Недостаточная подготовка. Да, документация по AOM, XBL, DOM, и XPIDL очень разнородна, да плюс еще этот курс! Разобраться удастся не сразу. Попытайтесь исследовать теги <tree> и <listbox> с помощью DOM Inspector, а потом перечитайте данную лекцию. Путаница с "индексами элементов". В интерфейсе снимка дерева индексы элементов представляют серию расположенных вертикально прямоугольников, каждый из которых содержит одну строку. Этот набор прямоугольников ограничен видимой областью дерева. "Индексы элементов" не представляют теги строк, образующие дерево, или строки, которые вообще могут быть показаны в данный момент. Они представляют лишь строки раскрытых поддеревьев, видимые в области показа в данный момент. То же верно и для списков, но там ситуация проще, потому что связь между видимыми прямоугольниками строк и строками списка однозначна, раскрываемых поддеревьев нет. В целом, теги <tree> и <listbox> не могут быть использованы столь же легко, как, например, тег <button>. До тех пор, пока тег <listbox> не оттестирован достаточно, постарайтесь не дать ему возможность влиять на дочерние, родительские и просто соседние теги. Пусть он будет ограничен собственной прямоугольной областью и только. В противном случае может возникнуть непредсказуемое поведение какого-либо элемента, а выяснить причину может оказаться нелегко. 13.7. Итоги<listbox> и <tree> - мощные виджеты в "зверинце" XUL. Это теги на стероидах. <listbox> слегка неустойчив в работе, а <tree> - несколько сложен, но оба они представляют собой очень гибкие системы для серьезных, ориентированных на обработку данных, приложений. До сих пор, однако, мы работали со статическими данными. Альтернатива в виде управления динамическим контентом с помощью сценариев, использующих DOM, весьма трудоемка и часто неуклюжа. Требуется что-то новенькое. Это шаблоны, которые мы рассмотрим в следующей главе. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||