| Разработка приложений с помощью Mozilla / автор: Н.Макфарлейн | ||||||||||||||||||||||||||||||
|
14. Глава:
Шаблоны
| ||||||||||||||||||||||||||||||
|
В этой главе рассказывается о том, как определить контент XUL документа, используя поток RDF данных. Это достигается комбинацией исходных XUL тегов, XUL тегов шаблона и RDF тегов. Система шаблонов Mozilla - это подмножество XUL тегов. Эти теги используются, чтобы создать документ, содержание которого не определено. Исходный документ служит основой для представления меняющихся со временем данных, либо в результате воздействия пользователя, либо в результате изменения самих исходных данных. Это также основа для создания приложений, чей графический интерфейс зависит от внешней информации. Внешняя информация может быть проста, как файл, или сложна, как база данных, и находиться где угодно в сети. В любом случае, вид такого документа меняется в зависимости от ситуации. Система шаблонов позволяет создавать многие виды приложений. Когда информация в шаблоне меняется согласно показаниям датчиков, документ ведет себя как телеметрическое приложение, например центр управления сетью или система контроля состояния окружающей среды. Когда информация изменяется конечным пользователем, документ превращается в приложение для работы с данными. В частности, система шаблонов соответствует приложениям для исследования данных, таких как категориальный анализ и анализ бизнес-процессов, системам контент- и документ-менеджмента, визуализации сетевых схем. Ее можно использовать и для обычных систем ввода данных. При традиционной web-разработке динамически изменяемый документ HTML может быть сконструирован двумя способами. HTML может генерироваться на стороне web-сервера (чем-то вроде CGI-программы), или HTML на стороне клиента может иметь многочисленные скрипты (динамический HTML). В любом случае, мы должны работать с кодом третьего поколения (3GL code), чтобы достигнуть желаемого результата. Система шаблонов Mozilla не требует 3GL кода и web-сервера. Ей, конечно, необходима Mozilla. Все что нужно сверх этого, - RDF документы и последовательность правил, что делать с этими RDF. Правила выражаются в виде XUL тегов. Платформа Mozilla автоматически наполняет XUL-документ RDF-сообщениями, когда документ загружается. Таким образом, система XUL-шаблонов управляется данными. Некоторые шаблоны требуют полного доступа к системе. Чтобы это было безопасно, приложение должно быть расположено в области chrome, в противном случае о безопасности придется позаботиться специально. Контент RDF, обрабатываемый шаблоном, может иметь два типа источников. Он может храниться в обычном RDF-документе в виде файла или системы файлов. В этом случае он может быть RDF-сообщениями (т.н. фактами) на любую тему. Пример: приложение NoteTaker, которое мы описываем в этой книге, работает с RDF именно таким образом. Другой способ порождения контента - "на лету", самой платформой Mozilla. В таком случае это RDF-сообщения на темы, связанные с самой платформой. Примером может служить управление окнами платформы. DOM Inspector обрабатывает внутреннюю RDF информацию, чтобы построить дерево, которое мы видим в меню File | Inspect a Window. Это дерево описывает текущие открытые окна. Понимание системы шаблонов означает понимание системы правил шаблонов. Последовательность правил может быть простой или сложной. В самом простом случае правила лишь подразумеваются и не выражены явно. В сложных случаях правила подобны или запросу к базе данных или оператору switch в языке JavaScript. В обоих случаях приходится использовать специальные переменные шаблонов. Как и во многих других случаях XUL, система шаблонов начинается с простого и ясного синтаксиса: <template> <rule> ... </rule> <rule> ... </rule> </template> Шаблоны так же сложны, как и деревья, и простой базовый синтаксис скоро усложнится, поскольку есть множество подробностей. Шаблоны не имеют собственного содержания: нет никаких блокоподобных тегов шаблонов. Теги шаблонов больше похожи на макро-инструкции и оператор #ifdef препроцессора языка C. Эти теги всегда используются внутри других XUL тегов; они не могут быть тегами верхнего уровня, наподобие тега <window>. На схеме в начале этой главы показана область, затрагиваемая системой шаблонов в платформе. Из нее видно, что шаблоны - маленькая, компактная система, отделенная от остальной платформы Mozilla. Их работа - последний этап в процессе формирования документа при его загрузке. Шаблоны никак не затрагивают систему отображения XUL контента. Поскольку шаблоны работают в паре с RDF, и RDF файлы, и URL/URI имена интенсивно ими используются. Как и для большинства характерных черт платформы, за работу функциональности шаблонов в основном ответственны несколько XPCOM объектов. 14.1. Пример шаблона: hello, worldЛистинг 14.1 XUL-документ, содержащий простейший шаблон, выводящий "hello, world" один или несколько раз. <?xml version="1.0"?> <window xmlns="http://www.mozilla.org/keymaster/ gatekeeper/there.is.only.xul"> <vbox datasources="test.rdf" ref="urn:test:seqroot"> <template> <label uri="rdf:*" value="Content: rdf:http://www.example.org/Test#Data"/> </template> </vbox> </window>Листинг 14.1. XUL-приложение "hello, world", использующее технологию шаблонов. Как видно из листинга, система шаблонов состоит из собственных тегов, подобных тегу <template>, и специальных атрибутов для других тегов, таких, как атрибут ref. Mozilla предоставляет несколько типов синтаксиса правил, образующих систему запросов в шаблонах. В данном примере использовался простейший синтаксис: только одно правило, причем подразумеваемое. Оно гласит: обработать все сообщения конкретного контейнера RDF и сгенерировать XUL-контент, представляющий эти сообщения. Контейнер имеет URI urn:test:seqroot, а контент, представляющий сообщения, определяется тегом <label>. Обратите внимание, что и внутри, и снаружи тега шаблона <template> могут быть теги обычного типа, не относящиеся к системе шаблонов. В листинге 14.2 приведен RDF файл, соответствующий структуре DRF графа, которую ожидает данный шаблон. <?xml version="1.0"?>
<RDF xmlns:Test="http://www.example.org/Test#"
xmlns="http://www.w3.org/1999/02/22-rdf-syntax-ns#" >
<Description about="http://www.example.org/">
<Test:Container>
<Seq about="urn:test:seqroot">
<li resource="urn:test:welcome"/>
<li resource="urn:test:message"/>
</Seq>
</Test:Container>
<Description about="urn:test:welcome" Test:Data="hello, world"/>
<Description about="urn:test:message" Test:Data="This is a test"/>
</RDF>
Листинг
14.2.
Простейший пример RDF файла, использующего шаблон.Данный файл RDF не имеет иных параметров, кроме тега <Seq>, имя ресурса которого использовалось в коде XUL-шаблона в листинге 14.1. Это унифицированное имя ресурса (URN) используется как стартовая точка шаблона. Test - пространство имен xmlns. Data и Container - специальные свойства (предикаты) имен в этом пространстве имен. Имена URN и URL вида "http://www.example.org/Test" одинаково искусственны. Никакого формального процесса для выбора имен нет; нужно просто придумать подходящие. Свойство Data также присутствует в теге <label> листинга 14.1, где оно указано со своим полным URL. Если сохранить эти два листинга в файлы и загрузить первый, то мы увидим картинку, приведенную на рисунке 14.1. Диагностические стили включены, чтобы выявить структуру окна, полученного в результате. На рисунке видно, что в финальном XUL были сгенерированы два тега <label>. Значения каждого тега определяются и фиксированным значением ("Content: "), и строкой, определяемой одним из двух фактов <Description> в документе RDF. Тег vbox, напротив, появляется лишь один раз. Структуру финального документа можно исследовать с помощью приложения DOM Inspector. На рисунке 14.2 приведен вид DOM Inspector, соответствующий рисунку 14.1. 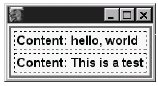 Рис. 14.1. XUL-документ, созданный по шаблону и двум фактам. 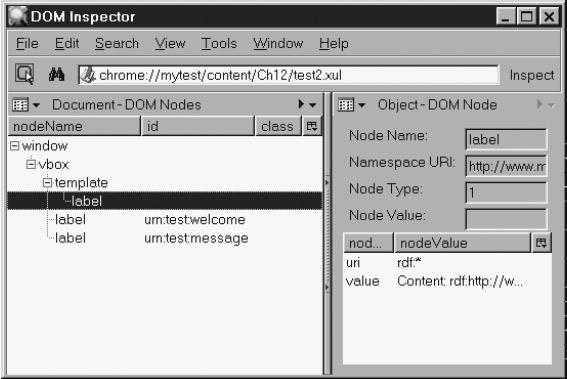 Рис. 14.2. Тот же документ в DOM Inspector. На снимке видно, что система шаблонов добавила два тега в финальный документ, по одному на каждый факт в файле RDF. Подсвеченный тег <label> - метка из исходного файла шаблона, другие два тега <label> - контент, сгенерированный шаблоном. Таким образом, финальный документ содержит два поддерева - одно для спецификации шаблона, а другое для сгенерированного контента. Поддерево, начинающееся тегом <template>, никак не отражается на внешнем виде документа. Когда система шаблонов генерирует теги для другого поддерева, она присваивает им ids, равные URN ресурса в соответствующем факте RDF. XUL этого шаблона можно сделать гораздо сложнее, используя свойства системы правил шаблонов. Перед тем, как углубиться в синтаксис XUL системы шаблонов, нам следует отступить далеко назад, чтобы увидеть, что все это означает с точки зрения фактов. В конце концов, шаблону для работы нужен RDF контент, а это подразумевает обработку фактов. 14.2. Понятие шаблонаСистема шаблонов Mozilla затрагивает все стандартные отличительные черты приложений Mozilla: XUL, JavaScript и RDF. Она касается и работы с источниками данных. Эти ее свойства будут рассмотрены по очереди и затем сведены воедино на примере. 14.2.1. Запросы RDF и унификацияСистема шаблонов XUL - это система запросов. Она осуществляет поиск в массиве данных и возвращает элементы массива, соответствующие спецификации запроса. Данные, по которым осуществляется поиск, - это множество фактов RDF. Запрос шаблона - часть процесса обработки, также имеющая дело с RDF. Запросы, выполняемые XUL-шаблоном, часто описываются как система сравнивания с образцом. В самом общем смысле слова "образец", принятого в computer science, это верно, но сравнение с образцом имеет также и простой каждодневный смысл. Он употребляется, например, когда мы говорим о масках имени файла, как *.txt или о регулярных выражениях, таких как "^[a-zAZ]*66$". Такие инструменты, как командная строка, Perl, grep, vi, и даже JavaScript используют обычное сравнение с образцом, которое попросту очень напоминает фильтрацию. При простой фильтрации большой список элементов (или символов) сокращается. Шаблоны XUL не являются фильтрами и не выполняют сравнение с образцом в этом каждодневном смысле слова. Если документ RDF содержит некое сообщение, XUL шаблон, обрабатывающий этот документ, должен не только принять или проигнорировать это сообщение. Запросы в шаблонах - это не просто фильтры. В отличие от простой фильтрации, запросы в шаблонах выполняют унификацию. Унификация имеет место тогда, когда множество элементов данных комбинируется в конечный результат. Пример из реальной жизни - собирание паззла. Когда все кусочки паззла собраны вместе, решение найдено (получена картинка). Если дано больше элементов, чем нам понадобилось (предположим, было перемешано несколько наборов паззлов), часть элементов будут отброшены, как незначащие. Унификация может дать больше, чем один результат. Если элементов головоломки достаточно, можно собрать несколько картинок. Если элементы имеют подходящую форму, то несколько результатов может быть получено даже из одного набора. В Mozilla элементы головоломки это подлежащие, сказуемые и дополнения набора RDF сообщений (фактов). Желаемый результат определен в запросе XUL шаблона. Любая комбинация элементов, удовлетворяющая спецификации запроса (правилам в шаблоне), будет найдена как новый порядок информации - новый кортеж. Если более одной комбинации элементов удовлетворяют запросу, будет образовано более одного нового кортежа. Это кажется знакомым. Инструкция SELECT в SQL ведет себя точно так же, когда выполняет запрос join - то есть выбирает данные из двух или более таблиц. Данные в полученных колонках не соответствуют данным ни в одной из исходных строк, они соответствуют информации в строках разных таблиц. Этим способом может быть обнаружено более одной строки. Фактически, запросы XUL-шаблонов являются примерами реляционных вычислений, так же как запросы SQL - примеры реляционной алгебры. Исследователи в университетах показали, что оба реляционных подхода - по сути одно и то же, хотя программируются по-разному и имеют мало общего в синтаксисе. Синтаксис шаблонов XUL необычен и лучше начинать не с него. Чтобы разобраться в структуре запросов шаблонов, давайте вернемся к примеру с мальчиком, собакой и мячиком из главе 11, "RDF". Вспомним, что этот пример использовался для описания "чистой" системы сообщений, без RDF или XML синтаксиса. Мы снова используем его здесь, чтобы привести пример "чистого" запроса и унификации сообщений. Пример сообщений из главе 11, "RDF", повторяется в листинге 14.3. <- 1, is-named, Tom -> <- 1, owner, 2 -> <- 1, plays-with, 5 -> <- 2, is-named, Spot -> <- 2, owned-by, 1 -> <- 2, plays-with, 5 -> <- 5, type-of, tennis -> <- 5, color-of, green ->Листинг 14.3. Предикатные триплеты из примера о мальчике и собаке, глава 11. Эта информация моделирует сообщение "Том и его собака Спот играют с зеленым теннисным мячиком". Каждый элемент модели имеет идентификационный номер. Мы можем запрашивать это множество сообщений с помощью простых, или единичных (single-fact), либо множественных (multi-fact) запросов. 14.2.1.1. Простые (single-fact) запросыВ главе 11, "RDF", мы видели, что бывают основные (от ground - основа) факты (и RDF документы). Основные факты - это хорошо, потому что каждая часть основного факта есть попросту литерал, без неизвестных. С литералами легко работать. Примеры неосновных фактов в главе 11, "RDF", приводились также. Вот немного измененный, неосновной факт: <- 1, owner, ??? -> Поскольку дополнение (объект) в этом триплете неизвестно, это не основной факт. Его нельзя использовать как данные, но можно - как стартовую точку для запроса о других фактах. Используем переменную для неизвестной части. Переменная начинается с символа вопросительного знака, точно как переменные в DOS начинаются и заканчиваются знаком '%', а переменные в оболочке UNIX начинаются со знака '$'. Переменная не может быть в основном состоянии, иначе она не переменная, а литерал. Будем называть процесс перевода переменной с неизвестным значением в переменную с известным - обоснованием переменной. <- 1, owner, ?dogId -> При выполнении запроса унификация означает, что все переменные из множества доступных фактов будут преобразованы в литералы. Причудливым образом можно сказать так: "Обоснуй-ка мне все переменные, пожалуйста". Для нашего простого примера данному перегруженному переменными запросу отвечает второй факт из листинга 14.3. <- 1, owner, 2 -> Переменная ?dogId не имеет значения, и если значение 2 заменит ее, будет получен факт, соответствующий существующему факту. Таким образом, переменная ?dogId может быть обоснована значением 2. Это тривиальный пример запроса, возвращающего один результирующий факт. Предположим, у Тома есть вторая собака, по кличке Фидо. Значит, есть дополнительный факт: <- 1, owner, 3 -> <- 3, is-named, Fido -> Если факт, содержащий переменную ?dogId, снова использовать как запрос, ему будут соответствовать уже два факта: <- 1, owner, 2 -> <- 1, owner, 3 -> ?dogId может быть обоснована либо значением 2, либо 3, так что теперь есть два решения. Мы можем говорить, что результирующее множество содержит два факта, две строки, или два элемента. Предшествующий факт, используемый как запрос, также может быть расширен. Его можно указать так: <- ?personId, owner, ?dogId -> В этом случае соответствие требует комбинации значений, удовлетворяющих обеим переменным одновременно (обосновывается и ?personId, и ?dogId). Если мы используем существующие факты, результирующее множество также будет иметь две строки: (?personId обосновывается 1 и ?dogId обосновывается 2) даст один факт, а (?personId обосновывается 1 и ?dogId обосновывается 3) даст второй. Увеличение количества переменных не всегда означает увеличение количества результирующих фактов. Это лишь означает, что нужно найти соответствие большему количеству предметов. Предположим, что Джейн (чей person id = 4) также владеет Фидо, но не Спотом. Фидо, таким образом, принадлежит двум хозяевам, но Спотом владеет только Том. В списке фактов добавятся два новых: <- 4, is-named, Jane -> <- 4, owner, 3 -> Если последний запрос выполнить вновь, мы получим три результата: ?personId обосновывается 1 (Tom) and ?dogId обосновывается 2 (Spot) ?personId обосновывается 1 (Tom) and ?dogId обосновывается 3 (Fido) ?personId обосновывается 4 (Jane) and ?dogId обосновывается 3 (Fido) Хотя ?personI может иметь значение 4 (Джейн), а ?dogId - 2 (Спот), результата это не даст, потому что такого факта (Джейн владеет Спотом) в списке фактов нет. Когда факт соответствует факту запроса, он ему соответствует целиком, а не частично. Наконец, заметим, что информация, которую нужно обосновать в последнем простом запросе, имеет иную нотацию. Она может быть записана как набор неизвестных, которые нужно найти. Этот набор можно записать как кортеж. В этом примере кортеж - двойка, а не триплет. Этот кортеж может быть записан так: <- ?personId, ?dogId -> Этот кортеж еще не запрос. Он просто описывает, какие есть неизвестные и какие переменные будут найдены, когда запрос вернет результат. Это полезная информация для программиста, что-то подобное части INTO в SQL запросе SELECT. Если кто-то другой писал запрос, такая информация - все, что вам нужно, чтобы понять полученный результат. В последнем примере три строки соответствуют этому кортежу: <- 1, 2 -> <- 1, 3 -> <- 4, 3 -> Кортеж из двух переменных аккуратно собирает всю неизвестную информацию вместе. Процессору запроса все еще нужна информация из хранилища фактов, соответствующая этой структуре. Вот почему запросы имеют полный синтаксис, использованный нами ранее. Если процессору запросов не дать достаточно информации, он не будет знать, что ему делать. Недостаточно сказать, "компьютер, умница, найди-ка мне эти переменные". Запрос должен указать процессору, на что смотреть. В случае простого запроса предписание может быть очень простое: "комп, тупица, просмотри-ка все триплеты данных и найди все, соответствующие этому триплету-запросу". Система шаблонов Mozilla поддерживает простые (single-fact) запросы. Простые запросы должны быть сформулированы с использованием расширенного синтаксиса запросов. Простые запросы не могут быть сформулированы с помощью простого синтаксиса. Слегка заглядывая вперед, скажем, что в запросе о единичном факте тег <conditions> должен быть записан одним из двух способов. Если искомый факт содержится в RDF-контейнере с предикатами rdf:_1, rdf:_2 и так далее, то в теге <conditions> должны содержаться <content> и <member>. Если же искомый факт содержит хорошо известные предикаты, <conditions> должен содержать теги <content> и <triple>. Простые запросы шаблонов обсуждаются далее в разделе "Распространенные образцы запросов". Резюме: простой запрос пытается обосновать запрашиваемый факт множеством реальных фактов. И если это получается, найденные основные, т.е. литеральные результаты называются решением запроса. 14.2.1.2. Комплексные (Multifact) запросыСистема XUL шаблонов поддерживает комплексные (multifact) запросы. Комплексные запросы напоминают SQL запрос join и также напоминают навигацию по древообразной структуре данных. Комплексные запросы - это вопросы, требующие для ответа, чтобы два или более реальных факта были скомбинированы. Другими словами, требуется некая дедукция. Поддержка дедукции в Mozilla напоминает упрощенные вычисления предикатов в Прологе, за исключением того, что это подобие хорошо замаскировано синтаксисом. Сначала мы рассмотрим "чистые" комплексные запросы, а потом обратимся к XUL синтаксису. Используя пример о мальчике и собаке, предположим, что нужно задать запрос: "Как зовут собаку, которой владеет Том"? <- ?personId, is-named, Tom -> <- ?personId, owner, ?dogId -> <- ?dogId, is-named, ?dogName -> Формулирование комплексных запросов требует некоторой практики. Это тот же вид практики, который требуется, чтобы освоить SQL запросы join для нескольких таблиц или регулярные выражения с несколькими переменными. Ключевая проблема состоит в том, что запрос приходится писать сразу, усилием воли, с чистого листа. Данный запрос был построен следующим образом. Сначала было установлено уже нам известное ("Том"). Затем мы определили то, что нам не известно, но мы хотим узнать: dogName. Мы просмотрели доступные нам кортежи, чтобы узнать, каким из них могут соответствовать известные и неизвестные нам элементы. Это дало нам два кортежа, первый и третий в результирующем запросе. Глядя на эти кортежи, мы увидели, что некоторые предикаты обязательны: is-named используется в обоих кортежах. Чтобы полностью обосновать этот кортеж, нужно найти неизвестные (в данных кортежах это подлежащие), а именно personId и dogId. Мы добавили их в список неизвестных. Мы заметили, что эти два кортежа не имеют общих неизвестных, т.е. что они "не связаны". Мы снова просматриваем список известных кортежей, в поисках тех, которые могут их связать. Теперь мы обнаруживаем второй кортеж, связывающий personId и dogId. Итак, мы получаем список кортежей, где все неизвестные присутствуют, и все они соединены, так что этот список образует единый запрос. Если эти три факта, как единый запрос, направить в процессор запросов, то, чтобы решение нашлось, все неизвестные должны быть обоснованы одновременно. Поскольку каждая из переменных ?personId и ?dogId присутствует в двух кортежах, любое значение, которое они могут принимать, должно удовлетворять обоим кортежам одновременно. Единственным возможным решением на массиве нам известных фактов может быть лишь следующее: <- 1, is-named, Tom -> <- 1, owner, 2 -> <- 2, is-named, Spot -> Сравните эти три факта с запросом. Решение ставит в соответствие неизвестным переменным <- ?personId, ?dogId, ?dogName -> единственную возможность: <- 1, 2, Spot -> Спот - искомое значение, остальные переменные использовались, только чтобы связать факты вместе. Теперь на вопрос получен ответ - имя собаки, которой владеет Том, Спот. Остальные переменные можно или исследовать далее, или проигнорировать. Этот комплексный запрос поясняет, почему говорят, что переменные должны быть "унифицированы" а не просто "найдены": чтобы найти решение, всем кортежам должны быть найдены соответствия одновременно. Как процессор запросов в Mozilla ищет решение? Существует много возможных техник. Простейшая - перебирать все комбинации из трех реальных фактов и сравнивать каждую комбинацию с запросом. Это решение проблемы "грубой силой", оно очень неэффективно. Так в Mozilla не делается. Mozilla использует более тонкий метод, заключающийся в исследовании части графа структуры фактов. Скоро мы сможем в этом убедиться. Если снова поместить в список исходных фактов Фидо и Джейн, тот же самый запрос даст два решения: <- 1, is-named, Tom -> <- 1, owner, 2 -> <- 2, is-named, Spot -> <- 1, is-named, Tom -> <- 1, owner, 3 -> <- 3, is-named, Fido -> Здесь значения, обосновывающие неизвестные переменные, следующие: <- 1, 2, Spot -> <- 1, 3, Fido -> Обратите внимание, как конструируется запрос для сравнения с фактами списка. Подлежащие и дополнения соответствуют переменным, таким как ?personId. Результат, напротив, просто набор обоснованных переменных в кортежах, по одному кортежу на решение. В данном случае у нас три переменные, поэтому кортеж является триплетом. Этот пример эквивалентен SQL запросу join из трех таблиц. Листинг 14.4 показывает воображаемый SELECT запрос, выполняющий ту же работу, что и наш последний запрос. Каждая из трех воображаемых таблиц соответствуют одному факту из нашего списка. SELECT p.personId, d.dogId, d.dogName FROM persons p, owners o, dogs d WHERE p.personName = "Tom" AND p.personId = o.personId AND o.dogId = d.dogIdЛистинг 14.4. SQL SELECT запрос, аналогичный комплексному запросу. Точно как join в SQL-запросе связывает таблицы (реляционность), переменные в запросе о фактах связывают вместе факты. Сравните использование переменной personId в двух типах запросов, и вы увидите подобие, несмотря на абсолютно разный синтаксис. В общем случае этот пример демонстрирует, как большой массив фактов может быть исследован с помощью правильно сконструированных запросов, содержащих переменные. Если массив фактов - это RDF документ, то шаблоны в Mozilla могут выполнять простые, но универсальные запросы на этом массиве. Система шаблонов поддерживает комплексные шаблоны двумя способами. Простой синтаксис шаблона автоматически выполняет запрос по двум фактам, при условии, что RDF-данные организованы корректно. Расширенный синтаксис позволяет задавать комплексные запросы любой длины, соединяя вместе один тег <content>, любое количество тегов <member> и <triple>, и любое количество тегов <binding>. Каждый из этих тегов (за исключением тега <content>) представляет в запросе один факт. 14.2.1.3. Стратегия обработки запросаВ главе 11, "RDF", рассказывалось, что множество фактов может быть представлено одним из трех способов: как простое неструктурированное множество, как сложная, похожая на граф структура, либо как простое множество, имеющее подмножества, отмеченные RDF контейнерами, такими, как <Seq>. Mozilla использует комбинацию RDF графа (второй способ) и контейнеров (третий способ) для выполнения запросов. С точки зрения прикладного программиста, Mozilla использует "бурящий" (drill-down) алгоритм для обработки запросов. Этот алгоритм эквивалентен стратегии перебора дерева "сначала вниз". Он требует, чтобы запрос начинался с чего-то известного, это называется корень дерева. На практике начальная точка запроса в Mozilla должна быть либо подлежащим факта, либо дополнением. Она всегда имеет форму URI (URL или URN). Когда начальная точка выбрана, процессор запроса Mozilla двигается из нее по графу RDF фактов. Каждый факт эквивалентен переходу по одной стрелке (предикату или свойству) графа. Таким образом, в запросе на массиве трех фактов процессор выполнит лишь три шага из начальной точки вглубь графа. Систему запросов можно проиллюстрировать RDF графом. Вернемся к примеру с мальчиком и собакой. На этот раз пес Спот обнаруживает, что он может играть сам по себе. Оказывается, он владеет тряпочкой, причем абсолютно единолично. На Рисунке 14.3 показан граф, отображающий эти дополнительные факты, причем текущий запрос выделен жирными стрелками. На рисунке 14.3 все факты принадлежат списку фактов. Иллюстрируемый запрос состоит из двух фактов (two-fact query) и начинается с идентификатора Тома, то есть единицы (1). Запрос звучит примерно так: "С какими предметами могут играть собаки Тома"? Жирными стрелками выделены крайние в графе факты, факты-термины, которые запрос обнаруживает - запрос из двух фактов должен проходить ровно две стрелки. Светлые линии запросом не достигаются. Этот запрос сначала получает три решения. Каждое соответствует уникальному пути, начинающемуся с идентификатора (1): путь 1-2-Спот, путь 1-2-7 и путь 1-2-5. Уточняя запрос, мы можем потребовать, чтобы у первого факта сказуемым было "владеть" (собака принадлежит Тому) а у второго - "играть с". В этом случае путь 1-2-Спот больше не решение. И будут обнаружены в точности два оставшихся: "Собака Тома Спот играет с тряпочкой" и "Собака Тома Спот играет с теннисным мячом". 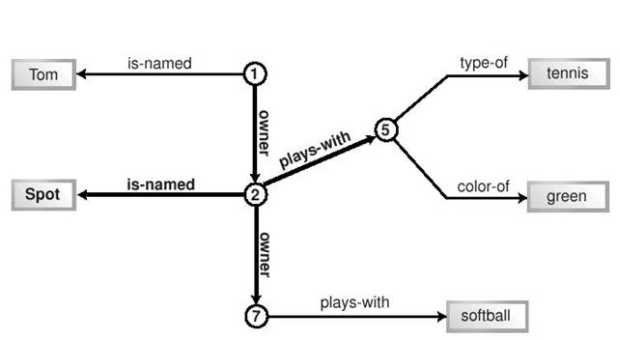 Рис. 14.3. Уточненный граф "мальчик и собака" и путь запроса. Мы можем поэкспериментировать немного с этим примером. 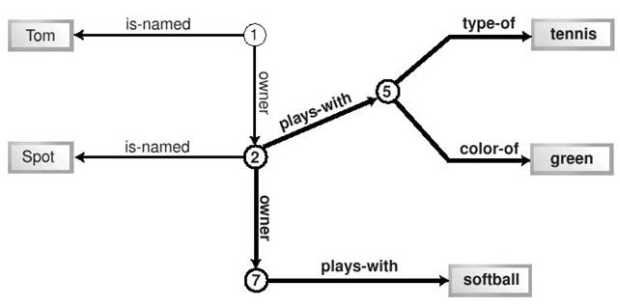 Рис. 14.4. На Рисунке 14.4 показан другой запрос на том же графе. Снова мы имеем запрос из двух фактов, но на этот раз он начинается с идентификатора Спота (2). Снова три решения. Заметим, что путь 2-1- Том не является решением. Потому что стрелка указывает в противоположную сторону. Вовсе не 2 - подлежащее факта, и 1 - дополнение, а наоборот. Запрос не может двигаться в обратном порядке. Но даже для возможных решений наш второй запрос все же вряд ли имеет смысл. Слишком разные обнаруживаются предикаты на этих путях. Если все же нужно найти в этом запросе смысл, лучше предположить, что либо реальные данные плохо описываются фактами, либо запрос был недостаточно хорошо продуман. Минус этой системы в том, что не все факты из исходного списка просматриваются. Теоретически, система может пропустить некоторые решения. Но ее достоинство - скорость. На практике, если RDF факты аккуратно упорядочены, быстрого поиска из известного начала достаточно, чтобы найти все решения. Этот "сверлящий" алгоритм - приближение. В реальности система шаблонов работает сложнее. Однако это достаточно хорошее приближение и рекомендуемая интерпретация способа работы системы шаблонов XUL. Способ организации RDF документа, подходящего системе шаблонов - использование тегов <Seq>, <Bag> или <Alt>. Известная стартовая точка - либо URI, либо факт, содержащийся в контейнере. Затем запрос "бурит" контейнер, добывая нужные факты. Это - стратегия индексирования. Листинги 14.5 и 14.6 показывают фрагмент RDF и соответствующий запрос. <Description about="http://www.example.org/"> <NS:Owns> <Bag about="urn:test:seq"> <li resource="urn:test:seq:fido"/> <li resource="urn:test:seq:spot"/> <li resource="urn:test:seq:cerebus"/> </Bag> </NS:Owns> </Description> <Description about="urn:test:seq:fido" NS:Tails="0"/> <Description about="urn:test:seq:spot" NS:Heads="1"/> <Description about="urn:test:seq:cerberus" NS:Heads="3"/>Листинг 14.5. Пример фрагмента RDF для комплексного запроса. NS в листинге 14.5 означает некоторое пространство имен, предположительно, объявленное в коде где-то ранее. Пространство имен должно иметь URI наподобие www.test.com/#Test. Листинг 14.6 использует пространство имен NS для идентификации экземпляров фактов, эквивалентных применяемым в листинге 14.5. Использование NS в листинге 14.6 не имеет никакого конкретного смысла, поскольку факты в этом листинге не являются ни XML, ни кодом вообще. <- http://www.example.org/, NS:Owns, ?bag -> <- ?bag, ?index, ?item -> <- ?item, NS:Heads, ?heads ->Листинг 14.6. Пример RDF запроса для бурения RDF контейнера. В запросе первый обосновываемый факт спускается (drills down) до факта RDF с подлежащим bag (bag - неупорядоченное мультимножество, допускающее повторение элементов), т.е. до строки <Bag about="urn:test:seq">). Второй обосновываемый факт спускается далее до элементов множества bag (множество из трех элементов <li resource= ...). Третий факт спускается до фактов о количестве голов у каждого элемента (в результате ноль или один ответ на каждую строку запроса, в зависимости от наличия головы у элемента множества (Фидо - ноль хвостов, Спот - одна голова, Цербер - три головы). В конечном результате обнаруживаются два решения. Множество обосновываемых переменных выглядит так: <- ?bag, ?index, ?item, ?heads -> а два найденных решения так: <- urn:test:seq, rdf:_2, urn:test:seq:spot, 1 -> <- urn:test:seq, rdf:_3, urn:test:seq:cerberus, 3 -> Вспомним, что RDF автоматически назначает имена предикатов, начинающиеся с rdf:_1,каждому потомку в контейнере. Первый потомок не обнаруживается запросом, поскольку третий из фактов запроса не приложим к факту с NS:Tails вместо NS:Heads. Поддержка такого типа запросов - первоочередной приоритет системы запросов Mozilla. Это самый надежный и плодотворный способ работы с системой шаблонов. В предыдущем примере переменная ?index использовалась для описания предиката факта. Система запросов Mozilla не может использовать переменную в запросе для предиката, но она имеет тег <member>, который достигает почти той же цели (с некоторыми ограничениями). Итак, набор фактов запроса обнаруживает подходящие записи в аккуратно упорядоченной коллекции и строит RDF граф, начиная с некоторой известной точки. 14.2.1.4. Сохраняемые запросыЗапросы XUL шаблона живут столько же, сколько и содержащий их документ. Они не запускаются однажды, а затем отбрасываются. Они используются, пока не закроется их отображающее окно. Список RDF фактов (возможно, загружаемый из файла) может затем модифицироваться, поскольку хранится в памяти. Факты могут добавляться в список, изменяться или удаляться из списка. Можно запрашивать систему шаблонов об этих изменениях. Когда данные изменяются, каждый запрос шаблона также меняет свое мнение о том, какие существуют решения этого запроса. Если новые решения возможны, они будут добавлены ко множеству решений. Если некоторые решения стали невозможны, они будут удалены. Возможны и изменения в ранее найденных решениях. Ближайшее следствие этого - то, что множество решений может со временем изменяться. Шаблонный запрос - не всегда "событие согласованного чтения" (если использовать жаргон RDBMS). Это живые, активно изменяющиеся "списки событий" (если говорить на телеметрическом жаргоне). Живой отклик запроса требует от прикладного программиста некоторой активности. Ведь запрос должен непрестанно сверяться со списком фактов, чтобы решения были актуальны. Чтобы это делалось эффективно, и только тогда, когда нужно, должны быть написаны определенные скрипты. XUL документы используют шаблонные запросы повсеместно. 14.2.1.5. Рекурсивные запросыБурящую стратегию шаблонных запросов Mozilla можно применять рекурсивно. Каждую конечную точку бурения можно использовать как следующую начальную точку для того же самого запроса. Это позволяет запросу продвигаться глубже по RDF-графу данных и, возможно, найти новые решения. Только когда новых решений не обнаруживается, мы достигаем конца рекурсии. Рекурсивное использование запросов очень плодотворно на древообразных структурах данных. Такие структуры могут иметь произвольную глубину, что соответствует произвольному числу связей в RDF графе. Без рекурсии это невозможно, потому что глубина просмотра запроса равна числу фактов запроса. В XUL документе шаблонные запросы внутри тега <tree> выполняют и добавочную работу. 14.2.1.6. Списки запросовСистема запросов Mozilla позволяет объединить несколько запросов в список. Когда начинается обработка запросов, все запросы списка обрабатываются одновременно. Любое решение, удовлетворяющее сразу нескольким запросам, будет поставлено в соответствие лишь одному. А именно - ближайшему к началу списка. Метод, которым это достигается, прост: на каждом шагу вниз по RDF- графу процессор запроса сверяется со списком запросов, уже частично обоснованных к данному моменту, и пытается обосновать их вновь обнаруженным фактом. Остальные запросы игнорируются. Когда процессор достигает дна графа, остаются лишь запросы, обоснованные найденными фактами. Такая система позволяет оценить ряд фактов одним набором критериев (одним запросом), а если решение найти не удалось, вновь оценить другим набором критериев (другим запросом). Это очень похоже на булевские условные выражения if ... else if. Списки запросов в Mozilla позволяют порождать несколько различных подмножеств одного множества фактов. Каждый запрос порождает одно такое множество решений. На этом мы закончим рассмотрение запросов шаблона. После выполнения запроса нужно обработать найденные решения. 14.2.2. Порождение XUL-контентаВ обычном случае все, что XUL шаблон делает с полученными данными - это выводит их на экран. Шаблон делает это, совмещая полученные данные с обычным XUL- контентом. Он действует так же, как программа для печати информации в наглядной форме, или заготовка для написания отчета, "рыба". Выводимые данные интегрируются в XUL-документ и выводятся на экран, как любой иной XUL-контент. Если шаблон содержится в теге XUL, таком как <menupopup>, <listbox>, <toolbar>, <tree> или даже <box>, то контент тега XUL (элементы меню, кнопки панели инструментов, строки списка или дерева) могут порождаться шаблоном. Это означает, что сами интерактивные интерфейсы могут описываться RDF файлом, а не кодироваться вручную. Проиллюстрируем процесс такого порождения простым примером. В листинге 14.7 - RDF файл, содержащий два факта в контейнере. Каждый факт имеет единственную пару свойство/значение. Такие пары обычно - самая интересная часть RDF документа, и они обычно выводятся на экран как XUL-контент. <?xml version="1.0"?>
<RDF xmlns:Test="http://www.test.com/Test#"
xmlns="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<Description about="urn:test:top">
<Test:TopSeq>
<Seq about="urn:test:seqroot">
<li resource="urn:test:message1"/>
<li resource="urn:test:message2"/>
</Seq>
</Test:TopSeq>
</Description>
<Description about="urn:test:message1" Test:Foo="foo"/>
<Description about="urn:test:message2" Test:Bar="bar"/>
</RDF>
Листинг
14.7.
Простой RDF документ, иллюстрирующий выводимый на экран XUL-контент.Два свойства могут быть извлечены из этого файла и выведены на экран с помощью шаблона. Рисунок 14.5 показывает два набора сгенерированного XUL-контента из данного RDF файла. Это требует двух шаблонов в одном XUL-документе. 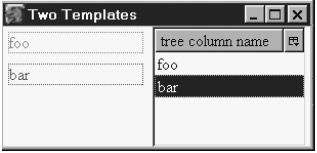 Рис. 14.5. Вывод двух шаблонов, использующих одни RDF данные. На снимке оба шаблона располагаются бок о бок. Мы видим конечный результат процесса порождения XUL контента. Шаблон слева генерирует теги <description> с рамками, заданными стилем. Теги находятся в теге <vbox>. Шаблон справа генерирует теги <treeitem>, каждый из них содержит <treerow> и <treecell>. Все они находятся в тегах <tree> и <treechildren>. Очевидно, что содержание, извлеченное из RDF файла, одинаково в обоих случаях, но структура, внешний вид и способ использования различны. Например, строки дерева могут быть выбраны пользователем, а строки текста слева - нет. В итоге можно сказать, что шаблоны объединяют данные, полученные в результате обработки запроса, с иным контентом, определяющим, как эти данные должны быть представлены. 14.2.2.1. Шаблоны и поддеревья контентаТеги XUL, относящиеся к системе шаблонов, не отражены в конечном, видимом документе. Отображены теги, генерируемые системой. Оба типа тегов присутствуют в XUL документе одновременно, но теги шаблонов имеют такие стили, что не отображаются. Теги шаблона формируют одно DOM поддерево XUL документа. После того, как шаблон генерирует свой контент, эти теги могут использоваться только для ссылок. Система шаблонов может перечитать такой тег, если прикладной программист добавит соответствующий скрипт. Сгенерированные теги формируют поддерево DOM для каждого решения, найденного шаблонным запросом. Три решения дадут три поддерева. Эти поддеревья скажутся при любом обращении к ним пользователя или события, вызванного скриптом. Каждое из сгенерированных поддеревьев имеет тег верхнего уровня. Этот тег получит уникальный id атрибут, равный URI подлежащего факта, найденного запросом. Этот id используется как уникальный ключ для идентификации каждого поддерева. Пример "hello, world", приводившийся в начале главы, показывает эти поддеревья на снимке. 14.2.2.2. Динамический контентШаблоны могут изменяться во время работы. Генерируемый ими контент тоже может меняться. Оба эффекта требуют применения JavaScript, и оба могут требовать очередного выполнения шаблонного запроса. Шаблоны могут и задерживать результат ("ленивое" порождение контента). Для пересчета шаблона необходима одна строка на JavaScript. Не нужно перегружать никаких документов. Часть XUL документа, содержащая шаблон, и результат его работы изменяются "на лету". Окружающий контент не будет затронут, за исключением, возможно, оформления. Вот типичная строчка, выполняющая эту работу: document.getElementByTagName('tree').database.rebuild();
Теги шаблона также можно изменять, используя операции DOM 1, такие как removeChild() и appendChild(). Однако если так сделать, выведенное на экран содержание будет изменено при пересчете шаблона. Если шаблон не изменит результатов запроса, выведенное на экран содержание все равно изменится, когда изменятся RDF данные, которые использует шаблон. Если шаблон будет пересчитан, появится новый контент, соответствующий новым решениям, а контент, соответствующий старым решениям, исчезнет. Система шаблонов сама вносит эти изменения, используя операции DOM 1. XUL документы не только задействуют шаблоны повсеместно, но и могут использовать их вновь и вновь в любое время. 14.2.2.3. Отложенное ("ленивое") порождение контентаПорождение контента может быть отложено. Это возможно только для рекурсивных запросов. Когда используются рекурсивные запросы, ищутся лишь решения верхнего уровня. На их основании строится контент. Позже, если приходит сигнал от пользователя или платформы о том, что требуется еще порция контента, ищутся очередные решения. Затем новые решения добавляются к тем, что были выведены на экран ранее. "Ленивое" вычисление работает, только если теги шаблона, имеющие атрибут uri - следующие: <menu> <menulist> <menubutton> <toolbarbutton> <button> <treeitem> Дочерние теги этих тегов, такие как тег <menu> в <menulist> строятся "лениво". Шаблоны, использующие <tree> или <menu>, могут откладывать часть работы на более позднее время. 14.2.2.4. Разделяемый контентДва или большее количество шаблонов могут использовать одни и те же RDF данные. Если RDF данные изменяются, эти изменения отображаются во всех шаблонах одновременно. Чтобы изменения отобразились, шаблоны должны быть пересчитаны. Каждый шаблон работает как некий обозреватель RDF данных. Это очень мощное и полезное свойство шаблонов. Оно позволяет по- разному взглянуть на одно и то же множество данных одновременно, и при этом своевременно отображать изменения. Это используется, в частности, в тех приложениях, где применяется метафора рабочего стола. Например, в дизайнерских инструментах или Integrated Development Environments (IDE). Эти приложения должны визуализировать данные для пользователя несколькими способами одновременно. Это свойство также используется в классической Mozilla в системе закладок, адресной книге и кое-где еще. Чтобы увидеть эффект одновременного изменения контента в нескольких шаблонах, выполним следующий тест:
Менеджер Закладок содержит шаблон, основанный на теге <tree>. Персональная Панель инструментов - на теге <toolbar>. Элемент меню "Уничтожить" запустит скрипт, который уничтожит факт, содержащий информацию о новой закладке. Этот же скрипт предписывает обоим шаблонам пересчитать содержание. Части контента, ассоциируемые с этим уничтоженным фактом, (<treeitem> в одном случае, и <toolbarbutton> в другом) исчезнут из списка найденных результатов. 14.2.3. Доступ с помощью JavaScriptСистема шаблонов добавляет объекты к AOM XUL-документа. Она использует также несколько XPCOM компонентов и интерфейсов, в частности, RDF. Ими можно управлять из JavaScript. JavaScript может выполнять следующие задачи:
Эти задачи будут описаны в разделе "Скриптинг". Они часто требуют работы с компонентами XPCOM, поддерживающими RDF. Эти компоненты обсуждаются в главе 16, "Объекты XPCOM". 14.2.4. Источники данныхПоследний технический аспект шаблонов - источники данных. Данные RDF, используемые шаблоном, могут извлекаться из обычного RDF документа или порождаться самой платформой. В любом случае, между шаблоном и реальным источником RDF фактов находится объект, называемый "источником данных". Шаблоны Mozilla могут извлекать факты из более чем одного источника одновременно. Это значит, что, например, факты из более чем одного RDF файла могут вносить свою лепту в контент, генерируемый шаблоном. Это связь типа многие-со-многими между источниками данных и шаблоном. Источники данных подробно рассматриваются в главе 16, "Объекты XPCOM". Здесь же мы только отметим, что выбор источника данных для шаблона критичен. Если неправильно выбрать источник, вряд ли будет много толку. Необходимо знать свои источники данных. Вот краткий обзор основных моментов. Каждый шаблон имеет комплексный источник данных. Чтобы воздействовать на источник данных шаблона из скрипта, зачастую необходимо найти и использовать один из конкретных источников данных, вносящих свой вклад в результирующий комплексный источник. Этот конкретный источник - список RDF фактов. В принципе, возможен полный набор операций, напоминающих операции с базами данных. Практически же полезны лишь источники данных из RDF файлов и система закладок. Система закладок имеет тот недостаток, что ее код нечитаем. Из других внутренних источников данных одни читаются легко, другие нет. Чтобы начать с пустого множества фактов и заполнять его вручную, удобно начинать с источника данных rdf:null. Так часто поступают, когда конструируют пользовательский снимок дерева данных. Раздел этой главы, посвященный скриптам, описывает некоторые распространенные манипуляции с источниками данных. Рекомендуется изучить также лекцию 16, "Объекты XPCOM". 14.3. Конструкция шаблоновВ данном разделе обсуждается, как шаблон собирается из составляющих его частей, и рассматриваются конкретные теги. Общая конструкция шаблона приведена в листинге 14.8. Это псевдокод, а не XML: <top>
<stuff/>
<template>
<rule> ... simple or extended rule info goes here ... </rule>
... zero or more further <rule> tags go here ...
</template>
<stuff/>
</top>
Листинг
14.8.
Базовая конструкция иерархии тегов шаблонаЗдесь тегом, названным <top>, может быть любой обычный XUL тег - <top> не реальный тег. Хотя собственно шаблон начинается тегом <template>, некоторые атрибуты шаблонов могут быть добавлены и к тегу <top>. Другой XUL-контент может предшествовать или окружать тег <top>. Типичные кандидаты для тега <top> - это <tree>, <toolbar>, <menulist>, и <listbox>, но <top> может быть и <box> или даже <button>. Тег, названный здесь <stuff>, тоже может быть обычным XUL тегом, это не реальный тег. Эти теги опциональны и их может быть любое число. Теги между <top> и <template> копируются и генерируются лишь однажды для каждого шаблона и отображаются графически также единожды перед содержанием шаблона. Тег <template> - реальный XUL тег. Любой XUL-контент внутри этого тега генерируется один раз для каждого решения, найденного запросом. Тег <template> окружает весь контент, который должен повторяться. Тег <rule> - также реальный XUL-тег. Это единственный контент, разрешенный внутри тега <template>. Может быть один или более тегов <rule>, и предусмотрена также сокращенная запись, позволяющая не писать ни одного. Каждый тег <rule> отвечает за один запрос шаблона, как описывалось раньше, в разделе "Списки запросов". Каждый тег <rule> также содержит контент. Этот контент воспроизводится каждый раз, когда запрос находит решение. Система шаблонов имеет несколько разных синтаксисов тега <rule>. Наиболее гибкий и мощный - расширенный синтаксис шаблона. Этот синтаксис требует, чтобы переменные запроса были определены в одном месте, а применялись впоследствии в другом. Такие переменные называются расширенными. Расширенный синтаксис требует, чтобы каждый тег <rule> содержал ряд специальных тегов шаблона как часть его контента. Удобный и краткий синтаксис - простой синтаксис шаблона. Этот синтаксис реализован для специального, но широко распространенного случая, когда запрос обращается к контейнеру RDF данных. Пример "hello, world" из листингов 14.6 и 14.7 использует простой синтаксис. Переменные в простом синтаксисе называются простыми переменными шаблона. Простой синтаксис требует, чтобы тег <rule> содержал только простой XUL контент. Этот контент может содержать простые переменные. Когда запрос шаблона находит решение, переменная замещается найденными данными факта. Если шаблон имеет только один тег <rule>, то простой синтаксис имеет еще и краткую запись. Теги <rule> и </rule> можно отбросить. Краткая запись - иной способ записи простого синтаксиса. См. детальное описание тега <rule>. 14.3.1. Специальные XUL именаСистема XUL шаблонов имеет несколько специальных имен. Переменные шаблонов не используются нигде, кроме как внутри тега <template>. 14.3.1.1. Расширенные переменные шаблоновРасширенные переменные шаблонов Mozilla - это переменные, используемые для простых (single fact) запросов и гибких комплексных RDF запросов. Такие переменные всегда появляются внутри XML строк. Расширенные переменные шаблона начинаются со знака вопроса ("?") и могут содержать любые символы. Регистр букв имеет значение. Они заканчиваются либо пробелом, либо знаком шляпки, или циркумфлекса ("^"), либо концом той строки, в которой они нам встретились. Пробел или шляпка не являются частью переменной. Если встречается пробел, он считается первым знаком контента, не относящимся к переменной. Если шляпка, она просто игнорируется. Следующие имена переменных идентичны. Третий пример содержит XML сущность, означающую пробел. "?name " "?name^" "?name& #x20;" Следующие примеры - тоже правильные имена. Мы рекомендуем, однако, всегда использовать значащие имена. "?name_two" "?nameThree" "?name-four" "?name66" " ?66name" "?$%@$z+" 14.3.1.2. Простые переменные шаблоновПростая запись для правил (см. тег "<rule>") имеет свои "переменные". Эти переменные - попросту URI предикатов факта. Такие переменные всегда появляются внутри XML строк. Простые переменные имеют формат: rdf:URI Такие переменные также оканчиваются пробелом (" ") либо шляпкой ("^"), либо заканчиваются вместе с содержащей их строкой. Пробел и шляпка не являются частью переменной. Пробел считается первым символом контента, не являющимся переменой, шляпка просто игнорируется. Часть простой переменной, являющаяся URI, должна быть валидным URI. Если переменная должна быть обработана содержательно, URI должен соответствовать контексту, в котором используется. Примеры содержательных URI: "rdf:urn:test:example:more" "rdf:http://www.test.com/Test#Data" 14.3.1.3. Интерполяция переменныхИ расширенные, и простые переменные используются только в значениях XUL атрибутов. Когда контент генерируется шаблоном, переменные замещаются найденными значениями. Когда запрос находит решение, генерируется контент. Когда это случается, имена переменных в содержащих их строках просто замещаются их значениями. Если при этом переменная не имеет обосновывающего ее значения (это возможно, если используется тег <binding>), то она замещается строкой длины ноль. 14.3.1.4. Специальные URI и пространства именСистема шаблонов использует несколько специального вида URI и пространств имен. URI схема "rdf" используется для представления данных, генерируемых самой платформой Mozilla. Вот список URI такого типа, реализованных в настоящее время: rdf:addressdirectory rdf:bookmarks rdf:charset-menu rdf:files rdf:history rdf:httpindex rdf:internetsearch rdf:ispdefaults rdf:local-store rdf:localsearch rdf:mailnewsfolders rdf:msgaccountmanager rdf:msgfilters rdf:smtp rdf:subscribe rdf:window-mediator Есть два специальных вида такого типа URI. URI: rdf:null означает использование источника данных, не содержащего фактов. Такой источник данных, как правило, получит данные позднее из JavaScript. URI: rdf:* специфичная только дл Mozilla запись, означающая "соответствует любому предикату". Использование звездочки ("*") навеяно ее применением в CSS2 - in CSS2 она тоже означает "соответствует всему". Этот URI следует рассматривать как специальный случай простой переменной. Он не идентифицирует определенный ресурс. Есть также устаревшая запись для этого случая: ... Эта запись идентична эллипсису (троеточию), за исключением того, что это не один знак, а три отдельные точки. Такая устаревшая запись означает то же самое, что и rdf:*, но теперь ее не следует использовать. В таблице 11.3 приведены пространства имен, применяемые Mozilla для работы с фактами RDF. Если шаблон использует внутренние источники данных, эти пространства имен можно задействовать для идентификации предикатов/свойств в этих источниках данных. В XML часто используют атрибут xmlns, чтобы заменить длинный URL пространства имен коротким алиасом. В системе шаблонов практически всегда следует использовать полный URL, а не алиас. Это не следует из XML стандарта, просто Mozilla так устроена. Если алиас употреблен в значении атрибута, он не будет заменен полным именем средствами самого XML. Значит, обрабатывать эти имена приходится платформе. Mozilla не знает, как определить или расшифровать алиасы xmlns внутри значений атрибутов, поэтому требуется полный URL. Единственное место, где можно использовать алиас xmlns, это атрибут тега <rule>. В этом случае алиас используется как имя атрибута, а не как его значение, и может быть обработан стандартными средствами парсинга XML. 14.3.2. Основные тегиТег верхнего уровня шаблона - родительский тег <template>. Он называется базовым тегом шаблона. Это обычный XUL-тег, наподобие <tree> или <box>. Этот тег должен содержать часть конфигурационной информации шаблона. Специальные атрибуты, которые могут быть добавлены к такому тегу верхнего уровня: datasources flags coalesceduplicatearcs allownegativeassertions xulcontentgenerated ref containment Атрибут datasources означает, что в шаблоне будут использоваться RDF данные. Это разделенный пробелами список имен RDF файлов, таких как test.rdf, и имен источников данных, таких как rdf:bookmarks. Поскольку атрибут datasources может иметь один или более аргументов, он всегда является комплексным источником данных (имеющим интерфейс nsIRDFCompositeDataSource). Если XUL-документ инсталлирован в chrome, либо безопасность обеспечена каким-то иным образом, в начало списка источников данных автоматически добавляется внутренний источник: rdf:local-store. Этот источник добавляет информацию о конфигурации профиля пользователя из файла localstore.rdf. Это важно, потому что часто приходится обращаться к источникам информации из скриптов, и прикладной программист должен знать, что информация доступна. Атрибут flags используется для оптимизации выполнения шаблонного запроса. Он применим только для рекурсивных запросов и принимает список ключевых слов, разделенных пробелами. В настоящее время поддерживаются два ключевых слова. dont-build-content. Это ключевое слово относится к шаблонам деревьев. Оно предписывает стандартному конструктору шаблона передать ответственность по выводу на дисплей найденного контента встроенному конструктору дерева. Конструктор шаблона по-прежнему генерирует контент, основанный на RDF, но он используется только как снимок, который задействует конструктор дерева. Различные конструкторы описываются в главе 13, "Списки и деревья". Преимущество этой системы состоит в том, что генерация контента откладывается до тех пор, пока его не нужно будет выводить на экран. Это выгодно, когда генерация контента требует большой вычислительной мощности, например запрос к серверу каталогов. Таким образом можно и уберечь систему от "вспышек" ("flashing"), то есть вывода части информации на экран до завершения выполнения запроса. dont-test-empty. Это ключевое слово предписывает запросу не обследовать контейнер, чтобы узнать, не пуст ли он. Это оптимизация, которая позволяет не выполнять тест, который может оказаться весьма дорогим. Она также позволяет системе шаблонов справиться с динамическими иерархическими данными, где такой тест вообще невозможен. Например, исследование сети может привести к такой ситуации. В этом случае ответить на вопрос "не пусто ли множество элементов сети?" невозможно, потому что код может ожидать, пока придет ответ "нет" бесконечно. dont-test-empty - удачный выбор для шаблонов, основанных на источнике данных rdf:null. coalesceduplicatearcs, allownegativeassertions, и xulcontentgenerated также несколько улучшают быстродействие и модифицируют запрос. Атрибут coalesceduplicatearcs, когда он указан, затрагивает факты, которые могут быть извлечены из нескольких источников данных шаблона. Большинство флагообразных атрибутов в Mozilla считаются установленными, когда их значение равно true. Не так устроен этот атрибут, его значение должно быть false. Он воздействует на то, каким образом JavaScript обращается с фактами, а не с результатами запроса. Если этот атрибут не установлен, идентичные данные из различных источников данных шаблона будут обнаружены лишь единожды, а не по одному результату на копию. Если он имеет значение false, все факты будут обнаружены, независимо от того, дублируются они или нет. Запросы выполняются быстрее, если этот атрибут установлен. Атрибут allownegativeassertions, когда он установлен, также затрагивает факты, которые могут быть извлечены из нескольких источников данных шаблона. Большинство флагообразных атрибутов в Mozilla считаются установленными, когда их значение равно true. Но этот атрибут также может быть установлен в значение false. Он воздействует на то, как JavaScript обращается с фактами, а не с результатами запроса. Если этот атрибут не установлен, факт, который утверждается и позитивно, и негативно, никогда не будет обнаружен, поскольку два факта "погасят" друг друга. RDF документы содержат только позитивно установленные факты. Негативные факты можно постулировать, только используя JavaScript. Если этот атрибут установлен, взаимного погашения не произойдет, и обо всех фактах будет сообщено. Запросы выполняются быстрее, если этот атрибут установлен. Атрибут xulcontentgenerated применим к любому тегу в шаблоне, и к любому тегу, сгенерированному шаблоном. Он приведен в данном списке атрибутов, поскольку он также влияет на оптимизацию. Начинайте экспериментировать с этим атрибутом только после того, как полностью разберетесь с шаблонами. Атрибут xulcontentgenerated может иметь значение true. Он сказывается в тот момент, когда запрос еще выполняется, а контент генерируется. Если шаблон строится лениво, то в каждый момент часть контента уже порождена, а часть нет. Если мы обращаемся к тегу с какой-либо DOM операцией (наподобие добавления дочернего тега), а тег имеет неполный, ленивый контент, может возникнуть неясность. Куда добавить дочерний тег, если множество дочерних тегов еще только предстоит вычислить? Mozilla решает эту проблему, просто заставляя шаблон породить необходимый контент перед выполнением DOM операций. Атрибут xulcontentgenerated отменяет эту работу, чтобы ничего не пересчитывалось в данный момент в XUL дереве. Это ускоряет DOM операции и отменяет ненужные вычисления. Атрибут ref определяет начальную точку запроса. Он содержит полный URI подлежащего в факте. Этим подлежащим должно быть имя <Seq>, <Alt>, или <Bag> контейнера. Атрибуты ref и containment обсуждаются в следующем разделе. 14.3.2.1. Атрибуты ref и containment: тесты контейнераАтрибуты ref и containment можно использовать, чтобы определить стартовую точку запроса, который не задействует официальный RDF-тег container. Это полезно для простых RDF фактов, образующих простую иерархию, но не использующих теги <Seq>, <Bag>, или <Alt>. Эти псевдоконтейнеры нуждаются в дополнительном комментарии. Рассмотрим обычный RDF-контейнер. Пример приведен в листинге 14.9. <Description about="urn:eg:ownerA">
<prop1>
<Seq about="urn:eg:ContainerA">
<li>
<Description about="urn:eg:item1" prop2="blue"/>
</li>
</Seq>
</prop1>
</Description>
Листинг
14.9.
Фрагмент RDF контейнера, содержащего три факта.Предикаты в этом примере умышленно выбраны простыми. Листинг 14.9 эквивалентен трем фактам: <- urn:eg:ownerA, prop1, urn:eg:containerA -> <- urn:eg:containerA, rdf:_1, urn:eg:item1 -> <- urn:eg:item1, prop2, blue -> Первый факт в качестве подлежащего имеет RDF контейнер. Это факт, который "владеет" контейнером. Второй факт сообщает, что item1 - член этого контейнера. В третьем факте записана некоторая полезная информация о цвете данного item1. Это все обычный RDF. Эти три факта прямо следуют из синтаксиса <Seq> листинга 14.9. Предположим, программа имеет информацию об этих трех фактах, а не исходный RDF файл. Как она может узнать, был ли контейнер? В данном простом случае нам достаточно заметить предикат rdf:_1, чтобы понять, что container A и есть RDF контейнер. В Mozilla выполняются различные тесты (включая rdf:instanceOf predicate), но в этом примере достаточно заметить rdf:_1. Теперь предположим, что в эти три факта внесено единственное изменение. Пусть предикат rdf:_1 был заменен на rdf:member (или что- нибудь еще). Тогда три факта будут выглядеть так: <- urn:eg:ownerA, prop1, urn:eg:containerA -> <- urn:eg:containerA, rdf:member, urn:eg:item1 -> <- urn:eg:item1, prop2, blue -> В Листинге 14.10. показан фрагмент RDF, который может соответствовать этим измененным фактам. Это просто серия вложенных фактов: <Description about="urn:eg:ownerA"> <prop1> <Description about="urn:eg:ContainerA"> <rdf:member> <Description about="urn:eg:item1" prop2="blue"/> </rdf:member> </Description> </prop1> </Description>Листинг 14.10. Фрагмент RDF без контейнера, соответствующий трем фактам. Есть ли по-прежнему контейнер в этих трех фактах? В конце концов, оба случая так похожи. Можно утверждать, что контейнер действительно существует. Во-первых, способ организации трех фактов не изменился. Во-вторых, выбор rdf:member в качестве предиката предполагает, что item1 принадлежит чему-то. В-третьих, любой запрос, построенный с тегом <Seq>, может работать с новым предикатом точно так же, как он работал со старым. Суть в том, что рассматривая RDF разметку, мы можем решать для себя, существует контейнер или нет. Можно создать RDF документ без тега container, но продолжать рассматривать RDF так, как будто контейнер существует. Почему же Mozilla должна выбрать одну точку зрения, а не другую? Здесь нам придется снова рассмотреть атрибут ref. Он может быть установлен в значение "urn:eg:ContainerA", и этот ресурс может служить начальной точкой запроса, независимо от того, выглядит ли листинг исходного RDF как 14.9 или 14.10. RDF теги <Seq>, <Bag>, или <Alt> необязательны. При данном гибком использовании ref есть одна хитрость. Mozilla нужно определить, можно ли использовать данный ref URI как контейнер. Существует три стандартных способа выяснить, пройдет ли ref URI этот тест:
Для Mozilla проверка на эти условия эквивалентна проверке на rdf:_1. Если вы не хотите использовать предикаты child или Folder в своих фактах, вы не обязаны это делать. Вы можете использовать ваши собственные предикаты. Чтобы это сделать, создайте RDF контент так, как вам нужно, а в коде XUL шаблона добавьте атрибут containment к основному тегу шаблона. Атрибут containment может содержать список предикатов, разделенных пробелами. Эти предикаты будут добавлены к списку тестов контейнера. Эти предикаты будут тестироваться точно так же, как тестировались элементы в предыдущем списке. Например, запись containment="http://www.test.com/Test#member" означает, что RDF тег <Description> будет рассматриваться Mozilla как контейнер, при условии, что xmlns:Test="http://www.test.com/ Test#" было декларировано где-либо ранее: <Description about="urn:foo:bar"> <Test:member resource="urn:foo:bar:item1"/> <Description> Итак, запрос шаблона будет работать, даже если не существует стандартных RDF тегов container. В этом случае необходимо указать системе шаблонов, какие предикаты должны быть использованы для реализации данного нестандартного контейнера. 14.3.2.2. Специальные атрибуты тега <tree>Если для шаблона используется тег <tree>, применимы добавочные атрибуты: flex="1" statedatasource flags="dont-build-content" Деревья не имеют значения атрибута height по умолчанию. Если шаблон <tree> не имеет атрибута flex="1", содержание шаблона зачастую может не появиться на экране вообще. Всегда используйте flex="1" в шаблоне <tree>. Атрибут statedatasource - устанавливается для именованного источника данных, используемого для сохранения текущего состояния дерева. Если пользователь откроет или закроет ряд поддеревьев на экране, информация о том, какие поддеревья открыты, а какие закрыты, будет сохранена в этом именованном источнике данных. В настоящее время это используется только в почтовом клиенте Mozilla, на панели, где перечисляются папки. Если атрибут statedatasource не установлен, используется источник данных, названный в атрибуте datasources. Значение "dont-build-content" атрибута flags также используется только для деревьев. Оно описывается в разделе "Основные теги". 14.3.2.3. Поддержка сортировки для дочерних тегов <template>Система шаблонов позволяет сортировать колонки данных. Это свойство реализовано для XUL меню, списков и деревьев. Процесс сортировки использует несколько атрибутов. Они могут быть установлены для базового тега шаблона, либо для конкретных тегов <listcol> или <treecol>. Это следующие атрибуты: resource resource2 sortActive sortDirection sortResource sortResource2 Атрибут resource содержит переменную шаблона. Автор XUL-документа указывает его для колонки, которая должна быть отсортирована. Этот атрибут указывает ключ, содержащий данные, которые должны сортироваться. Переменная шаблона, который он именует, представляет предикат/свойство факта, дающего решение запроса для каждой строки. Данные, используемые как ключ для сортировки, являются дополнением/значением этого предиката. Другими словами, данный атрибут указывает свойство, чье значение для каждой строчки должно сортироваться. sort - альтернативный синтаксис для атрибута resource. Его также применяют, чтобы указать сортируемую колонку в списке или дереве. Используйте resource и sortActive, но не этот атрибут. resource2 - вторичный предикат для сортирующего механизма. Сортировка по значениям, указанным в resource, нестабильна. Это означает, что после выполнения сортировки вторая колонка информации может быть неупорядочена. Вторичный предикат используется, чтобы отсортировать значения во второй колонке, если значения в первой одинаковы. Тем не менее, третья и последующие колонки могут быть не отсортированы. sortActive может принимать значение true и указывать тем самым, была ли произведена сортировка. Mozilla автоматически устанавливает этот атрибут на нужную колонку списка или дерева. Его может указать и программист приложения. Его можно использовать для доступа к колонке, которая должна сортироваться, то есть его следует указывать всегда, если не использован атрибут sort. sortDirection может принимать значения ascending, descending, или natural. Он может быть установлен автором XUL документа или Mozilla автоматически после сортировки. Mozilla установит его одновременно и на рассматриваемую колонку, и на базовый тег. sortResource и sortResource2 - то же самое, что и resource и resource2. Эти атрибуты устанавливает Mozilla. Вторичный критерий сортировки может быть установлен программистом с помощью JavaScript, но не прямо в XUL. sortSeparators может принимать значение true. Если он установлен, закладки сортируются особенным образом. Сортировка не перемещает элементы за границы разделителей закладок, если этот атрибут установлен и используется источник данных rdf:bookmarks. 14.3.3. Тег <template>Тег <template> содержит все детали информации о шаблоне, которые не были указаны в базовом теге. Он содержит набор правил, каждое из которых - пара запрос-контент. Тег <template> не имеет собственных атрибутов. Единственный тег, который он может содержать - тег <rule>. Зато он может содержать произвольное их число. Если тегов <rule> нет, но есть иной контент, этот контент считается единственным правилом с синтаксисом для простых правил. Тег <template> может содержать простые и расширенные правила. 14.3.4. Тег <rule>Тег <rule> определяет единичный запрос шаблона и контент, генерируемый для оформления вывода результатов запроса. Несколько тегов <rule> формируют список запросов. Таким образом, первый тег <rule> будет формировать оформление результатов запроса. Правила могут быть записаны с помощью простого и расширенного синтаксисов. Если первый дочерний тег тега <rule> - это тег <conditions>, правило должно быть записано в расширенном синтаксисе. В любом другом случае применим простой синтаксис. Тег <rule> может быть единственным тегом без какого-либо контента. 14.3.4.1. Стандартное устройство фактаВсе запросы с простым синтаксисом и многие с расширенным основываются на фактах в RDF-файле, которые упорядочены определенным образом. Это упорядочение может повторяться. Это тот случай, когда RDF-данные имеют устройство "три ступени, два факта". Ступени - контейнер, его элементы и им принадлежащие пары свойство-значение. Листинги 14.1 и 14.2 и их обсуждение демонстрируют пример данного устройства. Это стандартное устройство также эквивалентно JavaScript: var container = {item1:{p1:v1,p2:v2}, item2:{p1:v1,p3:v3}}
В этой строке контейнер содержит два элемента. item1 и item2 - это объекты, каждый из которых имеет множество свойств pN. Каждое свойство имеет значение vN. Может быть любое число элементов, каждый с любым числом свойств. Суть такой структуры - дать легкий доступ ко множеству объектов и интересующим нас свойствам. Листинги 14.2, 14.5, 14.7, и 14.9 являются корректными примерами этой структуры в RDF. Листинг 14.11 показывает RDF-эквивалент структуры, описываемой строкой JavaScript. <Seq about="container"> <li resource="item1"/> <li resource="item2"/> </Seq> <Description about="item1" p1="v1" p2="v2"/> <Description about="item2" p1="v1" p3="v3"/>Листинг 14.11. RDF структура для RDF правила с простым синтаксисом Чтобы сделать RDF синтаксис яснее, тег <Seq> обычно заворачивают в тег <Description>, не показанный в листинге 14.11. RDF имеет гибкий синтаксис, и существует несколько других путей выразить ту же самую структуру. Тег <Seq> может быть, кроме того, заменен на <Bag> или <Alt>. Вместо них можно использовать тег <Description> в роли контейнера. Все факты, которые обрабатываются запросом с простым синтаксисом, должны иметь это стандартное устройство. 14.3.4.2. Простой синтаксис тега <rule>Простой синтаксис тега <rule> не имеет специальных тегов. Весь контент тега <rule> генерируется каждый раз, когда запрос находит решение. Контент тега <rule> может содержать простые переменные шаблона, помещенные в любое значение атрибута XML. Контент генерируется так же, как для тега <action>, за исключением двух незначительных отличий: простой синтаксис требует, чтобы атрибут uri имел значение rdf:*, и простой синтаксис не может использовать тег <textnode>. Когда применяется простой синтаксис, тег <rule> имеет несколько специальных атрибутов: type iscontainer isempty predicate="object" parsetype Все эти атрибуты определяют, будет ли запрос правила успешен. Часть запроса определяется предположением, что RDF факты имеют стандартное устройство. Данные атрибуты определяют остальную часть. Атрибут type взят из официального пространства имен RDF XML http://www.w3.org/1999/02/22-rdf-syntax-ns#. Его обычно записывают как rdf:type, включая это пространство имен ранее где-либо в документе XUL с помощью xmlns. Можно указать rdf:type и с полным именем предиката, как http://home.netscape.com/NC-rdf#version. Этот атрибут используется для проверки существования предиката. То есть rdf:type проверяет, существует ли в контейнере объект, имеющий такое свойство. Если нет, данный кандидат на решение отбрасывается. Атрибут iscontainer может иметь значение true или false. Значения по умолчанию нет. Он проверяет, является ли подлежащее данного факта контейнером, используя "тесты контейнера", описанные ранее в разделе "Атрибуты ref и containment: Тесты контейнера". Если тесты не проходят, правило отвергает данного кандидата на решение. Атрибут isempty может иметь значение true или false. Значения по умолчанию нет. Он проверяет, содержит ли данный URI какую-либо разновидность контента. В случае значения true он проверяет, имеет ли подобный контейнеру URI какие-либо элементы содержания контейнера, а элементоподобный URI - какие-либо свойства. Если тест не проходит, правило отвергает данного кандидата на решение. Атрибут predicate="object" означает любую пару имен предиката и дополнения. Поскольку имена предикатов зачастую длинны, их сокращают, добавляя xmlns-декларацию в начале XUL документа. Если это сделано, пара predicate="object" наподобие NC:version="0.1" проверяет, существует ли предикат version в пространстве имен NC (вероятно, http://home.netscape.comNC-rdf#) и имеет ли он дополнение со значением "0.1" - иными словами, имеет ли объект в контейнере свойство version со значением "0.1". Следующие зарезервированные имена не могут применяться для предиката, поскольку они используются иным образом: property instanceOf id parsetype Эти три атрибута, плюс любое число тестов predicate="object", могут содержаться в одном теге <rule>. Они соединены между собой булевым AND и относятся ко всем запросам правила. Если никакой из них не указан, то любой факт в контейнере является решением для запроса. Если любой из них присутствует, запрос не найдет решения, если хоть какой-то из этих атрибутов не удовлетворяется. Последний атрибут, parsetype, может иметь значение Integer. Если это указано, во всех парах predicate="object" часть "объект" будет интерпретироваться как целое. Любое нецелое значение приведет к тому, что весь запрос будет проигнорирован. Если атрибут не используется, объектные части пар интерпретируются как строки. Система запросов не имеет встроенной математики для, например, складывания целых. Она лишь выясняет, целое перед ней или строка. Запрос в простом правиле обычно может быть выражен и как расширенное правило. Листинг 14.12 - пример простого синтаксиса, использующего некоторые из специальных атрибутов. <rule iscontainer="true" isempty="false" rdf:type="http://home.netscape.com/NC-rdf#version" NC:title="History" >Листинг 14.12. Простой шаблонный запрос, демонстрирующий все опции. Эквивалентный расширенный синтаксис приведен в листинге 14.13. <rule>
<conditions>
<content uri="?uri"/>
<member container="?uri" child="?item"/>
<triple subject="?item
predicate="http://home.netscape.com/NC-rdf#version"
object="?version"/>
<triple subject="?item"
predicate="http://home.netscape.com/NC-rdf#title"
object="History"/>
</conditions>
Листинг
14.13.
Простой шаблонный запрос, демонстрирующий все опции.Расширенный синтаксис может делать все то же, что и простой, за исключением опций iscontainer="false" и isempty="true" (значения, противоположные приведенным в примере в листинге 14.12). Эти две опции в расширенном синтаксисе невозможны. Расширенный синтаксис может проверить существование факта, но не его отсутствие. Эти простые проверки все же можно осуществить в расширенном синтаксисе, указывая два правила, а не одно. Первое правило проверяет наличие конкретного факта, но не генерирует контента, второе отбирает оставшиеся случаи, в которых контент отсутствует, и генерирует требуемый. 14.3.4.3. Расширенный синтаксис <rule>Когда используется расширенный синтаксис, тег <rule> не имеет специальных атрибутов. Этот синтаксис - наиболее гибкий и мощный из всех синтаксисов шаблонов. В разделе "Часто встречающиеся образцы запросов" приведены рецепты для наиболее распространенных случаев. В данном же разделе описываются опции синтаксиса. Расширенный синтаксис правил состоит из тега <rule> с двумя или тремя дочерними тегами. Тег <conditions> должен быть первым из дочерних тегов и должен содержать запрос правила. Тег <bindings> - необязательный средний тег, позволяющий создавать дополнительные переменные. Тег <action> содержит тот контент, который следует генерировать при каждом обнаружении решения. Эти теги рассматриваются каждый в своем подразделе. Расширенный синтаксис правил использует расширенный синтаксис переменных, и эти переменные могут использоваться в дочерних тегах тега <template>. Обычно их помещают в теги определения колонок в списках и деревьях. Рекурсивность запроса указывается только в теге <conditions>. 14.3.5. Тег <conditions>Тег <conditions> содержит запрос шаблона, описанный расширенным синтаксисом. Этот тег не имеет собственных атрибутов. Если он присутствует, он должен быть первым тегом <rule>. Рекурсивность рекурсивного запроса полностью определяется контентом тега <conditions>. Этот тег может содержать теги <content>, <triple> и <member>. Первым дочерним тегом должен быть <content>, и этот тег должен быть ровно один. Тег <content> должен также содержать по крайней мере один тег <member> или <triple>. Тег <conditions> может содержать тег <treeitem>. Если шаблон основан на теге <tree>, то вместо тега <content> можно использовать <treeitem>. В этом случае он записывается и ведет себя точно так же. Нет никаких особенных причин поступать именно так, это всего лишь память "давно минувших дней". <treeitem> считается устаревшим, лучше использовать <content>, однако на старых версиях платформы следует использовать <treeitem>. Когда эти теги используются, их порядок должен соответствовать порядку перебора ("бурение" данных), используемому процессором запроса. То есть это тот же порядок, что и иерархический порядок самих исследуемых данных. 14.3.5.1. Тег <content>Тег <content> должен быть первым дочерним тегом тега <conditions>. Он имеет единственный специальный атрибут: uri Это атрибут расширенной переменной шаблона. Данная переменная затем обосновывается значением атрибута ref базового тега шаблона. Это значение является стартовой точкой запроса. Если запрос рекурсивен, вместо атрибута ref используется атрибут uri родительского запроса. Тег <content> всегда имеет одну и ту же форму, так что обычно он выглядит вот так: <content uri="?uri"/> Атрибут uri также используется в дочерних тегах тега <action>. Переменная, употребленная как атрибут uri тега <content>, никогда не должна употребляться как значение атрибутов uri, появляющихся в контенте тега <action>. Если ее использовать таким образом, запрос в шаблоне не обнаружит решений, и никакого контента не будет порождено. Переменная, используемая в атрибуте uri тега <content>, может появляться в любом другом месте контента тега <action>. Если шаблон основан на дереве, в версиях платформы младше 1.5 используется тег <treeitem>, вот так: <treeitem uri="?uri"/> Тег <treeitem> также может быть частью порождаемого контента. В этом случае он может присутствовать в теге <action>, но любой атрибут uri в качестве значения должен иметь переменную, отличную от ?uri. 14.3.5.2. Тег <triple>Тег <triple> представляет один шаг (одну арку в графе RDF) в процессе запроса. Каждый использованный тег <triple> увеличивает число шагов на единицу, и также на единицу увеличивает число фактов, требуемых для решения. Тег <triple> используется для связи фактов с переменными и для обнаружения фактов. Тег <triple> имеет следующие специальные атрибуты, которые должны всегда присутствовать. subject predicate object subject может принимать значение расширенной переменной шаблона или URI. predicate может принимать значение URI, то есть имя свойства/предиката. object может принимать значение расширенной переменной шаблона, URI или быть строкой. В атрибутах предиката нельзя использовать переменные. Можно сконструировать последовательность тегов <triple> так, что они образуют логическое кольцо. Ни одна из этих возможностей не обрабатывается Mozilla корректно. Тег <triple> с нулевыми переменными бесполезен. 14.3.5.3. Тег <member>Тег <member> используется для поиска элементов, содержащихся в теге-контейнере. Он имеет специальные атрибуты container child Атрибут container - это URI тега-контейнера. Атрибут child сравнивается с дополнениями фактов, имеющими подлежащим URI контейнера. Оба атрибута должны присутствовать, и обоим присваиваются расширенные переменные шаблона, вот так: <member container="?uri" child="?item"/> Поскольку искомые связи внутри RDF-контейнера - это просто единичные факты (имеющие rdf:_1 или что то подобное в качестве предиката), обычный тег <triple> может быть использован для поиска этих элементов. Тег <member> - попросту специализированная версия тега <triple>. Преимущество, которое имеет тег <member> перед тегом <triple> состоит в том, что можно вообще не указывать предикат. Тег <member> может применять тесты контейнера, описанные ранее в разделе "Атрибуты ref и containment: тесты контейнера". Чтобы выполнить ту же работу с тегом <triple>, придется задействовать добавочный запрос, указывающий URI, который можно использовать как тест контейнера. Хотя атрибут контейнера тега <member> часто содержит URI начальной точки запроса, в запросе можно использовать любой URI или расширенную переменную запроса. 14.3.6. Тег <bindings>Тег <bindings> - необязательная часть расширенного синтаксиса запроса. Он не имеет специальных атрибутов, и может содержать только теги <binding>. Теги <bindings> и <binding> постоянно используются в Mozilla, особенно в XBL. Между их применением в шаблонах и где угодно еще нет прямой связи. В терминах SQL, они являются реализацией инструкции "outer joins" и нулевых значений. Тег <bindings> следовало бы называть <extra-groundings>, поскольку это вовсе не "привязка" в смысле XBL (или XPConnect или IDL или XPIDL). binding-переменная это просто добавочная переменная, которая может быть обоснована добавочным запросом. Это же значение имеет и тег <binding>. Раздел правила <bindings> - это место, где можно поместить добавочные переменные, не ограничивая результатов <conditions> запроса. Сделать это очень просто. В секции <conditions> все переменные должны быть обоснованы, чтобы было найдено решение. Это решение передается в секцию bindings. Далее процессор запроса пытается обосновать все переменные, перечисленные в секции <bindings>. Если лишь некоторые из них удается обосновать, процессор просто присваивает остальным нулевые значения. Это значит, что решения <conditions> никак не ограничиваются переменными <bindings>. Фактически, секция <bindings> подобна RDBMS инструкции outer join - если что-то подходит, об этом сообщается, в противном случае вы получаете только то, что найдено по запросу. Переменные в секции <bindings> должны быть расширенными переменными шаблона. Переменные из раздела <conditions> можно использовать здесь, но не наоборот. Чтобы секция <bindings> имела смысл, должна быть использована по крайней мере одна из переменных секции <conditions>. 14.3.6.1. Тег <binding>Тег <binding> идентичен тегу <triple> по атрибутам и способу использования. Он отличается от <triple> только в правилах, применяемых для обоснования его переменных, как описано в разделе <bindings>. 14.3.7. Тег <action> и контент, порождаемый запросом с простым синтаксисомТег <action> используется в <rule> с расширенным синтаксисом запроса. Он дает контент, который будет генерироваться для каждого результата данного запроса. Контент правила <rule> с простым синтаксисом генерируется точно так же, как контент тега <action>. Здесь описывается система генерации. Контент тега <action> состоит из обычных XUL тегов и расширенных переменных запроса. Система шаблонов замещает значение каждой переменной при генерации контента. Таким образом, переменные используются в теге <action>, хотя определяются и обосновываются в теге <conditions> (они определяются и обосновываются автоматически при простом синтаксисе). Система шаблонов добавляет атрибут id каждому тегу каждый раз, когда генерируется контент. Тег <action> не может включать тег <script>. Контент тега <action> должен быть организован так, как показано в листинге 14.14 <action> // simple syntax:
<rule>
<box id="A">
<box id="B">
<box id="C" uri="?var"> // simple syntax: uri="rdf:*"
<box id="D"/>
<box id="E">
<box id="F"/>
</box>
</box>
</box>
</box>
</action>
Листинг
14.14.
Пример иерархического контента <action>.Мы используем этот пример, чтобы объяснить, что и как здесьработает. В общем случае теги могут вкладываться на произвольную глубину внутри <action>, и может быть использован любой XUL-код. Специальный случай шаблонов, основанных на деревьях, обсуждается отдельно. Контент тега <action> делится на тег, содержащий атрибут uri, порождающие его теги и наследующие ему теги. В листинге 14.14 С содержит uri; A и B - теги-предки; D, E и F - дочерние теги. Теги-предки A и B порождаются лишь однажды, независимо от того, как много решений обнаружит запрос. Если переменные запроса (расширенные для контента <action>, простые для контента <rule>) используются в A и B, они будут иметь значения, найденные в первом решении запроса. Если A и B имеют дочерние теги, эти теги могут быть неадекватны. Рекомендуется их избегать. Тег C - начало повторяющегося контента, поскольку он имеет атрибут uri. И С, и его контент могут генерироваться как целое ноль и более раз. Чтобы контент был сгенерирован хоть один раз, должны быть выполнены два условия. Во-первых, запрос должен обнаружить хоть одно решение. Во-вторых, значение атрибута uri тега C в этом обнаруженном решении должно быть другим. Самый простой способ удостовериться, что это именно так - установить его в значение переменной, упоминаемой как дополнение в некотором кортеже. Примером может быть часть child тега <member>. В этом случае необходимо использовать ?item: <member container="?seq" child="?item"/> В наиболее общем случае, атрибуту uri должно быть присвоено значение подлежащего или дополнения, разные для каждого решения, обнаруженного запросом. Атрибут id принимает данное уникальное значение для каждого тега C во время генерации контента. Тег C не должен иметь дочерних тегов, это может привести к ошибке. Рекомендуется в данном случае дочерних тегов избегать. Если требуется построение контента с задержкой ("ленивое"), тег C должен быть одним из следующих XUL-тегов: <menu> <menulist> <menubutton> <toolbarbutton> <button> <treeitem> Теги D, E, и F - обычные теги, генерируемые один раз на каждое найденное решение запроса. Они могут иметь дочерние теги и обширный собственный контент. Если эти теги имеют переменные шаблона, такие переменные будут замещены найденными решениями. 14.3.7.1. Контент шаблонов, основанных на теге <tree>Контент шаблонов, основанных на теге <tree>, может нарушать правило, согласно которому теги-родители uri-тега генерируются лишь однажды. Если шаблон основан на теге <tree>, каждый <treeitem> в финальном дереве может иметь тег <treechildren> как свой второй дочерний тег. Этот тег может содержать любое число поддеревьев. К счастью, контент тега <action> должен представлять единственную строку дерева. Конструктор шаблона, обрабатывающий тег <tree>, достаточно разумен, чтобы скопировать этот контент в каждое поддерево. Другими словами, он достаточно разумен, чтобы определить необходимость рекурсивного запроса. Контент тега <action> нужно прописать достаточно аккуратно, чтобы такая конструкция работала. Она показана в Листинге 14.15. <action>
<treechildren> //simple syntax: use <rule>
<treeitem uri="?var"> //simple syntax: use uri="rdf:*"
<treerow>
... any normal treerow content ...
</treerow>
</treeitem>
</treechildren>
</action>
Листинг
14.15.
Пример иерархического контента тега <action> для шаблона на теге <tree>.Все теги в этой конструкции могут иметь добавочные атрибуты. Не следует использовать атрибут id для тега <treeitem>. Переменная ?var обычно соответствует переменной в дополнении тегов <member> или <triple>. Данный синтаксис можно слегка изменить, и даже использовать такой шаблон внутри другого шаблона. Например, так, что тег <treeitem> порождается из одного источника RDF, а его дочерние теги <treechildren> - из другого. Подобные вложения следует тщательно тестировать, потому что они не используются широко и, следовательно, не являются достаточно надежными. Шаблоны, основанные на деревьях, используют рекурсивные запросы. С каждым шагом рекурсии вглубь дерева фактов контент тега <action> перед uri-тегом удваивается. Это означает добавочную копию тега <treechildren>, см. листинг 14.15. Эта новая копия становится затем отправной точкой для всех решений, найденных новым запросом. 14.3.7.2. Тег <textnode>И простые, и расширенные переменные могут появляться только в значениях атрибутов XML. Некоторые теги XUL порождают текстовое содержание между их открывающей и закрывающей частями. Например, тег <Description>. Тег <textnode> предоставляет способ поместить переменную в контент, не являющийся атрибутом. Предположим, переменная ?var в некоторый момент содержит строку "red". Тогда строка <tag> <textnode value="big ?var truck"/> </tag> будет эквивалентна строке <tag>big red truck</tag> Тег <textnode> можно поместить в любое место внутри тега <action>. Тег <textnode> не может быть использован, если запрос задействует простой синтаксис. На данном теге мы завершим рассмотрение тегов шаблона. 14.4. Часто встречающиеся образцы запросовВ шаблонах широко используются следующие запросы. 14.4.1. КонтейнерыНаиболее очевидные запросы шаблонов используют стандартную организацию фактов, а это означает применение RDF контейнера. Простой синтаксис запроса поддерживает эту организацию фактов. 14.4.2. Запросы одного фактаЗапросы одного факта (см. предыдущее обсуждение) можно сконструировать лишь с использованием расширенного синтаксиса запросов. Простой синтаксис использовать нельзя. Запросы одного факта могут возвратить ноль или более решений. Единственное неизвестное может быть лишь дополнением запрашиваемого факта. Подлежащее и предикат должны быть известны и вдобавок буквально указаны в запросе. Подобный запрос можно реализовать лишь с тегами <member> или <triple>. Если использовать тег <member>, это выглядит так: <rule>
<conditions>
<content uri="?uri"/>
<member container="?uri" child="?data"/>
</conditions>
<action>
<description uri="?data" value="?uri ?data"/>
</action>
</rule>
В данном случае, если предикат единичного факта не является фактом, содержащимся в контейнере (то есть rdf:_1, или некоторым специфичным для Mozilla значением, например child), то этот предикат должен быть указан в атрибуте containment. В данном атрибуте можно перечислить несколько альтернативных предикатов. В случае <triple> код выглядит так: <rule>
<conditions>
<content uri="?uri"/>
<triple subject="?uri" predicate="predURI" object="?data"/>
</conditions>
<action>
<description uri="?data" value="?uri ?data"/>
</action>
</rule>
Предикат - "predURI", выраженный литералом. Если требуется указать несколько предикатов, используйте несколько правил rule. 14.4.3. Набор свойствНабор свойств - это запрос, чьей целью является получение ряда элементов информации, связанных с подлежащим факта. Типичный пример, когда мы рассматриваем подлежащее как объект JavaScript и хотим получить значения свойств этого объекта. Другой пример - считать подлежащее факта идентификатором записи в базе данных и получить все элементы данной записи. Эти аналогии не противоречат обычному использованию терминов "свойство" и "значение" в RDF. Если подлежащее и его свойства являются членами RDF-контейнера, или контейнероподобного тега, простой синтаксис запроса строится так: <rule> <box uri="rdf:*"> <label value="rdf:http://www.test.com/Test#Prop1"/> <label value="rdf:http://www.test.com/Test#Prop2"/> <label value="rdf:http://www.test.com/Test#Prop3"/> <label value="rdf:http://www.test.com/Test#Prop4"/> </box> </rule> Если подлежащее и его свойства не являются элементами контейнера, следует использовать расширенную запись запроса. В этом случае стартовая точка та же, что и в запросе единичного факта, с использованием тега <triple>. Должно быть известно, что по крайней мере одно свойство существует. <rule>
<conditions>
<content uri="?uri"/>
<triple subject="?uri" predicate="p1" object="?v1"/>
<triple subject="?uri" predicate="p2" object="?v2"/>
<triple subject="?uri" predicate="p3" object="?v3"/>
<triple subject="?uri" predicate="p4" object="?v4"/>
</conditions>
<action>
<description uri="?data" value="?v1 ?v2 ?v3 ?v4"/>
</action>
</rule>
Здесь p снова означает полный URI предиката, наподобие http://www.test.com/Test#Prop1. На каждое свойство множества приходится один триплет <triple>. Если некоторые свойства могут не существовать (или имеют значение null), соответствующий тег <triple> можно заменить тегом <binding> и переместить в секцию <bindings>. 14.4.4. Единственные решенияЕсли запрос находит ровно одно решение, оно называется единственным решением. Обычно это бывает, если прикладной программист знает, что решение всегда существует, и единственно. Этот случай не требует специального синтаксиса, это просто следствие устройства фактов. Здесь есть, однако, некоторая хитрость. Она возникает, когда мы используем атрибут uri в теге <action>. Поскольку речь идет о теге <action>, значит, это расширенный синтаксис. Здесь возникает случай, когда запрос найдет множество решений, но построит контент лишь для одного. Это возможно только для комплексных запросов. Приведенный ниже пример иллюстрирует этот случай. Предположим, что у нас есть следующий контент RDF: <Description about="urn:example:root">
<link1>
<Description about="urn:example:child">
<link2 resource="urn:example:X"/>
<link2 resource="urn:example:Y"/>
</Description>
</link1>
</Description>
Все ресурсы этих фактов можно обнаружить таким запросом: <rule>
<conditions>
<content uri="?uri"/>
<triple subject="?uri" predicate="p1" object="?child"/>
<triple subject="?child" predicate="p2" object="?res"/>
</conditions>
<action>
<description uri="?res" value="?uri ?child ?res"/>
</action>
</rule>
В этом запросе p1 и p2 нужно заменить подходящими URI для link1 и link2. Поскольку переменная ?res принимает свое значение для каждого решения (одно X и одно Y), будут порождены две копии контента тега <action>. Если, однако, тег <description> заменить следующей строкой, будет порождена лишь одна копия: <description uri="?child" value="?uri ?child ?res"/> Здесь порождается лишь одна копия, потому что переменная ?child может быть обоснована лишь одним значением. Обычно найденное решение соответствует первому найденному в документе RDF решению, но такое поведение не гарантируется. 14.4.5. Запросы шаблонов для деревьевВсе запросы шаблонов эквивалентны навигации по дереву данных, поскольку система запросов использует стратегию "сначала вниз". Запросы шаблонов кажутся сложными, потому что (а) зачастую они рекурсивны, (б) требуется расширенный синтаксис. Сложный синтаксис маскирует тот факт, что на самом деле они очень просты. Листинг 14.16 иллюстрирует это положение. <tree flex="1" datasources="test.rdf"
ref="http://www.example.com/test.rdf">
<treecols>
<treecol id="colA" primary="true"/>
</treecols>
<template>
<rule>
<conditions>
<content uri="?uri"/>
<member container="?uri" child="?item"/>
</conditions>
<action>
<treechildren>
<treeitem uri="?item">
<treerow>
<treecell label="?item"/>
</treerow>
</treeitem>
</treechildren>
</action>
</rule>
</template>
</tree>
Листинг
14.16.
Простой запрос для дерева с расширенным синтаксисом.В листинге 14.16 приведена прямолинейная минимальная комбинация шаблона и дерева. Темным выделена разметка шаблона, светлым - разметка дерева. Несмотря на то, что конструируется общий случай, разметка собственно шаблона очень проста. Секция <rule> есть не что иное, как запрос единичного факта. Результат запроса используется ровно в одном месте. Код кажется сложным, потому что перегруженная разметка дерева смешивается с перегруженной разметкой шаблона. Если тег <tree> заменить на <box> а порождаемый контент минимизировать до тега <description>, шаблон сведется к листингу 14.17. <box datasources="test.rdf" ref="http://www.example.com/test.rdf">
<template>
<rule>
<conditions>
<content uri="?uri"/>
<member container="?uri" child="?item"/>
</conditions>
<action>
<description uri="?item" value="?item"/>
</action>
</rule>
</template>
</box>
Листинг
14.17.
Простой запрос для дерева с расширенным синтаксисом.Здесь видно, что он несложен. Эту запись можно упростить и дальше, если RDF контент организован стандартно. Если запрос рекурсивен, это упрощение окажется немного сложнее, чем может показаться на первый взгляд. Стандартная организация требует двух фактов, чтобы запрос с простым синтаксисом извлек единственное значение RDF свойства. Эти два факта имеют в качестве подлежащих идентификатор контейнера и тег member контейнера. Оба факта должны повторяться вниз по дереву, поскольку каждый шаг запроса требует обоих фактов. Это значит, что дерево, исследуемое запросом с простым синтаксисом, должно быть вдвое больше, нежели дерево, запрашиваемое более экономичным расширенным. В листинге 14.17 требуется только один факт на каждый шаг вниз по дереву. 14.4.6. Объединения запросовЕсть несколько способов получить решения объединений двух или более запросов. Атрибут datasources может указывать на несколько RDF файлов или иных источников данных, так что результат запроса будет объединением нескольких множеств фактов. Атрибут containment может добавить к запросу несколько разных предикатов container. Можно использовать несколько тегов <rule>, чтобы найти более одного решения на данном множестве фактов. Можно использовать несколько тегов <binding>, чтобы получить несколько поддеревьев данного запроса. 14.4.7. Некорректные запросыСледующий запрос не будет обработан: <rule> <conditions> <content uri="?uri"/> <triple subject="?uri" predicate="a" object="?v1"/> <triple subject="?v1" predicate="b" object="?v2"/> <triple subject="?v2" predicate="c" object="?v3"/> <triple subject="?v4" predicate="d" object="?v3"/> </conditions> </rule> В данном запросе последний тег <triple> не использует переменную ?v3 как подлежащее, а пытается двигаться по дереву в обратную сторону. Это уменьшает глубину проникновения в дерево на шаг, вместо того чтобы двигаться вглубь. Такое поведение запроса не реализовано, все условия <conditions> должны продвигать запрос в одну сторону. 14.5. Жизненный цикл шаблонаРассмотрим те шаги, которые последовательно проходит запрос шаблона. Первая часть процесса - начальное порождение контента XUL.
Вторая часть процесса касается взаимодействия пользователя и шаблона после завершения первоначального порождения контента.
14.6. СкриптингРассмотрим, как улучшать шаблоны из скриптов и управлять ими, и как использовать продвинутые свойства деревьев, обсуждавшиеся в главе 13, "Списки и деревья". глава 16, "Объекты XPCOM", содержит подробное описание RDF и объектов источников данных, дополняющих систему шаблонов. 14.6.1. Советы по созданию динамических шаблоновШаблоны на чистом XUL относительно просты, поскольку неизменны и порождают контент лишь однажды. Шаблоны с использованием XUL, JavaScript, AOM и XPCOM - это достойная задачка, потому что полная функциональность в этом случае скорее исключение, чем правило. Вот некоторая трансцендентная мудрость о динамических шаблонах:
14.6.2. AOM и XPCOM объекты шаблоновСистема шаблонов добавляет свойства JavaScript к объектам, представляющим теги шаблона. Свойства добавляются и к тегам, определяющим шаблон, и к порождаемым тегам. Такие свойства добавляются к стандартным свойствам тегов шаблона. Эти свойства указаны в Таблице 14.1.
В этой таблице, "+" означает, что свойство приобретает некоторое полезное значение; "-" значит, что свойство приобретает значение null; "Пустая строка" означает, что свойство содержит строку длины нуль. Свойство database - это объект, содержащий ссылки на источники данных, используемые шаблоном. Он реализует интерфейс nsICompositeDataSource XPCOM. Он существует даже если единственный источник данных rdf:null. Для шаблонов, получающих данные из chrome, он содержит источник данных rdf:local-store. Свойство builder - это объект, управляющий запросом и процессом порождения контента шаблона. Его можно рассматривать как высокоспециализированный (и очень ограниченный) инструмент верстки и рендеринга шаблона. Он реализует интерфейс nsIXULTemplateBuilder. Он используется лишь для шаблонов на основе тегов <listbox> и <tree>. Свойство resource - это объект, содержащий URI скомпилированного из всех источников RDF. Этот URI может быть подлежащим, предикатом или дополнением. Если тег - <template>, он содержит id шаблона, как не-URI ресурс. Если порожденный тег шаблона содержит атрибут uri, он содержит значение указанной расширенной переменной шаблона. Объект реализует интерфейс nsIRDFResource. Свойство datasources содержит значение XUL атрибута datasources. Свойство ref содержит значение XUL атрибута ref. Объект database имеет методы AddDataSource(), RemoveDataSource(), и GetDataSources(), используемые для управления источниками данных шаблона. Объект builder имеет метод rebuild(), используемый для полного пересчета и обновления содержания шаблона. Объект resource и атрибуты datasources и ref существуют лишь для удобства. Ни один из этих объектов не может быть замещен прикладным программистом. В дополнение к данным объектам AOM, существуют объекты-наблюдатели, объекты-снимки и объекты-делегаты конструкторов шаблонов. Они рассматриваются ниже. 14.6.3. Конструкторы шаблоновКонструкторы шаблонов - это конструкторы, то есть код внутри платформы Mozilla, порождающий контент дерева. Конструкторы не могут быть реализованы прикладным программистом, но могут модифицироваться. Простейшее использование конструктора - пересчет и обновление дерева в шаблоне. Требуется лишь одна строка кода: treeElement.builder.rebuild() Здесь нет опций. Эта техника работает только для шаблонов, построенных на тегах <tree> или <listbox>. rebuild() не работает на шаблонах, построенных на иных тегах. Во время перестройки дерева состояния open и closed всех поддеревьев сохраняются, если указано ленивое построение дерева. Чтобы этого не случилось, используйте атрибут statedatasource тега <tree>, и затем удалите источник данных перед перестройкой. Чтобы его удалить, удалите источник данных из свойства databases, затем удалите атрибут tree, используя операцию DOM, после чего вызовите метод rebuild(). Вспомним, что в Mozilla используется два конструктора; конструктор контента XUL и конструктор шаблонов. Мы здесь обсуждаем последний. Конструктор шаблона основан на XPCOM-компоненте и интерфейсе: @mozilla.org/xul/xul-template-builder;1 nsIXULTemplateBuilder Данный интерфейс содержит метод rebuild(). Данный конструктор не может быть модифицирован или замещен прикладным программистом. XUL конструктор имеет частный случай для деревьев: @mozilla.org/xul/xul-tree-builder;1 nsIXULTreeBuilder Этот конструктор также не может быть замещен прикладным программистом. Но он может быть улучшен. С помощью интерфейса nsITreeBuilderObserver можно зарегистрировать новый объект. Хотя этот интерфейс и напоминает объект-наблюдатель, он также очень похож и на объект-делегат. Чем его считать - дело вкуса. Интерфейс nsITreeBuilderObserver - подмножество интерфейса nsITreeView, применяемого для создания пользовательских снимков дерева. Его можно использовать для улучшения способов взаимодействия пользователя и дерева, такого как кликанье мышкой по колонкам и перетаскивание мышкой контента. В приложениях Mozilla можно найти два примера применения этого интерфейса: одно в менеджере закладок и одно в почтовом клиенте. Оба примера реализуют drag-and-drop на соответствующих деревьях и их код JavaScript можно рассматривать как хороший пример реализации. Эти интерфейсы применяются для реализации drag-and-drop из-за того способа, которым деревья хранят свой контент, и который отличается от способа, используемого остальными тегами XUL (см. лекцию 13, "Списки и Деревья") Стандартная техника drag-and-drop описывается в главе 6, "События", она не может быть использована для деревьев. Фактически вообще не существует (простого) способа реализовать drag-and-drop для деревьев не на основе шаблонов. Если используется объект с интерфейсом nsITreeBuilderObserver, его нужно реализовать как наблюдатель DOM-объекта дерева с помощью метода addObserver() интерфейса nsITreeView. Все конструкторы Mozilla также поддерживают интерфейс nsIRDFObserver, а это означает, что все дерево целиком может действовать как наблюдатель. Этот интерфейс может быть добавлен объекту источника данных (интерфейс nsIRDFDataSource), и он будет опрашиваться каждый раз, когда появляются новые факты, значимые для запроса шаблона. 14.6.4. СнимкиЕсли шаблон основан на дереве, то также доступны свойства снимков. В главе 13, "Списки и Деревья", объяснялось, что снимки - это автоматически создаваемые объекты, используемые конструктором дерева или списка для генерации актуального в каждый момент контента. Созданный программистом объект-снимок полностью заменяет контент, который будет показан шаблоном как часть данных из файла RDF. Если источник данных для шаблона <tree> - rdf:null, то созданный программистом снимок делает всю работу по наполнению дерева данными. Простейший способ это реализовать - использовать тег <tree> с нормальной секцией <treecols>, плюс одна из трех следующих опций для остающегося контента: <children/> <template> <treechildren/> </template> <template> ... normal set of template rules ... </template> Подобное дерево сначала построит свой обычный контент, затем, когда снимок изменится и дерево будет перестроено, начинает действовать снимок, который определяет дальнейший контент. Если использован атрибут-флаг "dont-build-content", обычный контент вообще не будет построен и показан. 14.6.5. Объекты-делегатыОбъекты-делегаты - это очень обобщенный термин в объектно-ориентированном программировании, и множество структур имеют делегато-подобные свойства. В платформе Mozilla объекты-делегаты - это объекты, связывающие URIs фактов RDF с внешними системами, так что каждый URI имеет ассоциированную с ним внешнюю нагрузку. Это могут быть жизненно важные данные разного сорта. Объекты-делегаты, например, могут связывать факты RDF об электронной почте с внешними источниками, хранящимися на удаленных серверах, например, MTP, IMAP или LDAP. В этой главе нет места и времени для подробного обсуждения объектов-делегатов. Как стартовую точку изучения можно рекомендовать интерфейсы nsIRDFResource и nsIRDFDelegateFactory, а также следующие компоненты XPCOM: @mozilla.org/rdf/delegate-factory;1?key= 14.6.6. Часто встречающиеся задачи программированияНиже приведен краткий список стратегий решения часто встречающихся задач. Программируемые RDF объекты подробно рассматриваются в главе 16, "Объекты XPCOM". В частности, там рассматриваются приемы работы с источниками данных rdf:null и другими внутренними источниками данных. Чтобы сменить источник данных, используйте databases.getDataSources(), шаг за шагом по доступному списку источников, чтобы найти нужный, задействуйте databases.removeDataSource() с этим источником в качестве аргумента, и затем перестройте шаблон. Либо удалите этот источник и перестройте шаблон. Чтобы сменить корневой URI запроса шаблона, используйте setAttribute("ref",newURI) для базового тега. Шаблон будет перестроен автоматически. Установка свойства ref даст тот же эффект. Чтобы сменить правила запроса, используйте операции DOM или innerHTML чтобы изменить теги прямо в XUL, и затем перестройте шаблон с помощью rebuild(). Лучшее решение - создать все возможные правила и затем запретить ненужные. Это можно сделать, поместив перед правилами, которые нужно запретить, правило "catch-all". Правило "catch-all" - это такое правило, которое находит решения всех доступных ему данных, так что до оставшихся правил дело не доходит. Чтобы изменить факты в источнике данных, выберите нужный источник с помощью databases.GetDataSources(). Используйте методы Assert() или Change() интерфейса nsIRDFDataSource. В некоторых случаях шаблон будет перестроен автоматически. Чтобы перестроить его наверняка, используйте rebuild(). Чтобы изменить результаты запроса, следует немного отступить назад. Вы не можете изменить результаты, найденные запросом, потому что они порождаются им. Необходимо изменить запрос или исходные RDF данные так, чтобы получаемые решения изменились. Чтобы изменить факт в источнике фактов, используется компонент @mozilla.org/rdf/rdf-service;1 и другие RDF компоненты. С их помощью можно конструировать факты и части фактов, и затем использовать метод Assert() чтобы установить значение факта true. Затем перестройте шаблон. Чтобы изменить порожденный контент, применяются обычные DOM операции. (Эти изменения будут потеряны, если шаблон перестроить). Чтобы сделать изменения постоянными, измените часть правила <content>, а не порожденный контент, и перестройте шаблон. 14.7. Стилевые опцииСистема шаблонов не имеет специальных стилевых усовершенствований, но и с существующими стилями можно использовать несколько удачных приемов. Контент шаблона можно оформлять стилями, и в атрибутах style и class использовать переменные шаблона. Таким образом стилевая информация может предоставляться самими RDF данными, обрабатываемыми шаблоном. Это, однако, порождает архитектурную проблему, поскольку в таком случае данные и оформление смешиваются в одном и том же множестве RDF фактов. Если этот прием должен использоваться не как единичный случай, лучше иметь один набор фактов для данных и отличный от него - для стилевого оформления. Стили можно применять, используя теги <rule> как селекторы, управляемые данными. Два правила могут порождать практически идентичный контент, но запросы при этом могут отличаться. Практически идентичный контент может, соответственно, иметь разное стилевое оформление. Наконец, стили можно применить к порожденному контенту, используя операции JavaScript DOM. Если шаблон будет перестроен, это стилевое оформление может потеряться. 14.8. Практика: оживляем данные для NotetakerДанный раздел "Практика" описывает использование шаблонов нашего приложения, работающих с реальными данными. В этом разделе мы заменим часть нашего кода шаблоном и затем протестируем приложение на реальных данных. Для начала, у нас есть модель RDF данных из главе 12, "Оверлеи и Chrome". Позже мы поместим этот файл в профиль пользователя, где он и должен быть. А пока что мы поместим его в chrome вместе со всеми файлами нашего приложения. Он будет тут: chrome://notetaker/contents/notetaker.rdf Шаблоны нам понадобятся три раза:
Последний пункт требует специальной техники; содержание дерева, грубо говоря, должно уточнять содержание списка, а это требует координирования их работы. Данные также появляются в HTML-записи на текущей web-странице. HTML не поддерживает шаблонов, так что мы должны извлечь необходимые нам данные из RDF, используя отличный от шаблона механизм. Он описывается в главе 16, "Объекты XPCOM". 14.8.1. Создаем тестовые данныеДля того чтобы построить шаблон, нам нужны некоторые данные. Создадим RDF документ с двумя записями и относящейся к ним информацией. Первая запись - о web-странице test1.html, имеющая четыре ключевых слова. Вторая - о test2.html, с двумя ключевыми словами. В листинге 14.18 приведены данные для этих двух записей и связи ключевых слов. <?xml version="1.0"?>
<RDF xmlns="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmnls:NT="http://www.mozilla.org/notetaker-rdf#">
<Description about="urn:notetaker:root">
<NT:notes>
<Seq about="urn:notetaker:notes">
<li resource="http://saturn/test1.html"/>
<li resource="http://saturn/test2.html"/>
</Seq>
</NT:notes>
<NT:keywords>
<Seq about="urn:notetaker:keywords">
<li resource="urn:notetaker:keyword:checkpointed"/>
<li resource="urn:notetaker:keyword:reviewed"/>
<li resource="urn:notetaker:keyword:fun"/>
<li resource="urn:notetaker:keyword:visual"/>
<li resource="urn:notetaker:keyword:cool"/>
<li resource="urn:notetaker:keyword:test"/>
<li resource="urn:notetaker:keyword:breakdown"/>
<li resource="urn:notetaker:keyword:first draft"/>
<li resource="urn:notetaker:keyword:final"/>
<li resource="urn:notetaker:keyword:guru"/>
<li resource="urn:notetaker:keyword:rubbish"/>
</Seq>
</NT:keywords>
</Description>
<!-- details for each note -->
<Description about="http://saturn/test1.html">
<NT:summary>My Summary</NT:summary>
<NT:details>My Details</NT:details>
<NT:top>100</NT:top>
<NT:left>90</NT:left>
<NT:width>80</NT:width>
<NT:height>70</NT:height>
<NT:keyword resource="urn:notetaker:keyword:test"/>
<NT:keyword resource="urn:notetaker:keyword:cool"/>
</Description>
<Description about="http://saturn/test2.html">
<NT:summary>Good place to list</NT:summary>
<NT:details>Last time I had a website here, my page also appeared on Yahoo </NT:details>
<NT:top>100</NT:top>
<NT:left>300</NT:left>
<NT:width>100</NT:width>
<NT:height>200<NT:height>
<NT:keyword resource="urn:notetaker:keyword:checkpointed"/>
<NT:keyword resource="urn:notetaker:keyword:reviewed"/>
<NT:keyword resource="urn:notetaker:keyword:fun"/>
<NT:keyword resource="urn:notetaker:keyword:visual"/>
</Description>
<!-- values for each keyword -->
<Description about="urn:notetaker:keyword:checkpointed" NT:label="checkpointed"/>
<Description about="urn:notetaker:keyword:reviewed" NT:label="reviewed"/ >
<Description about="urn:notetaker:keyword:fun" NT:label="fun"/>
<Description about="urn:notetaker:keyword:visual" NT:label="visual"/>
<Description about="urn:notetaker:keyword:breakdown" NT:label="breakdown"/>
<Description about="urn:notetaker:keyword:first draft" NT:label="first draft"/>
<Description about="urn:notetaker:keyword:final" NT:label="final"/>
<Description about="urn:notetaker:keyword:guru" NT:label="guru"/>
<Description about="urn:notetaker:keyword:rubbish" NT:label="rubbish"/>
<Description about="urn:notetaker:keyword:test" NT:label="test"/>
<Description about="urn:notetaker:keyword:cool" NT:label="cool"/>
<!--sufficient related keyword pairings -->
<Description about="urn:notetaker:keyword:checkpointed">
<NT:related resource="urn:notetaker:keyword:breakdown"/>
<NT:related resource="urn:notetaker:keyword:first draft"/>
<NT:related resource="urn:notetaker:keyword:final"/>
</Description>
<Description about="urn:notetaker:keyword:reviewed">
<NT:related resource="urn:notetaker:keyword:guru"/>
<NT:related resource="urn:notetaker:keyword:rubbish"/>
</Description>
<Description about="urn:notetaker:keyword:fun">
<NT:related resource="urn:notetaker:keyword:cool"/>
</Description>
<!-- single example of a cycle -->
<Description about="urn:notetaker:keyword:cool">
<NT:related resource="urn:notetaker:keyword:test"/>
</Description>
</Description>
</RDF>
Листинг
14.18.
Тестовые данные для XUL-шаблона NoteTaker.К сочетанию RDF документа и шаблона нужно относиться куда внимательнее, чем к вручную размечаемому дереву. Если хоть что-нибудь будет сделано некорректно, шаблон ничего не построит, без каких-либо указаний на причину. Начните с тестирования наших данных по советам из раздела "Отладка". Если у вас нет текстового редактора с автоматической подсветкой и проверкой XML синтаксиса, поступите следующим образом: загрузите RDF документ в браузер, чтобы найти синтаксические ошибки в XML. Затем измените расширение файла на .xml и вновь откройте в браузере, чтобы обнаружить проблемы, связанные с порядком тегов. Наконец, просмотрите файл визуально, вспомните рекомендации о формате из главе 11, "RDF". Если все выглядит как надо, у нас есть некоторая, но совсем не полная, уверенность, что с нашими данными все в порядке. 14.8.2. Простые шаблоны для элементов формыСначала мы напишем шаблоны для панели инструментов NoteTaker. Для панели инструментов потребуется два значения, по одному для каждого поля ввода текста, и набор из нуля или более элементов выпадающего меню. Нужно использовать два шаблона, один для полей ввода и другой для выпадающего меню. Выпадающее меню - самое простое. Из файла notetaker.rdf видно, что для конкретных ключевых слов нам нужно свойство label. Ключевые слова собираются вместе в RDF контейнере urn:notetaker:keywords, т.е. теге <Seq>. Это устройство соответствует стандартной организации фактов, так что можно использовать простой синтаксис запроса и, следовательно, создание шаблона не должно вызывать затруднений. Сначала протестируем шаблон на простом документе, не будем добавлять его на панель инструментов сразу. Таким образом мы избежим сложностей с контентом выпадающего меню. Поскольку шаблоны и RDF дают нам очень мало диагностической информации, будем двигаться шаг за шагом. В листинге 14.19 приведен простой документ без какого-либо шаблона. <?xml version="1.0"?>
<?xml-stylesheet href="chrome://global/skin/" type="text/css"?>
<!DOCTYPE window>
<window xmlns="http://www.mozilla.org/keymaster/
gatekeeper/there.is.only.xul">
<vbox>
<description value="Static content"/>
<hbox>
<description value="Repeated content"/>
</hbox>
</vbox>
</window>
Листинг
14.19.
Простой XUL документ, подходящий как основа для тестирования шаблона.Для шаблона нам необходимы следующие моменты: Файл RDF: datasources="notetaker.rdf" Стартовая точка запроса: ref="urn:notetaker:keywords" Простая переменная требует повторяющегося контента: uri="rdf:*" В качестве переменной запроса с простым синтаксисом используем: rdf:http://www.mozilla.org/notetaker-rdf#label Объединяя эту информацию с кодом листинга 14.18, получим листинг 14.20. <?xml version="1.0"?>
<?xml-stylesheet href="chrome://global/skin/"
type="text/css"?>
<!DOCTYPE window>
<window xmlns="http://www.mozilla.org/keymaster/
gatekeeper/there.is.only.xul">
<vbox datasources="notetaker.rdf" ref="urn:notetaker:keywords">
<description value="Static content"/>
<template>
<hbox uri="rdf:*">
<description value="Repeated content"/>
<description value="rdf:http://www.mozilla.org/
notetaker-rdf#label"/>
</hbox>
</template>
</vbox>
</window>
Листинг
14.20.
Простой документ XUL с шаблоном запроса для выпадающего меню.Контент "Static content" находится вне тега <template>, так что мы увидим его в любом случае. Контент "Repeated content" появится один раз для каждого решения, найденного запросом. Третий тег description даст значение единственной переменной, обоснованной запросом. Результаты работы шаблона показаны на рисунке 14.6. 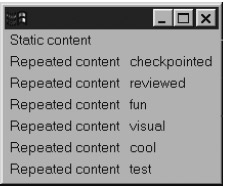 Рис. 14.6. Контент, генерируемый шаблоном в тестовой форме. Теперь у нас есть работающий шаблон. Чтобы этого добиться, мы игнорировали некоторые мелочи; с системой шаблонов, однако, все в порядке, за исключением, может быть, нехватки отладочных инструментов. Теперь мы можем модифицировать шаблон, встроив его в панель инструментов. В листинге 14.21 показано выпадающее меню до и после присоединения шаблона. <?xml version="1.0"?>
<menulist editable="true">
<menupopup>
<!-- static menu items removed -->
</menupopup>
</menulist>
<menulist id="notetaker-toolbar.keywords" editable="true">
<menupopup datasources="notetaker.rdf" ref="urn:notetaker:keywords">
<template>
<menuitem uri="rdf:*" label="rdf:
http://www.mozilla.org/notetaker-rdf#label"/>
</template>
</menupopup>
</menulist>
Листинг
14.21.
Выпадающее меню со встроенным шаблоном для панели инструментов NoteTaker.Результаты этих изменений видны на рисунке 14.7. Если запрос не обнаружит ключевых слов, в меню не будет ни одного элемента, и на панели инструментов это будет выглядеть плохо. Чтобы исправить положение, мы добавили временный тег <menuitem> перед тегом <template>. Другой способ - сделать наверняка, чтобы в файле notetaker.rdf содержалось как минимум одно ключевое слово. Мы так поступим позже. Второй шаблон на панели инструментов должен найти единственное решение для тега <textbox>. Чтобы представить себе, каким может быть этот запрос, снова посмотрим на файл notetaker.rdf. URL искомой записи является членом именованного RDF контейнера (urn:notetaker:notes), и имеет свойство summary. Таким образом стандартная организация фактов, требуемая для простого синтаксиса запроса, соблюдена. Наверное, мы можем использовать простой синтаксис. Но на деле мы простой синтаксис использовать не можем, потому что мы привередливы - мы хотим выбирать, какие члены последовательности будут получены. Нам нужен единственный член, являющийся записью именно о текущем URL. Так что придется использовать расширенный синтаксис.  Рис. 14.7. Выпадающее меню панели инструментов NoteTaker, порожденное шаблоном. В расширенном синтаксисе мы не обязаны начинать запрос с вершины последовательности, так что мы можем быть более изобретательны. Мы можем начать его прямо с URL текущей записи. Если мы так сделаем, примером запроса может быть: <- http://saturn/test1.html, http://www.mozilla.org/ notetakerrdf#summary, ?summary -> Используя совет, данный в настоящей главе, в разделе "Часто встречающиеся образцы запросов", создадим шаблон следующим образом: <box datasources="notetaker.rdf" ref="http://saturn/test1.html">
<template>
<rule>
<conditions>
<content uri="?uri"/>
<triple subject="?uri"
predicate="http://www.mozilla.org/notetaker-rdf#summary"
object="?summary"/>
</conditions>
<action>
<textbox id="notetaker-toolbar.summary" uri="?summary"
value="?summary"/>
</action>
</rule>
</template>
</box>
Листинг
14.22.
Второй шаблон на панели инструментов NoteTaker.Этот код заменит единственный тег <textbox/>, присутствующий на панели инструментов. Мы заключили textbox в невидимый тег <box>, чтобы привязать к нему шаблон. Этот шаблон в качестве исходной точки запроса имеет фиксированный URL. В недалеком будущем мы сделаем данное значение динамическим, используя скрипт и метод setAttribute(). На этом изменения в XUL панели инструментов NoteTaker заканчиваются. Обратимся к шаблонам диалогового окна Edit. Оба тега этого окна, и <listbox>, и <tree>, требуют использования шаблонов. 14.8.3. Шаблон с расширенным синтаксисом для <listbox>Шаблон для тега <listbox> - более простая задача, так что начнем с нее. Снова заглянем в файл notetaker.rdf, чтобы получить представление о том, как должен выглядеть необходимый запрос. Мы видим, что запись является частью последовательности записей и имеет свойство keyword, то есть имеет место стандартная организация фактов. Проблема состоит в том, что URL записи - известная, фиксированная величина, а не переменная для каждой записи в последовательности. Эта ситуация подобна ситуации с шаблоном для <textbox> на панели инструментов, так что используем расширенную запись запроса. Вторая причина использовать расширенный синтаксис - необходимость добыть текстовую строку ключевых слов. Эти строки - свойства каждого ключевого слова, а не свойства всей записи. Мы можем легко их получить, расширяя запрос глубже по множеству фактов - один добавочный тег <triple> свяжет найденные ключевые слова записи с их текстовыми значениями. Требуемый шаблон выглядит как листинг 14.23. <listbox id="dialog.keywords" rows="3" datasources="notetaker.rdf"
ref="http://saturn/test1.html">
<template>
<rule>
<conditions>
<content uri="?uri"/>
<triple subject="?uri"
predicate="http://www.mozilla.org/
notetaker-rdf#keyword"
object="?keyword"/>
<triple subject="?keyword"
predicate="http://www.mozilla.org/
notetaker-rdf#label"
object="?text"/>
</conditions>
<action>
<listitem uri="?keyword" label="?text"/>
</action>
</rule>
</template>
</listbox>
Листинг
14.23.
Шаблон списка для панели инструментов NoteTaker.За исключением добавочного тега <triple>, этот тот же код, что и для <textbox>. Мы могли бы использовать шаблон и для панели Edit в диалоговом окне Edit. Но у нас есть достаточно оснований так не поступать, так что оставим эту панель в прежнем состоянии. Одно из этих оснований - то, что мы не знаем, какая запись больше всего подойдет, когда загружается данный URL. 14.8.4. Шаблон дерева с расширенным синтаксисом.Последний шаблон, который мы сконструируем, это шаблон дерева для связанных ключевых слов. Снова рассмотрим файл notetaker.rdf. Нам нужно свойство label для ключевого слова. Нам также требуются связанные свойства, чтобы найти ключевые слова, связанные с найденным. Наконец, нам нужно, чтобы началом (level 0) дерева были ключевые слова для записи текущего URL. Мы используем этот URL как вершину запроса, но высветим лишь дочерние решения данного URL, но не сам URL. Для полного рекурсивного запроса нам необходимы такие факты: <- current-page-url, keyword, ?keyword -> // level 0 <- ?keyword, label, ?text -> <- ?keyword, related, ?keyword2 -> <- ?keyword2, label, ?text2 -> // level 1 <- ?keyword2, related, ?keyword3 -> // level 2 <- ?keyword3, label, ?text3 -> ... и так далее ... Такое множество фактов не отвечает стандартной организации, так что требуется расширенный синтаксис. Это множество фактов является рекурсивным запросом, так что нам действительно нужен именно тег <tree>. Каким будет запрос? Зададим вопрос более точно: что необходимо получить запросу, чтобы продвинуться на один уровень глубже по дереву решений? На каждом уровне есть два факта, поэтому кажется, что рекурсивный запрос должен охватывать оба этих факта (two-fact query). Но если мы взглянем на структуру файла notetaker.rdf, станет ясно, что для каждого уровня запроса необходим лишь один факт, поскольку ключевые слова заключены в единственном предикате/свойстве. Если нарисовать запрос как RDF диаграмму, мы быстро увидим, что ответом является именно один факт на шаг запроса. Диаграмма приведена на рисунке 14.8.  Рис. 14.8. Диаграмма RDF для рекурсивного запроса шаблона. Ясно, что рекурсивность требует одного шага вглубь дерева вдоль вертикальной стрелочки. Так что запрос является запросом единственного факта. А другая стрелочка раскрывает информацию, требуемую на каждом уровне, но не участвующую в рекурсии. Сначала рассмотрим факты, порождающие рекурсию, и расположенные вдоль вертикальных стрелок. Проблема в том, что иногда они содержат ключевые слова, а иногда - связанные ключевые слова. Другими словами, для рекурсивного запроса есть альтернатива: <- current-page-url, keyword, ?keyword -> <- current-keyword-urn, related, ?keyword -> Каким-то образом запрос шаблона должен учесть оба случая. Один способ - использовать отдельные правила <rule> для каждой возможности. В нашем случае, однако, хорошее решение - атрибут шаблона containment. К счастью, при любом URI есть либо факт со свойством keyword, либо со свойством related, но не с обоими сразу. А это значит, что мы можем использовать несколько предикатов container вместе. Мы перечислим и предикат related, и предикат keyword в значении этого атрибута. Чтобы понять, почему мы можем использовать containment, рассмотрим работу запроса. Когда запрос открывает верхний уровень дерева, предикат keyword найдет решения, а предикат related - нет, потому что так в RDF файле устроены факты. Когда запрос обнаруживает решения на следующем уровне, предикат related найдет решения, а предикат keyword - нет. Это в точности то, что нам нужно. Полученный в результате шаблон приведен в листинге 14.24. <tree id="dialog.related" flex="1"
datasources="notetaker.rdf"
ref="http://saturn/test2.html"
containment="http://www.mozilla.org/notetaker-rdf#related http://
www.mozilla.org/notetaker-rdf#keyword" hidecolumnpicker="true"
>
<treecols>
<treecol id="tree.all" hideheader="true"
primary="true"
flex="1"/>
</treecols>
<template>
<rule>
<conditions>
<content uri="?uri"/>
<member container="?uri"
hild="?keyword"/>
</conditions>
<action>
<treechildren>
<treeitem uri="?keyword">
<treerow>
<treecell label="?keyword"/>
</treerow>
</treeitem>
</treechildren>
</action>
</rule>
</template>
</tree>
Листинг
14.24.
Рекурсивный шаблон дерева для диалогового окна NoteTaker.Запрос содержит тег <member>, чтобы проверять соответствие атрибуту containment. Поскольку это рекурсивный запрос, мы не можем устроить проверку просто тегом <description>. Мы обязаны использовать один из тегов, явным образом поддерживающий рекурсивные запросы, в данном случае для <tree>. Теперь шаблон готов, нужно лишь добавить поиск дополнительной информации, как показано на рисунке 14.8. Это можно сделать, используя тег <binding>. Добавим следующий код сразу после тега </conditions>: <bindings> <binding subject="?keyword" predicate="http://www.mozilla.org/notetaker-rdf#label" object="?text"/> </bindings> Поскольку теги <binding> не сказываются на рекурсивном процессе, запрос мы этим не повредим, а лишь уточним им обнаруживаемую информацию. Наконец, нужно изменить тег <treecell>, чтобы вывести label, обнаруживаемый тегом <binding>, а не URN или keyword: <treecell label="?text"/> На этом создание всех шаблонов завершено. Хотя теги <listbox> и <tree> имеют контент, порожденный шаблоном, обработчики событий, созданные нами в главе 13, "Списки и деревья", продолжают нормально работать. Они обслуживают DOM структуру порожденного шаблоном контента так же легко, как и статические теги XUL. С шаблоном <tree> у нас возникает одна проблема. Наш шаблон не обнаруживает связанные ключевые слова так, как это делал экспериментальный снимок шаблона в главе 13, "Списки и деревья". Он обнаруживает лишь то, что есть в RDF файле. Мы можем улучшить ситуацию, добавляя новые комбинации keyword-keyword в файл notetaker.rdf, или мы можем как-то модифицировать шаблон, чтобы факты, обнаруживаемые запросом, проходили специальную обработку, а не высвечивались в "сыром" виде прямо из файла. Мы рассмотрим эту последнюю возможность в главе 16, "Объекты XPCOM". 14.8.5. Управление и обновление контента шаблонаНаконец, нам нужно реализовать обновление данных, построенных шаблоном. Это означает необходимость связать данные на панели инструментов, в диалоговом окне Edit и HTML-записи с RDF фактами о текущей web-странице, высвеченной в браузере. Обновлять HTML-запись - задача слишком сложная для используемой нами технологии, но все остальные обновления мы выполним легко. Вот наш план:
Чтобы этого добиться, внесем следующие небольшие изменения на панели инструментов:
Во-первых, мы должны реализовать объект note на JavaScript и его методы clear() и resolve() и свойство url. Метод clear() уничтожает все данные текущей записи, resolve() преобразует данный URL в URL существующей записи и сохраняет результат. В данной главе эти изменения будут тривиальны, но мы уточним их позже. Код нового объекта note приведен в листинге 14.25. function Note() {} // constructor
Note.prototype = {
url : null,
summary : "",
details : "",
chop_query : true,
home_page : false,
width : 100,
height : 90,
top : 80,
left : 70,
clear : function () {
this.url = null;
},
resolve : function (url){
this.url = url;
},
}
var note = new Note();
Листинг
14.25.
Базовый объект JavaScript для записи NoteTaker.Во-вторых, реализуем функцию refresh_toolbar(), обновляющую шаблоны панели инструментов. Некоторые из этих функций нам придется усовершенствовать в следующих главах. Функция приведена в листинге 14.26. function refresh_toolbar() {
var menu = window.document.getElementById
('notetaker-toolbar.keywords');
menu.firstChild.builder.rebuild();
var box = window.document.getElementById
('notetaker-toolbar.summary');
box.parentNode.setAttribute('ref', note.url);
box.parentNode.builder.rebuild();
}
Листинг
14.26.
Код функции, обновляющей шаблон на панели инструментов NoteTaker.Метод rebuild() автоматически удалит и пересоздаст контент шаблона. В случае выпадающего меню контент изменится, только если изменится исходный RDF файл. В случае <textbox> модифицируется сам шаблон, поэтому запрос каждый раз разный. Наконец, посмотрим на регулярные проверки. Они вызываются из функции content_poll(), так что поправим ее так, чтобы обновлялась не только высвеченная запись, но и панель инструментов. function content_poll() {
var doc;
try {
if ( !window.content ) throw('fail');
doc = window.content.document;
if ( !doc ) throw('fail');
if ( doc.getElementsByTagName("body").length == 0 )
throw('fail');
if ( doc.location.href == "about:blank" )
throw('fail'); }
catch (e) {
note.clear(); refresh_toolbar(); return;
}
if ( doc.visited )
return;
note.resolve(doc.location.href);
display_note();
refresh_toolbar();
doc.visited = true;
}
Листинг
14.27.
Опрос высвеченной страницы и выполнение необходимых обновлений.Если подходящего URL не существует, текущая запись и панель инструментов очищаются. В противном случае ищется новая текущая запись и обновляются панель инструментов, запись и текущая страница. Мы еще не выполнили пункты 4 и 6, потому что пока не знаем, как модифицировать RDF файлы - мы пока умеем их только читать. Ту часть команд, которая относится к обновлению шаблона, мы, однако, реализовать можем. Изменим функцию action() так, чтобы она вызывала refresh_toolbar() каждый раз, когда это необходимо. Листинг 14.28 показывает этот простой код. function action(task) {
if ( task == "notetaker-open-dialog" ) {
window.openDialog("editDialog.xul","_blank","modal=yes");
refresh_toolbar();
}
if ( task == "notetaker-display" ) {
display_note();
}
if ( task == "notetaker-save" ) {
refresh_toolbar();
}
if ( task == "notetaker-delete" ) {
refresh_toolbar();
}
}
Листинг
14.28.
Полный список команд панели инструментов NoteTaker с перестройкой шаблонов.На этом управление шаблонами завершено. Для диалогового окна нам нужно сделать то же самое для шаблонов панели Keywords. Мы выполним эту задачу в команде notetaker-load. В функции action(), обслуживающей команду, добавим вызов refresh_dialog() и реализуем refresh_dialog() как показано в листинге 14.29. function refresh_dialog() {
var listbox = window.document.getElementById('dialog.keywords');
listbox.setAttribute('ref', window.opener.note.url);
listbox.builder.rebuild();
var tree = window.document.getElementById('dialog.keywords');
tree.setAttribute('ref', window.opener.note.url);
tree.builder.rebuild();
}
Листинг
14.29.
Обновление шаблона в диалоговом окне Edit.Этот код идентичен коду обновления шаблона на панели инструментов выпадающего меню. 14.9. Отладка: советы по отладке шаблонаЕсли шаблоны созданы и используются корректно, все работает. В работе шаблонов практически нет отклонений, способных вызвать сбой. Большинство ошибок - следствие синтаксических ошибок кода. Работая на платформе Microsoft Windows, удостоверьтесь, что Mozilla полностью завершила работу и выгружена из памяти после закрытия последнего окна. Если используется неверно сформированный шаблон, процесс может застрять в памяти и повлиять на последующие пробы. Если такое случается - самый общий симптом состоит в том, что кажется, будто изменения, вносимые в код XUL или JavaScript, не дают ожидаемого эффекта. Безопаснее всего перестартовывать платформу каждый раз заново. Если вы не отключили заставку Mozilla, она - явный -знак, что платформа стартовала заново. Вторая ловушка связана с рекурсивными запросами. Работайте только с виджетами <menu> и <tree>, остальные ведут себя непредсказуемо и могут вызвать падение платформы. Комбинация RDF-документа и XUL шаблона требует впятеро большей заботы, чем создание тега <tree>, описанное в главе 13, "Списки и деревья". Если хоть мельчайшая деталь некорректна, шаблон не даст вовсе никакого результата, и не будет и намека, почему так произошло. Очень важно все делать правильно с самого начала. 14.9. Пишем шаблонСоздавая шаблон, всегда начинайте с тестовых данных во внешнем RDF файле. Mozilla имеет все необходимые инструменты для обработки RDF- источников данных, хранимых во внешних файлах. Их легко читать и человеку. Используйте технику, описанную в разделе "Отладка" главе 11, "RDF". Это даст вам уверенность, что данные загружаются именно так, как вы ожидаете. Загрузите файл прямо в браузер, чтобы увидеть синтаксические ошибки. Загрузите файл, переименовав его в .xml, чтобы увидеть ошибки, связанные с отступами. Или используйте инструменты проверки RDF, рекомендуемые W3C. Создав корректные данные, удостоверьтесь, что результат можно видеть в окне XUL. Если шаблон не рекурсивен, создайте шаблон с базовым тегом <vbox>. Выведите что-нибудь в тег <description> или <label> без лишних "красивостей" в правилах. Как только что-то осмысленное появится на экране, вы получаете по крайней мере корень запроса и часть его правильной структуры. Даже если ваша цель - сложный тег "дерево" со многими уровнями вложения, начинайте сначала с <vbox>. Если ваш источник данных - внутренний, прочитайте советы в главе 16, "Объекты XPCOM", и извлеките максимум информации из данных на тестовую страницу. Некоторыми источниками данных можно управлять прямо из шаблона, остальные требуют скриптов. Нужно хорошо изучить порождаемый контент, иначе запрос шаблона не сработает. Наконец, стройте запрос. Система запросов гибка, и может обработать некоторые вариации контента внутри тега <template>, но вносить их все же не рекомендуется. Чтобы избежать лишних хлопот, следуйте как можно ближе к порядку тегов, приведенному в данной главе. Хотя от него и можно отступать, это может привести к некорректному преобразованию шаблона и его переменных во внутреннюю форму. Тут перемена мест на результат влияет, и еще как. Если шаблон рекурсивен, вы не можете тестировать рекурсию без тегов <menu> или <tree>, но лишь первый уровень рекурсии. Чтобы тестировать дальнейшие уровни, используйте <tree>, а не <menu>. Невозможно построить рекурсивно порожденное множество меню единственным правилом <rule> - требуется, по крайней мере, два. Одно правило необходимо для элементов <menu>, другое - для элементов <menuitem>. Так что для тестирования рекурсивных запросов дерево - самый подходящий и простой механизм. Только после того, как тестовый запрос даст ожидаемый результат, начинайте работу с реальным виджетом. В случае дерева начинайте с кода, приведенного в данной главе, и обязательно следите за тем, чтобы дерево имело первичную колонку. Необходимые детали можно добавить позже. Внимательно просмотрите флаги и опции, которые можно добавить к базовому тегу, некоторые из них жизненно важны. Автоматически добавьте flags="dont-build-content" и flex="1", если только вы не знаете точно, что они не нужны. Когда ваш шаблон заработает правильно, можно добавить скрипты его динамического поведения. Раздел 14.6.1, "Советы по созданию динамических шаблонов" содержит действительно важные советы. За пределами, описанными в этом разделе, поддерживается не слишком многое. Наконец, обратите внимание на раздел "Источники данных" главе 16, "Объекты XPCOM". Если ваш источник данных RDF - внутренний, его нужно аккуратно наполнять данными перед использованием. Большинство внутренних источников не имеют опубликованного внутреннего представления RDF фактов. В качестве последнего рубежа посмотрите на то, как они используются в уже работающих приложениях Mozilla. 14.10. ИтогиСистема шаблонов Mozilla обрабатывает RDF и предоставляет средства оформления полученных результатов запроса. Эти результаты могут изменяться динамически, чтобы отслеживать изменения лежащих в основе данных. Система шаблонов - вершина языка XUL. Она интегрирована с системой верстки приложения. Она предназначена для конструирования динамических GUI-интерфейсов или просто для предоставления изменяющихся данных в фиксированном окне приложения. Шаблоны не статичны, они легко могут изменяться, если изменяются исходные условия. Система сложна для изучения. Она использует новаторские концепции и массу подводных камней, и выдает слишком мало отладочной информации в процессе создания шаблона. Разнородные источники данных требуют каждый индивидуального подхода и усилий по их изучению, что также не упрощает работу. Несмотря на проблемы первой версии платформы, шаблоны являются очень мощным инструментом. RDF файл, сохраненный по известному URL где угодно в мире, может быть загружен и обработан с помощью краткого и выразительного множества XUL тегов. Эта простота - залог дальнейшего развития способностей платформы Mozilla в обработке и представлении данных. По-видимому, существующая система шаблонов - лишь первый шаг в этом направлении. Для порождения и управления новым контентом XUL документа могут быть использованы JavaScript и DOM. RDF и система шаблонов ведут к одной и одной и той же цели - наглядному представлению и управлению данными, хотя и разными путями. Есть и третий путь - XBL, это тема нашей следующей главе. |
||||||||||||||||||||||||||||||