| Разработка приложений с помощью Mozilla / автор: Н.Макфарлейн | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
16. Глава:
Объекты XPCOM
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
В состав платформы Mozilla входит объектная библиотека, содержащая более тысячи объектов, которые могут использоваться разработчиком при создании собственных приложений. Многие из этих объектов не имеют никакого отношения к графическому интерфейсу пользователя. Задача этой главы - рассказать, для каких целей разработчик может использовать различные группы объектов платформы. Тысяча примеров скриптов - слишком много для одной главы. Здесь мы можем лишь познакомиться с основными типами объектов, а также предложить читателю некоторые рекомендации и ориентиры для дальнейшего освоения библиотеки. Если вы займетесь разработкой на платформе Mozilla, в дополнение к материалу этой главы вам придется читать определения интерфейсов объектов на языке XPIDL. В главе приведены многочисленные фрагменты скриптов, демонстрирующие использование этих интерфейсов. Все примеры написаны на JavaScript. Объектная библиотека Mozilla состоит, главным образом, из компонентов XPCOM. Без этих компонентов возможности разработчика приложений были бы ограничены работой с документами XML, будь то HTML или XUL. Механизмы взаимодействия приложений с внешним миром сводились бы к таким технологиям, как URL, HTTP, SOAP и WDSL. Добавление компонентов XPCOM радикально меняет ситуацию. Компоненты добавляют поддержку работы с сетью, базами данных, файлами и процессами - все, что нужно для разработки полноценных приложений с богатой функциональностью. Компоненты XPCOM доступны на всех платформах, где работает Mozilla, и код, использующий их, полностью переносим, за редким исключением. Набор компонентов Mozilla сравним с любой современной объектно- ориентированной библиотекой или стандартной библиотекой языка третьего поколения. Подобно языкам C++ и Java, платформа Mozilla использует концепцию потоков ввода-вывода. Подобно языкам С, Perl и множеству прочих, Mozilla предлагает средства для работы с файлами. В целом, объекты Mozilla почти эквивалентны современным универсальным библиотекам классов. Это "почти" связано с тем, что Mozilla пока достигла лишь версий 1.x. С относительной новизной платформы связана некоторая ограниченность круга объектов, доступных разработчику. Вместо того чтобы предложить широкий диапазон объектов низкого уровня, Mozilla содержит некоторое количество объектов низкого и среднего уровней, а также ряд объектов очень высокого уровня, рассчитанных на приложения определенного типа. Поскольку первоначально платформа была разработана как средство создания браузера и других приложений для работы с Internet, специализированные объекты, созданные для решения этой задачи, присутствуют в библиотеке на всех уровнях абстракции. В отличие, например, от библиотеки классов Java, набор компонентов Mozilla не был с самого начала спроектирован, как мощная универсальная библиотека. Тем не менее, тысяча компонентов - весьма мощный ресурс, который по объему приближается к обширной библиотеке модулей Perl. Еще одна нетипичная особенность библиотеки Mozilla состоит в том, что многие ее объекты рассчитаны на работу с сетью. Первоначальные приложения Mozilla - навигатор, почтовый клиент и Chatzilla - представляют собой сетевые клиенты, взаимодействующие с серверами. Это наложило на библиотеку определенный отпечаток. Внутренняя реализация некоторых простых действий, например открытия файла, может быть весьма сложной, поскольку файл может оказаться где угодно в Internet. Эта сложность повлияла и на интерфейсы, доступные разработчикам. С другой стороны, возможности некоторых интерфейсов могут быть ограничены системой защиты Mozilla. Однако даже если разрабатываемое приложение не является браузером, почтовым клиентом или системой работы с документами XML, Mozilla способна предложить множество полезных инструментов, хотя некоторые специализированные объекты высокого уровня окажутся при этом бесполезными. С другой стороны, если приложению необходима функциональность браузера, использование специализированных объектов позволит значительно ускорить процесс разработки. Как показано на схеме в начале главы, компоненты XPCOM являются основой прикладной части Mozilla. Технологии XPCOM и XPConnect используют различные вспомогательные файлы, прежде всего реестр (простую базу данных, сходную с системным реестром Microsoft Windows) и библиотеки типов (описания компонентов). Настройки Mozilla и информация о сертификатах также хранятся отдельно от компонентов. С точки зрения разработчика, наиболее интересной частью архитектуры XPCOM являются отдельно хранимые файлы XPIDL, которые содержат описания всех интерфейсов XPCOM в форме, удобном для чтения. Эта глава начинается с изложения нескольких концепций, особенно важных для понимания программного окружения, в котором взаимодействуют компоненты XPCOM. Затем мы переходим к обсуждению типичных задач программирования и решений, предлагаемых платформой Mozilla. Сначала рассматриваются более общие задачи, а затем специфичные для отдельных групп приложений. Затем обсуждается платформа в целом и ее система защиты. Практический раздел главы содержит множество примеров, демонстрирующих использование объектов для работы с JavaScript. 16.1. Концепции и терминологияОбширная библиотека компонентов XPCOM, входящая в состав платформы Mozilla, - особый мир, где действуют свои законы и правила. Чтобы эффективно использовать эту библиотеку, полезно познакомиться со сложившейся терминологией и принятыми соглашениями в этой области. 16.1.1.Читая чужой код: соглашения об именованииФактически платформа Mozilla образована множеством различных программ, написанных на разных языках, и разработчику часто приходится обращаться к исходным текстам, чтобы изучить те или иные возможности платформы. В большей части исходного кода Mozilla и документации используется определенный стиль кодирования, к которому надо привыкнуть. Помимо документации, разработчик может обратиться к следующим источникам:
Из перечисленных источников основным являются определения XPIDL - это необходимый минимум для "выживания" на платформе Mozilla. URL этих файлов можно найти во введении к книге. Стиль кодирования для платформы Mozilla подразумевает использование определенных соглашений об именовании. Это особенно важно для кода на JavaScript, поскольку этот язык обладает лишь слабыми механизмами типизации по сравнению с такими языками, как Java или C++. Ниже приведены некоторые примеры соглашений об именовании, применяемых в исходном коде Mozilla. Для определения характера интерфейсов XPCOM используются префиксы. Наиболее распространенным является префикс nsI (от "netscape Interface"), который применяется для обозначения интерфейсов, предназначенных для использования разработчиками приложений. Существует также ряд более специфичных префиксов, указывающих на связь интерфейса с определенным приложением или технологией, например imgI, inI, jsdI и mozI (от image, inspector, JavaScript debugger и Mozilla соответственно). Все эти интерфейсы тоже доступны для разработчиков приложений. Объекты, имеющие префикс ns (без I) не предназначены для использования разработчиками приложений. Как правило, эти объекты применяются в системном коде платформы. Для атрибутов и методов интерфейсов используются определенные соглашения об использовании прописных букв.
В любом случае, прописные и строчные буквы используются одинаковым образом в XPIDL и в JavaScript. В системном коде платформы (C/C++) имена методов транслируются из initCap в InitCap. Имена интерфейсов иногда используются в той же форме, что и в XPIDL, а иногда записываются только прописными буквами (ALL_CAPS). В коде Mozilla часто используются однобуквенные префиксы для имен переменных - атрибутов интерфейсов и аргументов методов. Эта нотация широко используется в связках XBL, системном коде на C/C++, интерфейсах XPIDL и прикладном коде на JavaScript. В последнем случае эти префиксы могут использоваться несколько бессистемно. Основные однобуквенные префиксы, используемые в коде Mozilla, представлены в таблице 16.1.
Еще один используемый префикс - PR, что означает Portable Runtime. Существует также аббревиатура NSPR, которая означает Netscape Portable Runtime - библиотека и стандарт кодирования, которые были разработаны для того, чтобы облегчить перенос Mozilla между различными операционными системами. На платформе Mozilla определен ряд типов, переносимость которых гарантирована, и эти типы имеют префикс PR. разработчик приложений, использующий компоненты XPCOM, в некоторых ситуациях может столкнуться с такой нотацией. 16.1.2. Модульное программированиеПлатформа Mozilla использует разнообразные подходы к разделению программ на части или фрагменты. Практически любой термин для "части" или "фрагмента", используемый в разработке ПО, применяется в терминологии платформы Mozilla. Ниже приведены эти термины и их корректное использование в контексте Mozilla: Связка (binding) - программный интерфейс, написанный на определенном языке программирования. В контексте Mozilla связки существуют в форме интерфейса JavaScript (ECMAScript) к объектной модели документа (DOM), описанного в стандартах Консорциума WWW, либо в форме связок XBL. Класс. Единственные классы в Mozilla - классы компонентов XPCOM. На основе каждого класса может быть создано ноль или более объектов. JavaScript 2.0 (ECMAScript 1.4) будет поддерживать объектную модель, основанную на классах, но в версии JavaScript1.5, применяемой в Mozilla в настоящий момент, классы отсутствуют. Компонент представляет собой сущность, имеющую уникальный идентификатор в системе XPCOM. Компонентом может быть класс с CID (идентификатором компонента) и соответствующим ContractID (вида @mozilla.org/test;1) или интерфейс с IID (идентификатором интерфейса). Иногда настоящими компонентами считают только классы. Интерфейс - набор точек доступа к объекту. Интерфейсы XPCOM являются единственным примером интерфейсов в Mozilla. О каждом объекте, который предоставляет точки доступа, соответствующие описанию интерфейса, говорят, что он реализует этот интерфейс. Каждый объект XPCOM и связка XBL реализует ноль или более интерфейсов XPCOM. Объекты JavaScript также могут реализовывать интерфейсы XPCOM. Библиотека. В состав платформы Mozilla входит несколько динамически подключаемых библиотек, но вряд ли они представляют особенный интерес для разработчика приложений. Иногда библиотеками называют скрипты или группы скриптов на JavaScript, которые могут предоставлять полезную функциональность другим программам. Библиотеки типов представляют собой файлы данных, определяющие интерфейсы XPCOM. Они создаются в момент компиляции платформы и автоматически используются механизмом XPConnect при обращении к интерфейсам. Модуль. Компоненты XPCOM, входящие в состав платформы, сгруппированы в модули, но этот факт значим только для разработчиков самой платформы. Модули не имеют практического смысла для разработчика приложения, если только он не создает новый модуль XPCOM. Объект. Mozilla содержит объекты XPCOM и объекты JavaScript. Объект XPCOM является экземпляром определенного класса XPCOM и реализует один или несколько интерфейсов. Объект JavaScript может находиться в широком диапазоне от простой структуры данных, целиком определенной на JavaScript, до сложного объекта платформы. Объекты платформы в скриптах на JavaScript могут быть либо объектами XPCOM, либо объектами Java. Пакет - группа взаимосвязанных файлов, установленная в chrome. Пакет имеет имя, которое соответствует каталогу (папке) файловой системы. Прототип - объект JavaScript, используемый в качестве основы для создания нового объекта JavaScript. 16.1.3. Внешние системы типовСистема XPCOM обеспечивает доступ скриптов JavaScript к другим программным окружениям, внешним по отношению к этим скриптам. Эти внешние окружения имеют собственные системы типов. Чтобы скрипты могли работать с ними, внешние типы должны автоматически конвертироваться в типы JavaScript (и обратно), либо быть доступны через специальные интерфейсы XPCOM. Из скриптов JavaScript доступны пять внешних систем типов: Базовые типы платформы, реализованные в составе NSPR. Это - переносимые типы C/C++, лежащие в основе платформы Mozilla. Типы данных RDF. Типы в документах RDF, с которыми может работать Mozilla. Типы данных схемы XML (XML schema). Mozilla способна выполнять синтаксический анализ файлов этого формата и может определять стандартные типы, встречающиеся в них. XML RPC XDR. Mozilla поддерживает сетевой протокол RPC-через-XML, включая типы данных XDR, не зависящие от платформы. Java. Виртуальная машина Java может выполняться как подключаемый модуль (plugin) платформы Mozilla, при этом скрипты могут получать доступ к типизированным объектам Java. Из пяти перечисленных систем автоматическое преобразование типов выполняется лишь при работе с Java. Остальные четыре системы используют следующие интерфейсы XPCOM:
В дополнение к этим внешним системам типов, сама архитектура XPCOM и компоненты, входящие в ее состав, также образуют систему типов, основанную на объектной модели (иерархия классов и интерфейсов). Разработчики сложных приложений широко используют эти классы и интерфейсы. 16.2. Общие приемы и методы программированияВ этом разделе описано решение общих задач программирования на платформе Mozilla. 16.2.1. Аргументы командной строкиПлатформа Mozilla, запущенная из командной строки, запоминает аргументы, переданные исполняемому файлу. В ОС Microsoft Windows платформа не запоминает аргументы командной строки, указанные при запуске последующих приложений, которые используют тот же экземпляр платформы. Используйте эти компонент и интерфейс, чтобы получить доступ к аргументам командной строки: @mozilla.org/appShell/commandLineService;1 nsICmdLineService Интерфейс nsICmdLineService поддерживает свойство argc, содержащее количество аргументов, но не argv, которое могло бы содержать строки, образующие аргументы. Свойство argc содержит количество пар аргумент-значение, а не количество строк, разделенных пробелами (традиционная практика и в UNIX, и в Windows). Поскольку свойство argv или аналогичное ему не поддерживается, вам придется угадывать имена параметров, используя метод getCmdLineValue() для получения их значений. Типичный вызов этого метода выглядит следующим образом: var url = cls.getCmdLineValue("-chrome");
Метод возвращает значение аргумента, а если аргумент с указанным именем не был использован при запуске, возвращается значение null. Этот интерфейс также содержит метод-фабрику getHandlerForParam(), который возвращает объект, имеющий интерфейс nsICmdLineHandler. Такой объект представляет собой структуру данных, доступную только для чтения, и содержащую конфигурационную информацию для обработчика командной строки, например значения по умолчанию. Каждый существующий обработчик добавляет новые аргументы командной строки, доступные платформе. При необходимости такие обработчики могут создаваться при помощи JavaScript. Средствами JavaScript невозможно получить исходную копию командной строки. 16.2.2. Структуры данных и алгоритмыЯзык JavaScript предоставляет простые массивы и объекты, которых достаточно для большинства несложных задач. За пределами JavaScript платформа Mozilla поддерживает обширную модель данных, которая представляет собой реализацию стандартов DOM Консорциума W3C. Эта модель используется при отображении и обработке документов HTML, XUL, MathML, SVG, а также XML вообще. Она обсуждается в разделе "Web- скрипты", а также в главе 5 "Скрипты". Помимо DOM, платформа предоставляет ограниченное количество интерфейсов к структурам данных. Их основное назначение - обеспечивать доступ скриптов к внутренним данным платформы. Строго говоря, эти интерфейсы не предназначены для того, чтобы создавать на их основе новые структуры данных, хотя такое их использование при разработке приложений вполне допустимо. Объекты-коллекции XPCOM, которые могут применяться сами по себе, перечислены в таблице 16.2. Хотя во многих ситуациях их использование не рекомендуется, они заслуживают упоминания.
Сами по себе эти коллекции не слишком полезны, однако для работы с ними существуют специальные интерфейсы - курсоры или итераторы. В XPCOM существует два типа курсоров. Более простой называется перечислителем (enumerator) и имеет два варианта: nsIEnumerator nsIBidirectionalEnumerator Перечислитель - курсор для перебора данной коллекции, допускающий лишь чтение данных. При этом коллекция должна быть статической, и в каждый момент времени в ней может быть определен лишь один перечислитель. Для каждого элемента коллекции перечислитель возвращает интерфейс nsISupports. Более сложная разновидность курсора называется итератор (iterator). Итераторы поддерживают такие операции, как перебор динамически изменяемой коллекции, добавление элементов к коллекции, а также одновременное использование нескольких итераторов для одной коллекции. Все эти итераторы имеют интерфейсы вида nsI{некая_строка}Iterator и редко бывают нужны сами по себе. Однако их можно использовать в качестве образцов при проектировании сложных структур данных и способов доступа к ним. Иногда итераторы возвращаются другими интерфейсами XPCOM. Стандарт DOM 2 Traversal and Ranges ("Обход и диапазоны [узлов]") описывает мощный итератор, реализация которого в Mozilla называется nsIDOMNodeIterator. Он может быть полезен при работе со структурами данных DOM. Платформа Mozilla содержит не слишком много реализаций алгоритмов общего характера. В JavaScript доступны регулярные выражения и метод для сортировки массива Array.sort(). Возможности сортировки, применяемые в шаблонах XUL, недоступны за их пределами. 16.2.3. Базы данныхПлатформа Mozilla в определенной степени поддерживает работу с базами данных, но эта поддержка развивается медленно. При сборке интегрированного пакета Mozilla с параметрами по умолчанию доступна лишь минимальная поддержка работы с базами данных; получение дополнительных возможностей требует дополнительных усилий. Базы данных, поддерживаемые платформой, можно условно разделить на пять групп: неструктурированные файлы, реляционные базы данных, базы данных, связанные с конкретными приложениями, хранилища фактов и кэши. В таблице 16.3. перечислены поддерживаемые Mozilla базы данных, основанные на неструктурированных файлах. Две последние строки таблицы требуют пояснений. dbm - устаревшая версия распространенного пакета Berkeley DB. Она используется для создания в каталоге профиля пользователя нескольких файлов, имеющих отношение к защите информации. Этот пакет не имеет интерфейса XPCOM и не может использоваться из JavaScript.
Mdb, "база данных сообщений" (message database) представляют собой базу данных, хранящую данные в одном файле и специально разработанную для Mozilla. В ней реализованы такие концепции, как курсоры, таблицы, строки, поля и схема базы данных. Mdb поддерживает как реляционные базы данных, так и более универсальные списки пар "атрибут-значение", а также связи между таблицами и строками, которые позволяют одной строке принадлежать сразу нескольким таблицам. Mdb не является многопользовательской базой данных и не поддерживает одновременное использование нескольких курсоров, транзакции и процесс восстановления. Формат файла Mbd является универсальным форматом для самоссылающихся данных, на низком уровне он сходен со структурой данных, лежащей в основе RDF. Существует интерфейс XPCOM для работы с Mdb, однако для него нет определения XPIDL, а, следовательно, и библиотеки типов. В результате эта функциональность недоступна из приложений на JavaScript. Что касается реляционных СУБД, то в версии Mozilla, собираемой по умолчанию, их поддержка отсутствует. Однако она может быть добавлена. В таблице 16.4 представлена ситуация на момент выхода Mozilla 1.4 и прогноз на ближайшее будущее. Наконец, платформа поддерживает ряд форматов файлов, разработанных для конкретных приложений. Работа со всеми этими файлами осуществляется опосредованно, с помощью интерфейсов высокого уровня. Все эти файлы находятся в каталоге профиля пользователя. Они перечислены в таблице 16.5. Файлы закладок и cookies полностью переписываются при каждом изменении. Файл адресной книги частично переписывается при каждом изменении. Mork, упоминаемая в таблице, представляет собой простую технологию хранения данных в неструктурированном файле, основанную на Mdb, о которой шла речь выше. Эта технология предоставляет ряд специализированных структур данных, которые могут использоваться для хранения записей адресной книги, а также информации о текущем состоянии сообщений электронной почты и конференций. Подобно Mdb, функциональность Mork недоступна из скриптов JavaScript. Вы можете увидеть содержимое базы данных Mork, открыв в любом текстовом редакторе файлы с информацией о сообщениях (они имеют расширение .msf), которые хранятся в том же каталоге, что и файлы почтовых ящиков.
Mork/Mdb - технология хранения данных на диске. В качестве сходной технологии, но подразумевающей хранение данных в оперативной памяти, может рассматриваться хранилище фактов RDF, особенно при использовании источника данных in-memory-datasource. Еще один вид технологий, применяемых в Mozilla и сходных с базами данных, - кэши. В частности, это кэш Web-документов, в котором хранятся локальные копии документов, расположенных на удаленных серверах, а также кэш быстрой загрузки XUL, в котором хранятся файлы chrome для отображаемых окон и элементов интерфейса. 16.2.4. Переменные окруженияЗначения переменных окружения текущего процесса могут быть получены по одному значению за запрос при помощи следующей пары из компонента и интерфейса: @mozilla.org/process/util;1 interface nsIProcess Интерфейс nsIProcess предоставляет метод getEnvironment(), который возвращает значение переменной, имя которой было передано в виде параметра. Передаваемые имена переменных конвертируются из Unicode в расширенную (восьмибитную) кодировку ASCII. Возвращаемые значения конвертируются в Unicode из расширенной кодировки ASCII. Тип операционной системы или версия Mozilla могут быть получены без обращения к переменным окружения. Для этого достаточно проанализировать значение свойства window.navigator.userAgent property. Для версий Mozilla, собранных с поддержкой отладки, переменная MOZILLA_FIVE_HOME должна содержать путь к каталогу, в котором установлены бинарные файлы Mozilla. Не существует переменной окружения, которая указывала бы путь к текущему или любому другому каталогу профиля пользователя. В целях защиты данных путь к этому каталогу содержит строку случайных символов, и установить путь к нему вручную невозможно, не зная или не угадав этой строки. Для доступа к каталогу профилей можно использовать специальный псевдоним (см. "Каталог файловой системы"). Целый ряд переменных, имеющих отношение к отладке, устанавливается при использовании версии Mozilla, собранной с поддержкой отладки (с ключом --debug-enabled). Их интерпретация весьма сложна, наиболее надежным источником информации по этому вопросу является исходный код Mozilla. 16.2.5. Файлы и папкиВ этом разделе рассказано, каким образом можно находить файлы и папки на том компьютере, где установлена платформа Mozilla. Здесь мы используем термин папка, а не каталог, поскольку последний в контексте данной главе относится, прежде всего, к службам каталогов (directory services). Работа с файлами в Mozilla довольно сложна в силу ограничений, связанных с требованиями переносимости и соответствия стандартам WWW. Код, работающий с объектами XPCOM, представляющими файлы, должен быть переносим между платформами (как минимум, между UNIX, Microsoft Windows и Macintosh), а понятие файла или папки должно быть совместимо с понятием URL. Требования переносимости влияют на работу с именами файлов и папок. Платформа Mozilla не поддерживает концепцию полного пути к файлу, выраженного в виде строки, поскольку синтаксис пути для различных платформ отличается; на некоторых платформах отсутствует само понятие пути. Даже непосредственная работа с именем файла, не содержащим полного пути, может привести к проблемам. Поэтому платформа Mozilla стремится посредством специальных абстракций изолировать разработчика приложений от непосредственных манипуляций с путями и именами файлов, за исключением тех случаев, когда требование переносимости несущественно. Ключевой абстракцией, предназначенной для решения этой проблемы, является интерфейс nsIFile. Объекты, поддерживающие этот интерфейс, часто используются в скриптах, но разработчики редко создают их вручную или извлекают информацию о пути и имени файла, хранящуюся внутри такого объекта. Это означает, что такие объекты редко создаются при помощи стандартной пары XPCOM: @mozilla.org/file/local;1 nsIFile Вместо этого объекты с интерфейсом nsIFile создаются непрямым образом, при помощи методов других интерфейсов. Для локальных файлов существует специализированный вариант интерфейса nsIFile, которому соответствует следующая пара: @mozilla.org/file/local;1 nsILocalFile Оба интерфейса могут представлять как файлы, так и папки. В существующем коде можно встретить и устаревший интерфейс для работы с файлами, который в настоящее время не рекомендован к использованию: @mozilla.org/filespec;1 nsIFileSpec Таким образом, разработчик приложения полагается на то, что объект, представляющий файл, будет создан, инициализирован и возвращен методом другого интерфейса. Существует целый ряд способов получения объектов nsIFile, представляющих нужные файлы:
Примеры использования таких методов приведены ниже в этом разделе. Интерфейс nsIFile позволяет решить проблему переносимости операций с файлами, однако остается вопрос интеграции файлов и URL. Для работы с URL используются объекты с интерфейсом nsIURL, использование которых описано в разделе "Web-скрипты". Для взаимного преобразования файлов и URL используется следующая пара XPCOM: @mozilla.org/network/protocol;1?name=file nsIFileProtocolHandler Этот интерфейс поддерживает методы newFileURI() и getFileFromURLSpec(), которые и выполняют необходимые преобразования. Интерфейс nsIIOService также поддерживает метод newFileURI(). Интерфейсы nsIFile и nsIURL позволяют получать строки, представляющие фрагменты пути к файлу или URL. Выполнив определенные операции над этими строками, приложение может создать объект nsIURL, соответствующий объекту nsIFile, и наоборот. 16.2.5.1. Использование каталога файловой системыКаталог файловой системы подробно описан в разделе "Конфигурация платформы", там же приведен и ряд примеров. Здесь мы приведем короткий пример, демонстрирующий поиск папки, используемой для создания временных файлов (см. листинг 16.1). var Cc = Components.classes;
var Ci = Components.interfaces;
var dp = Cc["@mozilla.org/file/directory_service;1"];
dp = dp.createInstance(Ci.nsIDirectoryServiceProvider);
var folder = dp.getFile("TmpD", {});
Листинг
16.1.
Инициализация объекта nsILocalFile при помощи каталога файловой системы.Центральным элементом данного кода является использование специального псевдонима TmpD для папки временных файлов. Такой подход пригоден для поиска файлов и каталогов, которые имеют определенное значение для платформы Mozilla, и для которых определены псевдонимы. Таблицы существующих псевдонимов приведены ниже, в разделе "Каталог файловой системы". 16.2.5.2. Выбор файла пользователемСоздание диалогового окна для выбора файла пользователем с последующим созданием объекта nsILocalFile на основе выбранного файла показано в листинге 16.2. var file;
var CcFP = Components.classes["@mozilla.org/filepicker;1"];
var CiFP = Components.interfaces.nsIFilePicker;
var fp = CcFP.createInstance(CiFP);
// используйте любые допустимые параметры для
инициализации объекта nsIFilePicker
fp.init(window, "File to Read", Picker.modeOpen);
if ( fp.show() != fp.returnCancel )
file = fp.file;
Листинг
16.2.
Создание объекта nsILocalFile на основе выбора пользователя.Как видно из приведенного кода, объект nsIFilePicker создает объект nsILocalFile, который можно получить, используя свойство file. Если полученный объект соответствует папке, его можно преобразовать к другой папке или файлу при помощи строки, представляющей относительный путь к ним от исходного каталога. Для этого используется метод appendRelativePath(), который принимает в качестве аргумента относительные пути, не содержащие подстроки "..". Приняв определенные меры предосторожности, можно построить сроку относительного пути, не теряя переносимости. К счастью, все системы семейства Microsoft Windows, UNIX и Macintosh поддерживают прямой слеш (/) в качестве разделителя элементов пути (хотя окно Microsoft Windows для работы с командной строкой DOS не поддерживает ее). Имейте в виду, что некоторые пользователи Microsoft Windows (и, в отдельных случаях, пользователи Linux) могут не иметь поддержки длинных имен файлов (LFN), что ограничивает имена файлов форматом "8.3" или 14 символами. Интерфейс nsIFile поддерживает ряд атрибутов и методов, которые могут быть полезны при формировании переносимого пути. Наконец, если приложение не должно быть переносимым или допускает использование отдельных фрагментов кода для каждой из поддерживаемых платформ, можно инициализировать nsILocalFile непосредственно при помощи строки, представляющей путь, использовав для этого метод initWinPath(). При этом следует экранировать символы обратного слеша в путях Microsoft Windows (\\) или использовать вместо них прямой слеш. Отдельный код для различных платформ может иметь вид ряда операторов if, проверяющих текущую платформу. 16.2.5.3. Использование строкового литерала или URLКак уже было сказано, если приложение не должно быть переносимым или допускает использование отдельных фрагментов кода для каждой из поддерживаемых платформ, объект nsILocalFile может быть инициализирован непосредственно при помощи строки. Пример соответствующего кода приведен в листинге 16.3. var file;
var CcLF = Components.classes["@mozilla.org/local/file;1"];
var CiLF = Components.interfaces.nsILocalFile;
var file = CcLF.createInstance(CiLF);
file.initWithPath("C:\\WINDOWS\NOTEPAD.EXE");
Листинг
16.3.
Инициализация объекта nsILocalFile при помощи литерала.Литерал "C:" можно заменить переносимым объектом, представляющим корневую папку файловой системы, которую можно получить при помощи каталога файловой системы и псевдонима DrvD. Использование в качестве разделителя прямого слеша (который поддерживают все платформы, включая Microsoft Windows) также сделает этот фрагмент более переносимым. Локальный файл может быть также задан с помощью URL. Преобразовать URL в файловый объект можно следующим образом: var conv = Cc["@mozilla.org/network/protocol;1?name=file"]; conv = conv.createInstance(Ci.nsIFileProtocolHandler); var url = ... // Существующий объект nsIURL var file = conv.getFileFromURLSpec(url); URL, используемый в этом примере, должен иметь префикс file:. Путь к файлу можно также получить, используя свойство filePath объекта nsIURL, например: file.initWithPath(myURL.filePath.replace(/\|/,":")); В данном случае объект myURL поддерживает интерфейс nsIURL. Замена регулярного выражения при помощи метода replace() приводит фрагмент URL вида "C|/test" к "C:/test". Нужно иметь в виду, что сетевые пути в системе Microsoft Windows (пути UNC) вида \\saturn\tmp при представлении в виде URL требуют префикса из пяти прямых слешей (http://///saturn/tmp), причем соответствующее соглашение еще не устоялось окончательно. 16.2.5.4. Работа с файлами и папкамиПосле того как файл найден и представлен соответствующим объектом, его читают, в него записывают данные или выполняют с ним другие действия. В программном окружении JavaScript платформы Mozilla не используются дескрипторы или идентификаторы (handle) файлов, а также указатели на файлы. Это означает, что в JavaScript не могут быть созданы каналы (pipes), основанные на дескрипторах файлов. Интерфейс nsIPipe создает канал уровня приложения, который не является традиционным каналом UNIX. Из скриптов невозможно создавать именованные каналы (или символические ссылки), однако можно использовать для чтения и записи уже существующие каналы. Говоря коротко, платформа Mozilla не предназначена для прямого доступа к файлам на низком уровне из скриптов JavaScript. Вместо идентификаторов файлов Mozilla использует объекты. При этом скрипту приходится работать, как минимум, с двумя объектами. Один из них представляет используемый файл или папку - это может быть объект nsIFile или nsILocalFile. Этот объект - спецификатор имени файла. Второй объект представляет поток данных, из которого данные читаются и в который они пишутся. Это спецификатор содержимого файла. Для работы с файлом должны быть созданы оба объекта, причем как связанные друг с другом. Потоки и другие средства работы с содержимым подробно обсуждаются ниже в разделе "Передача данных". Потоки, доступные из JavaScript на платформе Mozilla, аналогичны потокам C++ или Java, однако в данном случае перегрузка операторов отсутствует. 16.2.5.5. Работа с архивами ZIP и JARСледующая пара XPCOM, основанная на тех же принципах, что и nsIFile, обеспечивает доступ к содержимому локальных файлов .zip и .jar: @mozilla.org/libjar/zip-reader;1 nsIZipReader С помощью этого интерфейса могут также создаваться новые архивы Zip. Конверторы потоков, описанные в разделе "Преобразование содержимого потоков", могут использоваться для работы с потоком сжатого содержимого в необработанном виде. 16.2.6. Прерывания и сигналыНе существует способа отправлять или перехватывать сигналы операционной системы из скриптов JavaScript. Чтобы компонент XPCOM мог перехватывать сигналы, он должен быть написан на Java или C/C++. Интерфейс nsIThread может использоваться для управления выполнением фрагмента кода, которое может быть прервано. При этом код, выполнение которого должно быть прервано, не может быть написан на JavaScript. Интерпретатор JavaScript платформы Mozilla выполняется в одном потоке вычислений (thread), и не может прервать собственное выполнение. Из этого следует, что прерывания, основанные на потоках вычислений, неприменимы в приложениях, написанных исключительно на JavaScript. В качестве замены прерываний могут использоваться технологии, ориентированные на события (см. лекцию 6 "События"), и система команд Mozilla (см. лекцию 9 "Команды"). 16.2.7. Сетевые протоколыMozilla поддерживает ряд хорошо известных прикладных сетевых протоколов, например FTP. При этом Mozilla предполагает, что протоколом транспортного уровня является TCP/IP. Другие транспортные протоколы, например RS232, X.25 или TP4, могут использоваться, только если они "упакованы" в TCP/IP. Mozilla поддерживает следующие протоколы низкого уровня:
Как правило, приложения на платформе Mozilla не работают непосредственно с сетевыми протоколами. Сетевые ресурсы идентифицируются при помощи URL, и префикс метода доступа (например, http:), входящий в состав URL, определяет необходимый протокол. Как правило, объект сетевого канала принимает URL, после чего поддержка нужного протокола задействуется платформой автоматически, и с точки зрения приложения все "просто работает". Тем не менее, конкретные протоколы доступны в виде объектов, которые могут быть созданы при помощи следующей пары XPCOM: @mozilla.org/network/protocol;1?name={x} nsIProtocolHandler
В приведенном имени компонента {x} должно быть заменено на идентификатор конкретного протокола, например ftp или http. Все протоколы (точнее, схемы URL), поддерживаемые Mozilla, доступны как содержимое массива window.Components.classes. Каждый из них представлен отдельным компонентом. С помощью настроек можно сконфигурировать Mozilla на уровне портов IP, активизируя (открывая) или отключая (закрывая) конкретные порты. Открытие порта имеет практический смысл лишь в том случае, когда соответствующий порт открыт на уровне операционной системы. Открытие дополнительных портов снижает уровень защищенности системы на уровне приложений, и может быть рекомендовано лишь при использовании сетевого экрана (файрволла). Получить доступ к полному набору сетевых настроек Mozilla можно, введя в строке адреса браузера about:config. Имена параметров, имеющих отношение к сети, начинаются с префикса network. Разработчики приложений также имеют доступ к сокетам. Операционные системы представляют соединение TCP/IP при помощи сокета, имеющего дескриптор, аналогичный дескриптору файла. На платформе Mozilla соединение, дескриптор и прочие особенности реализации инкапсулированы в объект, с которым и имеют дело скрипты. Такой объект-сокет является самым низким уровнем работы с сетью, с которым может иметь дело разработчик на платформе, собранной с параметрами по умолчанию. Наконец, существует проект Protozilla, информация о котором доступна на сайте www.mozdev.org, и который позволяет расширять поддержку сетевых протоколов в Mozilla. С помощью расширения, разработанного в рамках этого проекта, можно добавлять к Mozilla поддержку новых протоколов, причем для этого достаточно программирования только на JavaScript. Требования к этим протоколам следующие: они должны быть реализованы поверх сокетов TCP/IP, терпимы к небольшим задержкам, соответствующий код должен реализовывать интерфейс nsIProtocolHandler и быть зарегистрирован как полноценный компонент XPCOM. Теперь мы переходим к обсуждению конкретных задач, возникающих при работе с сетью на низком уровне. Работа с сетью на уровне приложений описана в разделах "Передача данных" и "Web-скрипты". 16.2.7.1. Определение IP-адресаЧтобы определить IP-адрес по заданному доменному имени, используйте следующую пару XPCOM: @mozilla.org/network/dns-service;1 interface nsIDNSService Объект, созданный таким образом, возвращает IP-адрес для заданного имени домена или текущего узла в форме строки вида "192.168.1.10". Разрешение доменных имен - медленная операция. Xтобы работа приложения не приостанавливалась до завершения, следует использовать метод lookup(), которому должен быть передан слушатель с интерфейсом nsIDNSListener. В этом случае запрос будет выполняться асинхронно. Реализуйте объект-слушатель на чистом JavaScript. 16.2.7.2. Создание сокетаСоздание соединения с использованием сокета включает несколько этапов. Для работы с сокетом вам, в конечном счете, понадобится создать объект nsITransport. Получив этот объект, можно до некоторой степени забыть, что вы работаете с сокетом, и использовать методы более высокого уровня, описанные в разделе "Передача данных". В целом, техника работы с сокетом, доступная разработчику приложений на платформе Mozilla, отличается довольно высоким уровнем абстракции. Например, ему недоступен API ioctl(2) для настройки параметров сокета. Создавая объект nsITransport, необходимо предусмотреть возможность того, что между платформой Mozilla и удаленным компьютером, с которым устанавливается соединение, находится proxy-сервер. Если вы не уверены в его отсутствии, создайте объект nsIProxyInfo для адреса удаленного компьютера. Объект nsIProxyInfo может быть создан при помощи методов newProxyInfo() или examineForProxy() следующей пары XPCOM: @mozilla.org/network/protocol-proxy-service; nsIProtocolProxyService Затем, используя полученный объект nsIProxyInfo или null, если вы уверены в том, что proxy-сервера не существует, создайте объект-фабрику для получения объекта nsITransport. Объект-фабрика создается при помощи следующей пары XPCOM: @mozilla.org/network/socket-transport-service;1 nsISocketTransportService Затем нужно создать объект nsITransport, передав объект nsIProxyInfo методу createTransport() объекта-фабрики. Полученный объект будет поддерживать интерфейс nsISocketTransport, представляющий простой сокет TCP/IP. Если необходимо создать сокет SOCKS, следует использовать метод createTransportOfType() и указать в качестве типа "socks" для протокола SOCKS 5.0 или "socks4" для протокола SOCKS 4.0. Чтобы создать сокет UNIX (IPC), укажите тип "ipc". Транспортный объект, созданный таким образом, может использоваться как сокет или как обычный транспортный объект. Сокеты SOCKS используют шифрование, поэтому их можно создать лишь в том случае, когда в составе платформы установлены и настроены соответствующие модули шифрования и ключи. По умолчанию эти элементы установлены и сконфигурированы в профиле пользователя как классического браузера, так и браузера Mozilla. В состав платформы Mozilla входят и другие интерфейсы для работы с сокетами, однако все они недоступны из JavaScript. Просматривая определения интерфейсов в файлах XPIDL, обращайте внимание на пометку [noscript] перед именем интерфейса. Она означает, что интерфейс недоступен из JavaScript. В листинге 16.4 приведена простая программа на Perl, которая может использоваться в качестве сервера для тестирования соединений, установленных через сокет. Эта программа принимает данные от всех клиентов, подключившихся к ней, и направляет их в стандартный поток вывода stdout. Программа не поддерживает протокол SOCKS и не возвращает клиентам никаких данных. use IO::Socket;
my ($server, $client, $host);
$server = IO::Socket::INET->new(
Proto => 'tcp', LocalPort => 80, Listen => SOMAXCONN, Reuse=> 1);
while ($server && ($client = $server->accept()))
{
while ( <$client> ) { print; }
close $client;
}
Листинг
16.4.
Реализация сервера для тестирования соединенийДля работы этой программы необходима корректная настройка порта на уровне операционной системы. 16.2.7.3. Создание сеанса FTPПлатформа Mozilla не поддерживает работу с сеансами FTP на низком уровне. Элементарную операцию, доступную для разработчика, составляет обращение к URL при помощи объекта nsIChannel. Это означает, что каждый сеанс FTP состоит не более чем из четырех команд. На псевдокоде их можно записать следующим образом: open {hostname and port} //открыть сеанс
cd {directory} // перейти в нужный каталог
dir OR get {file} //получить содержание каталога или нужный файл
close //закрыть сеанс
Этот сеанс FTP осуществляется внутри платформы. Разработчик приложений не получает информации о выполнении отдельных команд и не может отдавать собственные команды. На практике это означает, что единственный способ создания сеанса FTP, доступный разработчику приложений, - запросить документ, в URL которого указан метод доступа ftp:. Эта процедура подробно описана в разделах "Загрузка файлов" и "Каналы". Если приложению необходимо перемещаться по иерархии каталогов FTP, потребуется несколько последовательных запросов. Как известно, URL может представлять не только отдельный файл, но и каталог FTP. При обращении к такому URL платформа возвращает содержимое каталога, правда, оформленное в виде HTML-документа. Проанализировав этот документ, можно получить список файлов и подкаталогов, находящихся в исходном каталоге, к которым, в свою очередь, можно сформировать запрос. Тот же самый подход - сессия FTP, выглядящая как обращение к URL, - используется и при загрузке файлов на FTP-сервер. Подробнее об этом рассказано в разделе "Загрузка файлов". Если ни один из предложенных методов не подходит для ваших целей, можно создать два сокета средствами JavaScript и, используя их, самостоятельно реализовать протокол FTP. При этом важно позаботиться о производительности приложения. Можно ожидать, что этот подход окажется почти столь же трудоемким, как и написание полноценного компонента XPCOM, реализующего протокол FTP, на C/C++. 16.2.8. Процессы и потоки вычисленийВозможно, фрагмент кода, который предполагается запустить из основной программы, не нуждается в отдельном процессе или потоке вычислений (thread). В таком случае можно запланировать его выполнение при помощи очереди событий. О том, как это сделать, рассказано в главе 6 "События". Если создать процесс или поток все же необходимо, читайте этот раздел. Простейший способ запустить отдельную программу - активизировать ее с помощью командной оболочки операционной системы. При этом программа запускается так, как если бы ее активизировал пользователь (например, щелкнув по значку на рабочем столе). Чтобы это сделать, сначала нужно создать файловый объект при помощи следующей пары XPCOM: @mozilla.org/file/local;1 nsILocalFile Затем следует связать полученный объект с каким-либо существующим файлом (см. раздел "Файлы и папки"), после чего вызвать метод launch() этого объекта. Имейте в виду, что в системе UNIX поведение метода launch() определяется настройками среды GNOME, а не значением переменной окружения PATH. Приложение, запущенное таким образом, не зависит от процесса, в котором выполняется платформа Mozilla, и не может быть остановлено средствами последней. Более общий способ запуска процессов связан с использованием следующей пары XPCOM: @mozilla.org/process/util;1 nsIProcess Имейте в виду, что этот интерфейс до сих пор не реализован полностью на всех платформах, поддерживаемых Mozilla. Чтобы воспользоваться им, как и в предыдущем случае, нужно создать объект nsILocalFile и связать его с соответствующим исполняемым файлом. Поскольку код для работы с процессами, как правило, зависит от платформы, можно использовать для этого непереносимый метод initWithPath(). Передайте полученный объект методу init() объекта nsIProcess, а затем вызовите метод run(), чтобы создать процесс. Пример вызова этого метода приведен ниже: var blocking = true;
var argv = ["arg1","arg2"];
var result = {};
nsIProcess_object.run(blocking, argv, argv.length, result);
В процессе выполнения метода run() к объекту result, который является обязательным аргументом метода, добавляется поле value, которому в свою очередь присваивается значение 0 в случае успешного запуска процесса. Если аргумент blocking имеет значение true, выполнение Mozilla будет приостановлено до завершения запущенного процесса; при этом никакие окна Mozilla обновляться не будут. Если же аргументу присвоено значение false, выполнение Mozilla будет продолжено. В любом случае, по завершении запущенного процесса будет установлено значение свойства exitValue объекта nsIProcess. Придется поэкспериментировать, чтобы установить, какие значения соответствуют нормальному завершению процесса на различных платформах. Работа с потоками вычислений более сложна. С точки зрения разработчика приложений, отдельный поток вычислений представляет собой всего лишь фрагмент кода, выполнение которого запланировано при помощи метода window.setTimeout(). Строго говоря, в данном случае существует лишь иллюзия отдельного потока - запланированное выполнение скрипта ни при каких условиях не начнется раньше, чем завершится текущий скрипт. Это связано со способом реализации интерпретатора JavaScript в составе платформы Mozilla. На низком уровне платформа поддерживает отдельные потоки вычислений. Система потоков компонентной модели XPCOM может рассматриваться как упрощенный аналог системы потоков Microsoft COM. Потоки вычислений используются для разнообразных целей, простейший пример - работа с FTP, для которой требуется одновременная поддержка двух соединений. Однако интерпретатор JavaScript, входящий в состав платформы, выполняется лишь в одном потоке. Хотя интерпретатор сам по себе допускает наличие нескольких одновременно работающих экземпляров, платформа Mozilla не использует эту возможность. Хотя интерпретатор не поддерживает истинные потоки вычислений, для работы с потоками предусмотрен ряд интерфейсов. Фактически, они позволяют организовывать код более аккуратно, чем при использовании методов setTimeout() и setInterval(). Последовательность действий по созданию потока приведена в листинге 16.5: var Cct = Components.classes["@mozilla.org/thread;1"];
var Cit = Components.interfaces.nsIThread;
var thread = { Run : function ()
{ alert(this.foo+" - выполняемый поток"); }
foo : "bar"
};
var mgr = Cct.createInstance(Cit);
mgr.init(thread, 0, Cit.PRIORITY_NORMAL, Cit.SCOPE_GLOBAL,
Cit.STATE_JOINABLE);
mgr.join();
alert("поток создан");
Листинг
16.5.
Пример создания потока вычисленийОбъект, представляющий фрагмент исполняемого кода (в данном случае - объект thread), поддерживает интерфейс nsIRunnable. Он содержит собственно исполняемый код (метод Run()), а также данные, которые могут потребоваться для выполнения этого кода. Объект mgr (менеджер потока) содержит данные о конфигурации и состоянии потока вычислений. С помощью вызова метода join() поток помещается в очередь на выполнение или возобновление приостановленного выполнения (приостановка и последующее возобновление выполнения невозможны для кода, написанного для JavaScript). join() не эквивалентен методу eval(), поскольку его вызов не приводит к немедленному выполнению кода. Вместо этого код, представленный объектом, помещается в очередь, и интерпретатор JavaScript дойдет до него не раньше, чем закончится выполнение текущего скрипта. Поскольку интерпретатор выполняется в одном потоке и не может быть приостановлен другим потоком, сообщение в последней строке листинга всегда выдается раньше, чем сообщение из кода в объекте thread. Это означает, что ситуация конкуренции потоков (race condition) в JavaScript на платформе Mozilla невозможна - один "поток вычислений" должен завершиться до запуска следующего "потока". Поэтому, например, в скриптах JavaScript невозможно написать бесконечный цикл, рассчитанный на прерывание из другого потока, - такой цикл никогда не будет прерван. Таким образом, "потоки вычислений" в JavaScript являются всего лишь средством структурирования кода, но не параллельного выполнения. Работа с истинными потоками выполнения из скриптов возможна лишь при обращении к компонентам XPCOM, которые написаны не на JavaScript и поддерживают интерфейс nsIRunnable. Кроме того, скрипт JavaScript может создавать истинные потоки вычислений, взаимодействуя с виртуальной машиной Java. При этом создаются "чистые" потоки Java, которые выполняются в соответствующей программной среде. 16.3. Передача данныхВ этом разделе описывается универсальная инфраструктура, используемая для чтения, записи и передачи содержимого в приложениях платформы Mozilla. В этом разделе также рассматривается обработка фактов RDF, в то время как анализ документов XML обсуждается в разделе "Web-скрипты". 16.3.1. Обработка содержимого: основные концепцииОдна из важнейших функций прикладной части Mozilla - обработка содержимого Web-документов и других данных. Для этого инфраструктура платформы должна обеспечивать получение данных из внешних источников, а также передачу данных между различными составляющими платформы. В основе этой инфраструктуры лежит целый ряд концепций, относящихся к обработке и передаче содержимого и других данных. В главе 6 "События" описаны слушатели, наблюдатели и источники событий. Эти инструменты ориентированы на работу с событиями и могут использоваться лишь для передачи очень небольших фрагментов данных. Их возможностей недостаточно для построения систем работы с содержимым, хотя слушатели и наблюдатели могли бы быть полезным дополнением для таких систем. Однако система обработки и передачи содержимого должна быть рассчитана на работу с целыми документами. Основные концепции, лежащие в основе инфраструктуры Mozilla для работы с содержимым, - файлы, папки, потоки данных, сеансы, каналы, транспорты, а также источники и приемники данных. Такие понятия, как файл и каталог (папка) широко используются практически во всех операционных системах. Работа с ними описана в разделе "Общие приемы и методы программирования". Поток данных1) является самым низким уровнем передачи данных платформы Mozilla. Поток работает на уровне последовательностей байтов, октетов или символов, подобно потокам ввода-вывода C++ и Java или командных оболочек UNIX и DOS. В потоки можно записывать данные или читать из них в зависимости от источника и приемника данных. Mozilla также поддерживает потоки Unicode, в которых элементарной единицей данных является двухбайтный символ Unicode, а не однобайтный символ "расширенной таблицы ASCII", как в обычных потоках данных. Сеанс представляет собой набор конфигурационной информации о выполняемом процессе, задании или деятельности. Такая конфигурационная информация используется, прежде всего, самим процессом. Однако при этом сеанс не является самим процессом, хотя его можно рассматривать в качестве контроллера последнего. Примером сеанса может служить передача файла по FTP. Доменное имя FTP-сервера, имя пользователя, пароль, а также сокеты, через которые установлено соединение, представляют собой часть информации сеанса FTP. При этом фактическая передача данных выполняется другим модулем или компонентом, в то время как объект сеанса лишь хранит необходимую информацию. Понятие сеанса имеет смысл и за пределами сетевого взаимодействия - так, в Mozilla специальный объект сеанса соответствует перетаскиванию при помощи мыши. Такие объекты используются для решения различных задач платформы Mozilla. Канал передачи данных2) представляет собой элемент архитектуры платформы, который выполняет фактическую передачу данных. В Mozilla каналы используются, как правило, для получения документов, имеющих URL. Иногда каналы предоставляют дополнительную функциональность, но их основное назначение просто - обеспечить передачу данных от какого-либо источника, например от удаленного Web-сервера. При этом может выполняться физическая передача данных из одного места в другое или "логическая" передача - преобразование данных из одной формы в другую. При этом канал управляет процессом передачи, в то время как непосредственное чтение и запись, как правило, выполняются на уровне потока данных. Транспорт представляет собой элемент платформы, отвечающий за сетевое взаимодействие с использованием одного или нескольких протоколов. Так, если канал обеспечивает передачу данных на высоком уровне (получение документа, имеющего указанный URL), то на уровне транспорта реализована поддержка конкретных протоколов, например SMTP или TCP/IP. Источники и приемники рассматриваются в следующем разделе. 16.3.1.1. Источники и приемникиКонцепция источников и приемников занимает важное место в архитектуре Mozilla. Обычно они используются для обработки XML- документов. Источники и приемники образуют один из самых высоких уровней обработки информации в составе платформы и, как правило, выполняют преобразования, зависящие от типа содержимого. Источники и приемники (стоки) представляют собой универсальную концепцию, широко используемую в науке и инженерном деле. Многие разработчики впервые встречаются с ними, знакомясь с диаграммами потоков данных. На этих диаграммах, как для обычной кухонной раковины, подразумевается, что поток данных (воды) начинается у источника и заканчивается у приемника (стока). Это, однако, вопрос точки зрения, и, в зависимости от вашего места в этой схеме, ее можно "вывернуть наизнанку". Действительно, если раковина существует и работает, вода вытекает из крана (источник) и попадает в сток (приемник). Однако ситуация меняется, если раковины не существует, и вам самим нужно доставить воду из крана в сточное отверстие, находящееся на некотором расстоянии. Первое, что вам нужно сделать, - набрать воду из-под крана в какую-то промежуточную емкость. При этом емкость оказывается приемником. В конце концов, вам понадобится вылить воду в сточное отверстие, и в этом случае та же емкость окажется источником. Таким образом, в этом примере последовательность приемника и источника перевернута. Именно такая ситуация характерна для работы с Mozilla. Для того чтобы загрузить содержимое документа в память, используется объект-приемник. Затем это содержимое или его часть можно извлечь при помощи источника данных. Независимо от того, в каком порядке используются приемник и источник в каждом конкретном случае, источник всегда является производителем, а приемник - потребителем. С точки зрения разработчика приложения, если содержимое документа еще не находится в памяти платформы Mozilla (например, документ хранится в файле на диске), сначала необходимо создать приемник, чтобы загрузить это содержимое. На следующем этапе создается источник, с помощью которого различные части приложения могут получить доступ к загруженному содержимому. В некоторых случаях документ загружается в память автоматически, и тогда разработчику приходится создавать только источник. В этой схеме есть одна сложность - при работе с документами в них могут вноситься изменения. Как правило, приемники используются для первоначальной загрузки содержимого в память и, таким образом, обеспечивают лишь одностороннюю обработку данных. Это означает, что ответственность за управление изменениями в документе лежит на источнике. Таким образом, источники не только обеспечивают доступ к содержимому документа, но и часто способны изменять его. Mozilla не предоставляет универсальных интерфейсов для работы с источниками и приемниками. Существуют лишь специализированные интерфейсы для работы с конкретными видами данных. Архитектура платформы позволяет нескольким приемникам или источникам одновременно работать с одним документом, находящимся в памяти. 16.3.1.2. Специализированные источники и приемникиИсточники и приемники служат для обработки содержимого на высоком уровне. Источники и приемники, входящие в состав платформы Mozilla, предназначены для различных целей. Источники данных используются для обработки содержимого RDF. Вместо того чтобы работать с документом на уровне отдельных тегов или объектов DOM, источники данных работают на уровне фактов RDF. Приемников данных RDF не существует. Источники данных широко используются в системе шаблонов XUL, причем как с источниками, так и с шаблонами можно работать из скриптов. Источники фактов (источники данных RDF) также позволяют добавлять, изменять и удалять факты, содержащиеся в документе RDF, загруженном в память. Некоторые источники данных Mozilla (так называемые внутренние источники данных) получают свое содержимое непосредственно от платформы, а не из внешних документов RDF. Исходная информация для таких источников содержится во внутренних структурах данных платформы или, например, в файле закладок пользователя. Синтаксический анализатор (parser) представляет собой разновидность приемника. Он получает поток содержимого, как правило, из какого-либо документа, и преобразует его в структуру данных. Примером может служить анализатор, который получает документ XML и создает на его основе дерево DOM. В состав Mozilla входят синтаксические анализаторы для всех известных платформе приложений XML. Сериализатор (serializer) является источником, обратным синтаксическому анализатору. Он преобразует структуру данных в неструктурированный поток содержимого, чаще всего - в документ XML. 16.3.1.3. Архитектура обработки содержимого.Различные инструменты обработки данных, описанные в этом разделе, можно неофициально рассматривать как систему уровней или слоев, хотя эта система организована не так строго, как, например, стек сетевых протоколов. Уровни обработки данных показаны на рис.16.1. 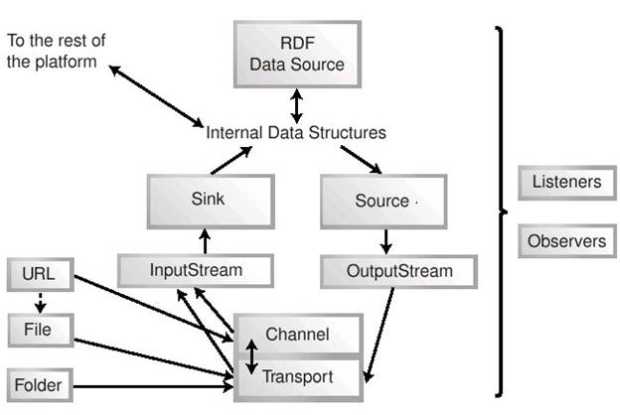 Рис. 16.1. Уровни обработки данных На рисунке приведена принципиальная схема, которая не является точным отображением объектной модели платформы, хотя и довольно близко соответствует некоторым отношениям между объектами. Мы видим, что каналы и транспорты тесно связаны между собой, однако не настолько тесно, чтобы их нельзя было использовать независимо друг от друга. Потоки ввода и вывода делают обрабатываемые данные или содержимое доступными для остальной платформы. Приемники и источники - синтаксические анализаторы, сериализаторы и другие средства преобразования - играют важную роль в общей системе обработки данных. Источники данных RDF занимают в системе особое место - они работают на очень высоком уровне и имеют дело с содержимым, которое уже разбито на факты. Все эти инструменты поддерживают работу с наблюдателями и слушателями. Файлы и URL используются для организации доступа к данным на низких уровнях обработки. На схеме не показаны многочисленные интерфейсы, представляющие собой конкретные реализации изображенных элементов, а также конкретные способы взаимодействия с остальной платформой. 16.3.2. Потоки данныхЕсли нужный файл или другой источник информации доступен, необходимо создать поток для работы с его содержимым. Потоки являются основой архитектуры обработки данных в Mozilla, и существует множество интерфейсов, ориентированных на работу с потоками. Среди них - интерфейсы для создания, инициализации, преобразования потоков и управления ими. Существуют специализированные разновидности потоков, в частности, потоки с произвольным доступом и потоки, основанные на строках. Практически для любой распространенной задачи можно найти подходящий интерфейс-поток - просмотрите интерфейсы, содержащие в названии слово Stream. Чтобы продемонстрировать эту гибкость, в листинге 16.6 показаны три способа создания потока. Этот поток используется для чтения локального файла (последовательности байтов). var Cc = Components.classes; var Ci = Components.interfaces; var mode_bits = 0x01; // from nsIFileChannel var perm_bits = 0; // from Unix/Posix open(2) var file_bits = 0; // from nsIFileInputStream var stream; var file = ... // см. листинг 16.3 или 16.2 // [1] Непосредственное создание stream = Cc["@mozilla.org/network/file-input-stream;1"]; stream = stream.createInstance(Ci.nsIFileInputStream); stream.init(file, mode_bits, perm_bits, file_bits); // [2] Создание на основе транспорта var trans = Cc["@mozilla.org/network/stream-transport-service;1"]; trans = trans.getService(Ci.nsIStreamTransportService); trans = trans.createInputTransport(stream,0,-1,true); var stream2 = trans.openInputStream(0,-1,0); // [3] Создание на основе канала var channel = Cc["@mozilla.org/network/local-file-channel;1"] channel = channel.createInstance(Ci.nsIFileChannel); channel.init(file, mode_bits, perm_bits); stream = channel.open(); // В любом случае, работа с потоком средствами JavaScript var s2 = Cc["@mozilla.org/scriptableinputstream;1"]; s2 = s2.createInstance(Ci.nsIScriptableInputStream); s2.init(stream); var bytes = 100; var content = null; content = s2.read(bytes);Листинг 16.6. Несколько способов создания потока В каждом из трех случаев в какой-то момент инициализации в качестве аргумента передается ранее созданный объект nsILocalFile. Пример 1. Файл читается или записывается непосредственно с использованием потока. Если не принять специальных мер, операции с файлом выполняются синхронно. Пример 2. Это несколько необычный пример, поскольку в качестве отправной точки для создания потока используется поток. Объект- транспорт должен быть на чем-то основан, и в отсутствие сетевого протокола (соединения) единственной альтернативой является поток. Исходный поток используется для того, чтобы получить содержимое файла. Поток, возвращаемый транспортом (переменная stream2), отличается от исходного потока, поскольку транспорт заранее получает данные файла, чтобы передать их пользователю по очередному запросу. При работе же с исходным потоком (пример 1) чтение данных файла выполняется только тогда, когда пользователь обращается к потоку с запросом. Кроме того, транспорт автоматически закрывает "соединение" с файлом после того, как получены все данные файла. Пример 3. Канал позволяет получить файл, не делая никаких предположений о механизме получения. Из соображений эффективности JavaScript не позволяет непосредственно читать данные из потоков или записывать в них. Вместо этого необходимо создать специальный объект для выполнения операций чтения и записи, передав ему поток. Пример создания такого объекта, а также чтения данных с его помощью приведен в последних строках листинга. Достаточно небольших изменений в примерах 1 и 2, чтобы создать поток для записи вместо потока для чтения. В примере 3 такая замена невозможна, поскольку каналы применяются только для чтения. При записи данных предполагается, что поток вывода состоит из однобайтовых символов (расширенная кодировка ASCII). При выводе любого содержимого, состоящего из символов Unicode UTF16 (как, например, строки JavaScript), символы приводятся к однобайтовым - старший байт отбрасывается. Для вывода строк Unicode (как правило, они выводятся в кодировке UTF8) необходимо преобразование содержимого, которое обсуждается в следующем разделе. 16.3.2.1. Преобразование содержимого потоковВнутри платформы все строки представлены с помощью Unicode. Простые файлы могут читаться как бинарные данные (для этого используется интерфейс nsIBinaryInputStream), как восьмибитные символы (вариант по умолчанию) или как Unicode в соответствующей кодировке. Последний вариант имеет место при чтении файлов XML и их преобразовании в иерархию DOM, при получении данных из источника, который предоставляет информацию о кодировке (например, по протоколу HTTP), или при чтении DTD-файлов. Для преобразования содержимого потока используется следующая пара XPCOM: @mozilla.org/intl/scriptableunicodeconverter;1 nsIScriptableUnicodeConverter Mozilla также поддерживает множество компонентов с идентификатором контракта следующего вида: @mozilla.org/streamconv;1?from={mime1}to={mime2}
Здесь mime1 и mime2 - типы MIME. Эти компоненты поддерживают интерфейс nsIStreamConverter. Такой объект получает входной поток и преобразует его содержимое, создавая при этом новый поток, из которого могут читаться преобразованные данные. Преобразования, поддерживаемые платформой, приведены в таблице 16.6. Подобный конвертер может быть реализован на чистом JavaScript.
Изучив описание XPIDL объекта nsIStreamConverter, можно понять, каким образом такое преобразование может быть реализовано с использованием двух объектов nsIStreamListener вместо двух полноценных потоков. Такой подход позволяет конвертерам работать не только с потоками ввода, но и с потоками любого типа. 16.3.3. ТранспортыОбъекты XPCOM транспортного уровня отвечают за передачу содержимого изнутри платформы Mozilla и наоборот. Таким образом, транспорты являются более общим средством, чем потоки, которые предназначены для передачи информации внутри платформы или операций чтения/записи с локальными файлами. Если потоки, как правило, выполняют синхронные операции и работают непосредственно с указанным источником, транспорты могут выполнять как синхронные, так и асинхронные операции. При этом они могут буферизовать данные в промежутках между запросами пользователя. Транспортные уровни, доступные в настоящее время, приведены в таблице 16.7.
Пять транспортов, приведенных в таблице, предназначены для: всех потоков, включая локальные файлы; сокетов; кэша браузера; транспорта HTTP для запросов SOAP; защищенного (SSL) транспорта HTTP для запросов SOAP. Реализация stream-transport-service является относительно новой (с версии 1.3) и заменяет недоступную более реализацию file-transport-service. Вам могут встретиться примеры кода, использующие старую реализацию. 16.3.4. КаналыКаналы представляют собой односторонний (только для чтения) механизм получения содержимого указанного URL. Хотя в принципе канал может использоваться и для чтения файлов, его основное назначение - работа c URL. Именно каналы выполняют значительную часть операций с содержимым при загрузке документа. Единственным каналом, который используется не для чтения, является специализированный канал для отправки форм, загрузки файлов на удаленный сервер или публикации Web-страниц. В обычных ситуациях разработчик приложений редко создает каналы самостоятельно. Подобно объектам nsIFile и потокам, каналы чаще всего создаются платформой при выполнении операций более высокого уровня. Файл и поток образуют пару объектов, тесно связанных между собой, и аналогичную пару образуют канал и URL. Эта аналогия не идеальна, поскольку каналы создаются разработчиком вручную значительно реже, чем потоки. Как правило, работа с каналами скрыта в глубине того или иного протокола. Второе различие состоит в том, что канал представляет собой усовершенствованную реализацию запроса (объект nsIRequest), который, в свою очередь, является модернизированным вариантом объекта-URL. Так что, строго говоря, канал и URL не являются независимыми объектами. Как правило, работа с каналами начинается с обращения к следующей паре XPCOM: @mozilla.org/network/io-service;1 nsIIOService Этот компонент позволяет получить интерфейс nsIIOService при помощи метода getService(). Применительно к транспортам данный интерфейс фактически представляет собой службу имен для схем URL. Схема URL представляет собой первую группу символов полного URL (до двоеточия), которая указывает на протокол (метод доступа к ресурсу). Компонент принимает в качестве параметра имя схемы и возвращает программный объект для работы с соответствующим протоколом. Таким образом, интерфейс nsIIOService представляет собой отправную точку для получения содержимого определенного URL. С помощью интерфейса nsIIOService можно создавать объекты с интерфейсами nsIURI и nsIURL. Каждый такой объект представляет определенный URL подобно тому, как объект с интерфейсом nsIFile представляет определенный файл. Указанные интерфейсы также предоставляют объекты для управления протоколом, соответствующим данной схеме или URL (protocol handlers). Именно эти объекты лежат в основе реализации каналов. Каждый из этих управляющих объектов поддерживает один или более типов каналов. После того, как в результате выбора пользователя или на основе простой строки получен объект, представляющий URL, с его помощью можно получить объект для управления соответствующим протоколом. В свою очередь, используя этот объект, можно получить объект, представляющий канал. Быстро выполнить все эти действия позволяет вызов метода newChannelFromURI() интерфейса nsIIOService. Имея доступ к объекту-каналу, можно получить с его помощью объект- поток и приступить к обработке данных. Поток необходим для работы с получаемым содержимым. Интерфейс nsIIOService содержит ряд полезных методов, с помощью которых во многих случаях можно обойтись без непосредственного обращения к объекту, управляющему протоколом. При обращении к URL каналы выполняют целый ряд рутинных операций - устанавливают соединение и получают содержимое, преобразуют его, получают и хранят информацию о типе MIME и других параметрах конфигурации. В таблице 16.8 приведены типы каналов, поддерживаемые платформой.
Как видно из таблицы 16.8, большинство каналов соответствуют схемам URL. Все каналы поддерживают базовую функциональность интерфейса nsIChannel, в первую очередь, - методы open() и asyncOpen(). Эти методы возвращают поток или объект - слушатель потока. Другие интерфейсы каналов лишь дополняют эту базовую функциональность с учетом специфики конкретных протоколов. Их не следует рассматривать как принципиально отличные каналы - скорее это расширения базового канала. Несколько интерфейсов, приведенных в таблице, заслуживают особого упоминания. Так, nsIUploadChannel ориентирован на загрузку содержимого с локальной машины на удаленный сервер. Вместо того чтобы возвращать поток, он принимает его при инициализации и направляет данные потока на сервер. Канал nsIResumableChannel используется для загрузки по протоколу FTP, которая может приостанавливаться и возобновляться. Аналогичная функциональность для протокола HTTP в классическом браузере пока не поддерживается. Еще один особый случай - канал для тривиальных "протоколов". Канал может использоваться не только для сложных сетевых протоколов, например FTP и HTTP, но и для простых случаев передачи данных между диском и памятью (чтение файла) или между различными структурами в памяти. Эти простые "протоколы" не подразумевают взаимодействия с URL, и разработчик может управлять ими вручную. Идентификатор контракта input-stream-channel, приведенный в таблице, связан как раз с таким использованием каналов. Пример использования канала для доступа к локальному файлу приведен в листинге 16.6. 16.3.5. Источники данныхИсточники данных обеспечивают поддержку работы с фактами, необходимую для шаблонов XUL и хранилищ данных RDF. Платформа Mozilla содержит значительное количество интерфейсов, а также готовых объектов, которые могут использоваться для связывания источников данных с шаблонами, а также для работы с хранилищами фактов. Очевидный пример - конструкторы по умолчанию, а также представления содержимого, которые используются для заполнения шаблонов. Разработчик приложений может реализовать аналогичную или другую функциональность, используя те же интерфейсы. Концепция источника данных воплощена в интерфейсе nsIRDFDataSource. Этот интерфейс поддерживает все операции, необходимые для работы с фактами RDF. Существует около 20 компонентов XPCOM, реализующих этот интерфейс. В разделе "Практика" приведены многочисленные примеры работы с этими компонентами. В этом разделе мы дадим краткое описание и классификацию основных интерфейсов, используемых для работы с RDF. Отдельные факты могут быть сконструированы из простых объектов XPCOM, основанных на интерфейсах nsIRDFResource и nsIRDFLiteral. Как правило, читать из источника данных можно всегда, а записывать в него - при определенных условиях. Источник данных предоставляет простую функциональность, обеспечивающую добавление, удаление и изменение данных, а также запросы к ним. В отличие от других механизмов обработки данных, источники данных работают с логическими объектами (фактами), а не с потоками байтов или символов. Полезные интерфейсы XPCOM для работы с источниками данных можно разделить на три группы: Вспомогательные средства и утилиты. Они необходимы для выполнения базовых операций. Дополнительные расширения. Некоторые интерфейсы расширяют базовую функциональность интерфейса nsIRDFDataSource для различных целей. Поддержка содержимого. Существуют специализированные источники данных для содержимого определенного типа. Эти источники подразделяются на обычные, в которых данные берутся из файлов RDF, и внутренние, в которых источником фактов являются структуры данных платформы Mozilla. Выбрав неверный источник данных из последней категории, можно напрасно потратить часы, дни или даже недели на отладку программы. Поэтому важно представлять себе поддерживаемые типы содержимого и соответствующие источники данных. Обратите внимание, что в именах методов интерфейса nsIRDFDataSource слово source (источник) не относится к источникам данных. Source и target (цель) в этих именах означают субъект и объект факта соответственно - см., например, метод GetSource(). 16.3.5.1. Объекты-фабрики и вспомогательные объектыПри использовании шаблонов XUL доступ к объектам, имеющим интерфейс nsIRDFDataSource, обеспечивают объекты DOM этих шаблонов. В отсутствие шаблонов для непосредственного доступа к источникам данных из скрипта необходимо с самого начала создать объекты-фабрики. Компоненты, используемые для непосредственной работы с RDF, приведены в таблице 16.9. Нотация {arg} означает, что может быть несколько вариантов данного параметра. Простейший способ увидеть их все - просмотреть содержимое массива window.Components.classes. Компоненты, приведенные в таблице, можно разделить на следующие четыре группы.
Первая группа из одного интерфейса представляет собой отправную точку для работы с RDF из скрипта. Интерфейс nsIRDFService позволяет создавать объекты nsIRDFDataSource на основе URI, включая URL, имеющие схему rdf:. Соответствующие URL перечислены в таблице 16.11. Объект, представляющий подлежащее, дополнение или предикат факта, также может быть создан при помощи этого интерфейса на основе строки JavaScript. Для получения доступа к объекту, поддерживающему интерфейс nsIRDFService, используется метод getService(), а не createInstance(). Вторая группа компонентов, приведенных в таблице, предоставляет интерфейсы-фабрики для создания контейнеров RDF и работы с ними. Второй и третий компоненты в таблице обеспечивают простой способ создания структур данных, содержащих объекты, которые представляют ресурсы RDF. К этой же группе относятся компоненты resource-factory. Элементы фактов, создаваемые при помощи этих компонентов, содержат дополнительную информацию. В зависимости от значения, присвоенного параметру name, такой объект, помимо обычного субъекта, предиката или объекта факта, может содержать дополнительные данные о записях адресной книги, сообщениях электронной почты или конференций, а также о файлах. Эти данные и связанные с ними методы сопровождают ресурс RDF в процессе его обработки в хранилище фактов. При этом из скриптов JavaScript доступны только компоненты, относящиеся к подсистеме электронной почты. При обращении к этим компонентам параметр name может принимать следующие значения: imap mailbox news moz-abdirectory moz-abldapdirectory moz-abmdbdirectory moz-aboutlookdirectory Третья группа компонентов предназначена для непосредственного синтаксического анализа документов RDF. Обычным приложениям редко приходится работать на столь низком уровне. Обратное действие, создание документа RDF на основе хранилища фактов, или сериализация, используется в том случае, если приложению необходимо сохранять данные в перерыве между сеансами работы. Ни один из этих интерфейсов не используется для работы с отдельными фактами. Наконец, применение последнего интерфейса в таблице 16.9, nsIRDFDelegateFactory, требует глубокого понимания архитектуры платформы. Оно позволяет привязать какое-либо действие к созданию или уничтожению ресурса, используемого в факте. Такой объект-делегат представляет собой наблюдатель для отдельного ресурса. Работа с этим интерфейсом на страницах нашей книги не рассматривается. 16.3.5.2. Расширенная функциональность источников данных.Mozilla предоставляет ряд возможностей для расширения функциональности источников данных. Расширение выражается скорее в большей гибкости источников, чем в доступе к каким-либо дополнительным данным. Эти возможности доступны при помощи ряда интерфейсов XPCOM, которые описаны в таблице 16.10.
Система шаблонов XUL не только позволяет использовать составные источники данных, но и поддерживает список аргументов, переданных атрибуту XUL источников данных. Фактически, составной источник данных представляет собой контейнер, содержащий другие источники данных. Он также реализует интерфейс nsIRDFDataSource. Каждый метод этого интерфейса просматривает отдельные источники данных, содержащиеся в контейнере, и при необходимости поочередно вызывает соответствующие методы каждого из них. Источники данных, находящиеся в памяти, лежат в основе нескольких более сложных источников. Создание источника данных в памяти представляет собой естественную отправную точку в ситуации, когда содержание хранилища фактов не берется откуда-либо в готовом виде, а должно конструироваться динамически. Очистка такого источника от данных представляет собой его возвращение к исходному пустому состоянию. Отключение передачи событий, представляющих изменение фактов, несколько улучшает производительность источника. Интерфейс nsIRDFRemoteDataSource предоставляет возможность сохранить текущее состояние хранилища фактов в том месте, откуда были взяты исходные данные, или загрузить данные оттуда в хранилище фактов. Как правило, это место представляет собой файл RDF или его эквивалент. Файл может быть локальным или удаленным, но в любом случае доступна лишь крайне ограниченная функциональность. Сохранение реализовано с помощью метода Flush(), а загрузка - с помощью метода Refresh(). Flush(), поддерживается только для URL типа file:,а Refresh() - для URL типов file: и http:. 16.3.5.3. Типы содержимого.Не все источники данных одинаковы. Они могут отличаться характером содержимого, а также способами доступа к нему. Эти различия - основная причина сложностей при использовании источников данных. С точки зрения разработчика приложений не всегда очевидно, какие именно факты доступны при помощи тех или иных источников данных, и каким образом их можно получить. Все источники данных основаны на компонентах XPCOM, имена которых имеют следующий вид: @mozilla.org/rdf/datasource;1?name={arg}
Допустимые значения для {arg} приведены в крайнем левом столбце таблицы 16.12. Характер содержимого, которое доступно приложению при помощи источника данных, очевиден только в случае обычных файлов RDF, просматривая которые, разработчик может непосредственно получить представление о характере исходных файлов. Этого нельзя сделать с внутренними источниками данных, с содержимым которых можно познакомиться лишь следующими способами:
Внутренние источники данных, содержащие информацию о закладках, истории просмотра страниц, поиске, а также некоторых типах внутренних данных, используют файлы в папке профиля пользователя. Как правило, эти файлы не являются документами RDF. Такая "анонимность" содержимого представляет собой серьезную проблему для шаблонов XUL и скриптов, которые пытаются работать с внутренними источниками данных. В обоих случаях необходимо знать структуру данных заранее. К счастью, работа с внутренними источниками данных необходима лишь для узкого круга задач. В разделе "Отладка" этой главы приведены примеры кода, позволяющего просматривать содержимое источников данных. В таблице 16.11 приведены субъекты верхнего уровня, а также часто используемые предикаты для большинства внутренних источников данных. Специальное значение rdf:null означает отсутствие источника данных, а не пустой источник. Помимо специфики содержимого, для многих источников данных Mozilla характерна ограниченная функциональность. Это означает, что, даже если вам известна структура содержимого источника данных, функциональность источника может оказаться недостаточной для того, чтобы получить доступ к этому содержимому. В таких случаях, хотя соответствующий объект XPCOM формально поддерживает интерфейс nsIRDFDataSource, многие методы этого интерфейса не выполняют никаких действий, возвращая исключение или сообщение об ошибке. Работа над этими компонентами - источниками данных - еще не завершена. Степень поддержки интерфейса nsIRDFDataSource для каждого из существующих источников данных представлена в таблице 16.12. Данные таблицы соответствуют версии Mozilla 1.4 и отражают лишь принципиальное наличие той или иной функции. Перед работой с некоторыми редко используемыми источниками данных могут понадобиться сложные подготовительные действия, которые не рассматриваются в этом курсе. Источники данных, не имеющие URI с префиксом rdf:, не могут быть подключены к шаблону XUL при помощи атрибутов XML. Однако они могут быть подключены к шаблону при помощи скрипта. Источники данных, которые не зарегистрированы в XPCOM при параметрах сборки по умолчанию, не могут быть использованы ни из XUL, ни из XML. Составной источник данных composite-datasource может быть использован лишь в том случае, если может использоваться хотя бы один из исходных источников. В большинстве случаев рекомендуется непосредственно работать с отдельными источниками данных, не объединяя их в составной источник.
16.4. Web-скриптыWeb-браузеры функционируют в среде, которая отличается от среды выполнения традиционных программ. В WWW нет таких сущностей как файл или имя файла. Вместо них имеются указатели ресурсов (URL), а также документы, представляющие эти ресурсы. Часто такие документы имеют сложную структуру и основаны на языке XML. Такая среда требует иного подхода к написанию скриптов, нежели описанный в разделах "Файлы и папки" и "Потоки". Кроме того, браузеры работают с формирующимся стеком Web-протоколов, который можно условно назвать стеком XML. В основе этого стека лежит протокол HTTP, поверх которого реализуются различные прикладные протоколы. Стек протоколов XML позволяет организовывать транзакции, ориентированные на работу с данными, а не просто запрашивать и получать отдельные документы, как это делается при просмотре Web-страниц. Этот еще не вполне устоявшийся стек протоколов определяется рядом стандартов и проектов стандартов. Ниже перечислены важнейшие из них, начиная с самого низкого уровня.
Вряд ли полномасштабная поддержка всех перечисленных стандартов будет когда-либо реализована в рамках платформы Mozilla, поскольку некоторые из них ориентированы на взаимодействие между корпоративными приложениями, а не между приложением и пользователем. Область применения стека Web-протоколов выходит далеко за рамки обычных задач клиентского ПО, например просмотра Web-страниц или получения электронной почты. Вместо каналов, которые являются стандартным средством работы с URL на платформе Mozilla, при работе с этими протоколами используются специализированные интерфейсы. Приложение на платформе Mozilla может вообще не иметь собственного графического интерфейса. Например, оно может быть основано на инструменте xpcshell. Однако и в этом случае приложение может использовать развитые средства для работы с XML, входящие в состав платформы. Таким образом можно создавать серверы, реализующие некоторые идеи протоколов для бизнес-процессов. Например, такой сервер может перенаправлять получаемые документы XML в зависимости от их содержания. 16.4.1. URI, URL и URNФормат URI и его специализированных разновидностей - URL и URN - определен документом RFC 2396. Предполагается, что это переносимые идентификаторы ресурсов, свободные от проблем, характерных для путей и имен файлов. В то же время URI (особенно URL) часто бывают громоздкими, что приводит к ошибкам пользователей при их наборе, а также частому использованию сокращенных форм URL. Платформа Mozilla позволяет представить URI в виде простой строки JavaScript без потери переносимости. Однако для использования с интерфейсами XPIDL эта строка должна быть преобразована в объект. Наиболее общему объекту соответствует следующая пара XPCOM: @mozilla.org/network/simple-uri;1 nsIURI Для URL существует специализированный объект, который поддерживает типичные схемы URL, например http: and ftp:. Соответствующая пара XPCOM широко применяется при разработке на платформе Mozilla: @mozilla.org/network/standard-url;1 nsIURL Этот компонент также поддерживает nsIURI. Вообще, большинство компонентов, идентификатор контракта которых содержит подстроку uri или url, поддерживают оба этих интерфейса или один из них. Часто требуется проверять корректность URL, введенного пользователем. В рамках платформы предусмотрено несколько инструментов проверки и исправления синтаксиса. Следующая пара XPCOM может использоваться при попытке исправить некорректный URL, введенный пользователем: @mozilla.org/docshell/urifixup;1 nsIURIFixup Этот интерфейс содержит метод createFixupURI(), который может применяться для работы с ключевыми словами, введенными в строку адреса браузера, а также сокращенными формами URL, например www.test.com или даже test.com вместо http://www.test.com. Соответствующий компонент docshell доступен как элемент объектной модели приложения в окне браузера Mozilla (подробнее об этом рассказано в разделе "<iframe>" главе 10 "Окна и панели"). Второй способ исправления синтаксиса URL связан с использованием следующей пары XPCOM: @mozilla.org/network/url-parser;1?auth=maybe nsIURLParser Этот интерфейс позволяет выполнить разбор URL в соответствии с RFC 2396, причем в процессе могут быть исправлены многие типы характерных ошибок. Параметру, определяющему конкретный тип компонента, могут быть присвоены значения yes и no. Результатом будет использование другого, несколько отличающегося алгоритма разбора URL. Наконец, можно задействовать метод resolve() базового интерфейса nsIURI. Если передать этому методу сокращенный (относительный) URI, будет возвращен полный (абсолютный) вариант, основанный на текущем URI самого объекта. В любом случае, окончательной проверкой правильности URL является то, удается ли получить с его помощью нужный ресурс. Специализированного объекта XPCOM, предназначенного для URN, не существует. 16.4.2. Загрузка файловЧтобы загрузить с удаленного сервера файл или документ, можно создать канал для нужного URI, а затем использовать полученный поток. Этот подход описан в разделе "Обработка содержимого: основные концепции". Однако существует и более простой способ загрузки - использование следующей пары XPCOM: @mozilla.org/embedding/browser/nsWebBrowserPersist;1 nsIWebBrowserPersist В качестве параметров этот интерфейс принимает URI или интерфейс Document DOM 1, а также объект nsILocalFile. С его помощью можно загрузить документ и сохранить его в виде файла при помощи единственного вызова метода. Чтобы организовать асинхронную загрузку, во время которой могут выполняться другие задачи, нужно создать объект - слушатель или наблюдатель содержимого - на чистом JavaScript. В документации к большинству интерфейсов, например nsIChannel, описано, какие слушатели и наблюдатели поддерживаются данным интерфейсом. При загрузке очередной порции документа, которая будет передана слушателю или наблюдателю, можно обработать ее, сохранить или просто проигнорировать. Наиболее распространенный способ создания объекта для обработки содержимого по частям - реализовать интерфейс nsIWebProgressListener. Любой объект, поддерживающий интерфейс nsIWebProgress, может зарегистрировать один или несколько таких слушателей, а многие другие интерфейсы принимают такой объект-слушатель в качестве аргумента инициализации. Существуют готовые объекты XPCOM, поддерживающие этот интерфейс, поэтому во многих случаях реализовывать его самостоятельно не понадобится. Отслеживать состояние процесса асинхронной загрузки можно по- разному. В принципе, обработка поступающего содержимого и получение информации о состоянии процесса представляют собой две независимые задачи. Наиболее простой способ отслеживать состояние загрузки - доработать обычный слушатель содержимого так, чтобы он при получении очередной порции данных определял, какая часть содержимого уже загружена. Такой слушатель не получает событий, связанных с завершением загрузки, и других управляющих событий; он лишь отслеживает состояние процесса загрузки. Более удобный способ - с помощью чистого JavaScript создать объект, поддерживающий интерфейс nsIProgressEventSink, и передать его объекту, ответственному за загрузку. Такой объект-приемник (слушатель событий) получает информацию обо всех изменениях в состоянии процесса загрузки. Еще один вариант - создать на чистом JavaScript объект с интерфейсом nsIRequestObserver, и передать его объекту канала или транспорта. Такой наблюдатель получает только уведомления о начале и окончании загрузки, но не о ее промежуточном состоянии, приостановке или прерывании. Более сложный способ отслеживания процесса загрузки предполагает использование объектов XPCOM, связанных с Менеджером загрузок Mozilla. Эти объекты могут применяться независимо от диалогового окна менеджера загрузок или вместе с ним. В последнем случае разработчик должен самостоятельно обеспечить взаимодействие объектов XPCOM с диалоговым окном. Независимо от использования диалогового окна этот способ может применяться лишь при загрузке файлов для последующего сохранения на диске. Отправной точкой для использования этого способа является следующая пара XPCOM: @mozilla.org/download-manager;1 nsIDownloadManager Единственный объект, созданный таким образом, одновременно управляет всеми текущими загрузками. Метод addDownload() этого объекта используется для создания нового объекта, поддерживающего интерфейс nsIDownload, для каждой загрузки. Каждый такой объект, соответствующий отдельной загрузке, содержит всю конфигурационную информацию о ней и уведомляет Менеджер загрузок о ходе процесса. Конфигурационная информация передается объекту в момент его создания в виде аргументов метода addDownload(). В частности, последний аргумент, имеющий интерфейс nsIWebBrowserPersist, содержит информацию о том, каким образом должен быть сохранен полученный файл. Если этот аргумент существует, объект загрузки автоматически уведомляет Менеджер загрузок о состоянии процесса, а в случае отмены или прерывания загрузки Менеджер загрузок самостоятельно выполняет очистку памяти. Если же последнего аргумента не существует, приложение должно выполнить очистку памяти самостоятельно. Чтобы своевременно узнать о необходимости очистки, можно создать наблюдатели для каждого объекта загрузки. Mozilla также поддерживает группы загрузки. Это вариант интерфейса nsIRequest, который позволяет одновременно работать с несколькими URL. Группы загрузки могут использоваться, если необходимо получать информацию о процессе загрузки нескольких файлов. 16.4.3. Файлы и типы MIMEТип MIME для файла, ресурса с указанным URI или расширения файла может быть получен с помощью следующей пары XPCOM, представляющей сервисный объект-синглетон: @mozilla.org/mime;1 nsIMIMEService Прежде всего, этот объект обращается к информации о типах MIME, хранящейся в составе профиля пользователя. Если нужная информация не может быть получена таким образом, используются данные операционной системы или рабочей среды. В системах UNIX используются настройки среды GNOME, а не утилита file(1). Метод launch() интерфейса nsILocalFile позволяет запустить исполняемый файл или открыть файл данных при помощи соответствующего приложения. Для вызова метода launch() нет необходимости знать что-либо о типе файла. 16.4.4. Отправка форм и загрузка файлов на серверДля отправки форм можно использовать объект AOM (объектной модели приложения) XMLHttpRequest. Работа с ним описана в разделе "Отправка форм" главе 7 "Формы и меню". Он основан на следующей паре XPCOM: @mozilla.org/xmlextras/xmlhttprequest;1 nsIJSXMLHttpRequest Загрузка документов на сервер столь же проста. Следуйте рекомендациям раздела "Каналы" этой главы и укажите адрес для загрузки, используя интерфейс nsIIOService. В качестве адреса для загрузки может быть указана программа, выполняемая на стороне сервера, в случае применения запроса HTTP POST или каталог FTP в случае использования протокола FTP. Создав канал, следует получить интерфейс nsIUploadChannel при помощи метода QueryInterface(), а затем передать этому интерфейсу поток ввода с содержимым файла, который должен быть загружен. Чтобы отправить содержимое, нужно снова получить интерфейс nsIChannel, и вызвать метод open() или asyncOpen(), как и при работе с любым объектом канала. 16.4.5. Объекты стека Web-протоколовПротокол HTTP, лежащий в основе стека Web-протоколов, широко применяется в Mozilla. Скрипты могут работать с ним различными способами, включая непосредственное использование объекта AOM XMLHttpRequest. Работа с прочими протоколами, поддерживаемыми Mozilla, требует применения специализированных объектов. Документация по использованию Web-протоколов в Mozilla доступна по адресу www.mozilla.org/xmlextras/. XML-RPC представляет собой простейшую надстройку над HTTP. Следующая пара XPCOM используется для формирования фрагмента XML, содержащего запрос RPC, его синхронную или асинхронную передачу по указанному URL с помощью HTTP, а также возвращение результатов или сообщений об ошибках: @mozilla.org/xml-rpc/client;1 nsIXmlRpcClient Сообщения об ошибках возвращаются в виде объектов с интерфейсом nsIXmlRpcFault. При использовании традиционного RPC применяется утилита rpcgen(1) или другие аналогичные инструменты, которые генерируют код на языке C для удаленного вызова процедуры. Этот код:
Особенность использования XML-RPC на платформе Mozilla состоит в том, что JavaScript является интерпретируемым языком, а код платформы, работающий с удаленным вызовом процедур, как правило, уже скомпилирован. Поэтому порядок работы с RPC отличается от традиционного подхода. Объект nsIXmlRpcClient упаковывает вызовы XML-RPC в переносимый XML, но передачу вызова и получение результата он делегирует объекту канала. Поэтому для управления задержками или получения информации о них необходимо обращаться именно к объекту канала. Задача преобразования типов JavaScript в переносимые типы XML-RPC оставлена разработчику приложения. Объект nsIXmlRpcClient предоставляет ряд методов-фабрик для создания типов XML-RPC, однако разработчик должен воспользоваться этими методами самостоятельно. Наконец, этот объект реализован на JavaScript и постоянно обращается к объекту window.Components для разрешения имен, что ограничивает его производительность. Протокол SOAP, разработанный как замена XML-RPC, постепенно приобретает все большую популярность. SOAP - сложная технология, которая заслуживает отдельной книги. Здесь представлены лишь минимально необходимые сведения для работы с этим протоколом. Полезным источником информации являются спецификации SOAP и XML-P, принятые Консорциумом WWW. В будущем технология SOAP будет официально называться XML-P (P означает "протокол"), хотя популярное сокращение SOAP вряд ли выйдет из употребления. Вызов SOAP представляет собой сообщение-запрос, за которым следует сообщение-ответ, поэтому HTTP является естественным транспортным протоколом для SOAP. Оба сообщения имеют формат XML. Оба сообщения состоят из тега-контейнера, содержащего один необязательный тег-заголовок и один обязательный тег, представляющий тело запроса. Эти теги описаны в спецификации SOAP. Тело запроса содержит фрагмент документа, состоящего из других тегов. Они определяются разработчиком приложения, который должен создать для них формальное определение (схему) или использовать существующую схему. Эти теги представляют отправляемые и возвращаемые данные. Для того чтобы разработчик мог создать сообщение SOAP, необходимы объекты, выполняющие следующие задачи:
Ниже перечислены пары XPCOM для создания объектов, соответствующих каждой из задач:
Помимо этих объектов, обеспечивающих базовую функциональность для работы с SOAP, существует множество вспомогательных и второстепенных интерфейсов. Наконец, для работы с протоколом необходим сервер, способный принимать запросы SOAP по протоколу HTTP и отвечать на них. Интерфейс nsISOAPMessage также доступен в форме объекта AOM SOAPCall, создать который очень просто: var soap_call = new SOAPCall(); Аналогичным образом интерфейсу nsISOAPParameter соответствует объект AOM SOAPParameter. Эти два объекта позволяют выполнять простые вызовы SOAP, не прибегая к сложным подготовительным операциям. Широко известен сервис SOAP, позволяющий делать запросы к поисковой машине Google. Этот сервис может использоваться для отладки SOAP-клиентов на платформе Mozilla. Описание его программного интерфейса доступно по адресу www.google.com/apis/. Однако отладка сетевых клиентов может быть гораздо более эффективной в том случае, когда разработчик контролирует не только клиент, но и сервер. Подходящее решение входит в состав исходного кода платформы. Фрагмент кода, доступный по следующему адресу, может использоваться для изучения SOAP и отладки клиентов: http://lxr.mozilla.org/seamonkey/source/extensions/xmlextras/tests/ В этом каталоге находятся три небольших программы на языке Perl, которые могут получать SOAP-запросы и отвечать на них. Для этого их нужно установить на Web-сервер как CGI-скрипты. Скрипт echo.cgi реализует операцию "ping", которую, по соглашению, должен поддерживать всякий SOAP-сервер. Два других скрипта возвращают сообщение об успешном выполнении запроса и сообщение об ошибке соответственно. Сообщение об успешном выполнении включает также возвращаемые данные. Поддержка SOAP в Mozilla достаточна для того, чтобы платформа могла выступать в качестве не только клиента, но и SOAP-сервера. Однако в настоящее время для этого необходимо, чтобы все клиенты использовали одно и то же транспортное соединение (один сокет или дескриптор файла). Поэтому пока на основе Mozilla невозможно реализовать сервер, который мог бы принимать SOAP-запросы с любого узла Internet. Последний протокол стека Web-протоколов, поддерживаемый Mozilla, - WSDL, язык описания Web-сервисов. Этот протокол объединяет группу отдельных вызовов SOAP в единый документ-определение. В некотором смысле такое определение аналогично файлу IDL в архитектуре CORBA или файлу XPIDL в Mozilla. Создание определений WSDL является обязанностью разработчика приложения. Поддержка WSDL появилась в Mozilla незадолго до написания этой книги, и интерфейсы еще не успели устояться. Наилучшим источником актуальной информации о поддержке WSDL является следующий документ, который содержит XPIDL-определения интерфейсов для работы с WSDL: http://lxr.mozilla.org/seamonkey/source/extensions/xmlextras/wsdl/ Чтобы узнать идентификаторы контрактов (Contract ID) компонентов, реализующих эти интерфейсы, следует просмотреть заголовочные файлы (с расширением .h) в этом каталоге или использовать утилиту для просмотра компонентов (Component Viewer). В последнем случае нужно указать следующий префикс для Contract ID: @mozilla.org/xmlextras/wsdl/ Полная поддержка WSDL реализована в версиях Mozilla начиная с 1.4. 16.4.6. Пакетная обработка XSLTДля обращения к системе обработки XSLT из скриптов JavaScript используется следующая пара XPCOM: @mozilla.org/document-transformer;1?type=text/xsl nsIXSLTProcessor Объект с таким интерфейсом принимает в качестве аргументов два дерева или поддерева DOM. Первое из них образовано командами XSLT, а второе представляет собой документ, который должен быть преобразован. Результатом обработки является третье дерево или поддерево. Кроме того, объекту могут быть переданы различные параметры преобразования. Система не может преобразовывать документы "на месте" - чтобы работать с полученным документом, его необходимо присоединить к существующей иерархии DOM. 16.5. Конфигурация платформыНекоторым скриптам необходимо получать информацию о состоянии самой платформы Mozilla или изменять это состояние. Для этого скрипты должны получить доступ к различным аспектам внутреннего состояния платформы при помощи интерфейсов XPCOM. В этом разделе обсуждаются управление кэшем, каталог файловой системы, настройки, защита, а также профили пользователя. 16.5.1. Управление кэшемПредполагается, что кэш браузера Mozilla прозрачен для любых действий по получению Web-документов, однако при необходимости с ним можно взаимодействовать. Кэш используется для любых запросов к URL, выполняемых платформой, если в явном виде не было указано избегать использования кэша или отключить его. Доступ к кэшу на низком уровне осуществляется при помощи следующей пары XPCOM: @mozilla.org/network/cache-service;1 nsICacheService Объект, полученный таким образом, должен иметь доступ к константам, предоставляемым интерфейсом nsICache. Техника работы с кэшем на низком уровне является неожиданно сложной в силу используемой модели блокировки, которая допускает несколько одновременных сеансов чтения, но лишь один сеанс записи. Это означает, что попытка работы с кэшем на низком уровне может оказаться неудачной по причине конфликта из-за доступа к ресурсам. Разработчику приложений проще не иметь дела с этими тонкостями и использовать сервисы более высокого уровня, например транспорты и каналы, которые взаимодействуют с кэшем автоматически. Однако указанный интерфейс предоставляет и ряд методов, полезных для разработчика приложений, например evictEntries(), который может использоваться для очистки кэша. Очень простое применение кэша - упреждающая загрузка документов. Такая загрузка подразумевает помещение документа в кэш без обязательного отображения или какой-либо обработки. Упреждающая загрузка может выполняться лишь для URL с префиксом http:, которые не являются запросами GET (не имеют части вида ?param=). Для упреждающей загрузки используется следующая пара XPCOM: @mozilla.org/prefetch-service;1 nsIPrefetchService Аналогичная функциональность с возможностью более детального управления доступна при помощи интерфейса nsIRequest, который является основой для каналов и транспортов. Свойство loadFlags, которое может устанавливаться для каждого URI по отдельности, определяет, каким образом полученный документ взаимодействует с кэшем. 16.5.2. Каталог файловой системыПлатформа Mozilla поддерживает службу каталогов, которая позволяет скриптам получать доступ к хорошо известным файлам и папкам. Каталоги (службы каталогов) Mozilla подобны телефонной книге - они позволяют получить информацию об объекте или ресурсе по его имени. В принципе, каталоги не привязаны к концепции файловой системы - в составе платформы существует целый ряд различных каталогов. Некоторые из них обеспечивают доступ к удаленным ресурсам, другие, например Адресная книга Mozilla, - к данным, хранящимся на локальном диске, третьи - к различным структурам и объектам платформы, находящимся в памяти. Один из этих каталогов содержит пути к файлам и папкам, важным для работы платформы. Это единственная служба каталогов, которая обсуждается далее в данном разделе. Разработчику приложений целесообразно использовать эту службу каталогов, если приложение должно задействовать те же файлы и папки, что и сама платформа Mozilla. Это позволяет обеспечить надлежащую интеграцию приложения с платформой и до некоторой степени предотвратить проблемы с переносимостью. Эта служба каталогов, называемая каталогом файловой системы, доступна при помощи следующей пары XPCOM: @mozilla.org/file/directory_service;1 nsIDirectoryService Обратите внимание, что в названии directory_service использовано подчеркивание, а не дефис. Этот каталог содержит пути ко всем важным файлам и папкам, о которых должны знать приложения и их разработчики. Поэтому каталог файловой системы является принципиально важным для приложений на платформе Mozilla. После того, как объект, представляющий файл или папку, получен с помощью каталога, с ним можно обращаться так же, как с любым другим файлом или папкой. Интерфейс nsIDirectoryService не слишком полезен сам по себе. Его роль состоит в управлении объектами-источниками (providers). Источник представляет собой объект, который предоставляет службе каталогов часть ее содержимого. В обычной ситуации объект службы каталогов вообще не имеет собственного содержимого. Вместо этого в нем зарегистрированы ноль или более источников, содержимое которых доступно при помощи службы каталогов. Каждый источник поддерживает интерфейс nsIDirectoryServiceProvider. Когда скрипт обращается с запросом к службе каталогов, объект службы просматривает все зарегистрированные источники в поисках запрошенных данных. В такой ситуации источники полностью скрыты от скрипта, обращающегося к каталогу. Помимо источников, служба каталогов Mozilla использует и другие интерфейсы. Так, nsIProperties - стандартный интерфейс, позволяющий получить по имени объекта данные о нем, хранящиеся в каталоге. Нужное имя (фактически, псевдоним искомого объекта) передается службе каталогов при помощи метода get() интерфейса nsIProperties. В результате будет возвращен любой объект (запись в каталоге), имя которого соответствует переданному псевдониму. Как и другие службы каталогов Mozilla, каталог файловой системы поддерживает этот интерфейс. Пример его использования приведен в листинге 16.7: var Cc = Components.classes;
var Ci = Components.interfaces;
var dir = Cc["@mozilla.org/file/directory_service;1"];
dir = dir.getService(Ci.nsIDirectoryService); // Инициализация
// Поместите сюда обращения к dir.registerProvider(provider_object)
var dir_props = dir.QueryInterface(Ci.nsIProperties);
var file = dir_props.get("myalias", Ci.nsIFile);
if (file == null )
alert("Нет такого ресурса");
Листинг
16.7.
Получение ресурса из каталога файловой системы с использованием псевдонимаЭтот код создает объект службы каталогов, не добавляя к нему никаких источников, затем получает интерфейс nsIProperties и запрашивает из каталога данные для псевдонима "myalias". Поскольку каталог файловой системы XPCOM содержит информацию о файлах и папках, ожидается, что будет возвращен объект, поддерживающий интерфейс nsIFile. В данном примере объект не будет найден в каталоге, и система выдаст предупреждение (последняя строка кода). Это произойдет по двум причинам. Во-первых, строка "myalias" в рамках платформы Mozilla не определена в качестве псевдонима известных файла или папки. Это легко исправить - достаточно использовать какой-либо известный псевдоним. Однако есть и более серьезная проблема - к объекту службы каталогов не было добавлено ни одного источника. Поэтому мы могли бы ожидать, что в данном коде не будут распознаваться никакие псевдонимы. Однако это не так. На практике, к объекту каталога файловой системы всегда подключено, как минимум, два источника.
Дополнительную сложность работе со службой каталогов придает тот факт, что объект, который представляет каталог файловой системы, одновременно реализует интерфейс источника. Этот источник определяется следующей парой XPCOM: @mozilla.org/file/directory_service;1 nsIDirectoryServiceProvider Такой источник представляет собой дополнение к трем, перечисленным выше. Его редко регистрируют в каких-либо службах каталогов. Вместо этого к нему обращаются непосредственно из скриптов - в отличие от остальных источников, он не является скрытым. Этот источник добавляет псевдонимы, важные для системы XPCOM, которая составляет основу платформы Mozilla. Эти псевдонимы представляют файлы и папки, необходимые для задач самого низкого уровня; местонахождение многих из них зависит от операционной системы. Пример непосредственной работы с этим источником приведен в листинге 16.8. var Cc = Components.classes;
var Ci = Components.interfaces;
var prov = Cc["@mozilla.org/file/directory_service;1"];
prov = prov.getService(Ci.nsIDirectoryServiceProvider);
var result = {}; // пустой объект
var file = prov.getFile("alias", result);
if ( file == null ) alert("Нет такого ресурса");
// alert(result.value)
Листинг
16.8.
Получение файлового ресурса из источника с использованием псевдонимаПоскольку обычно источники управляются объектом, представляющим службу каталогов, аргументы метода getFile() приспособлены для использования с таким объектом. Второй аргумент этого метода, пустой объект, позволяет источнику передать службе каталогов определенную информацию о состоянии ресурса. Как правило, обычному скрипту эта информация не нужна, если только он не реализует собственную службу каталогов. Дальнейшую информацию по этому вопросу можно получить в файле XPIDL для интерфейса nsIDirectoryServiceProvider. В оставшейся части раздела перечисляются псевдонимы, поддерживаемые названными источниками. Мы начнем с последнего, специализированного источника. 16.5.2.1. Псевдонимы файловой системы XPCOMЭти псевдонимы поддерживаются специализированным источником, встроенным в объект службы каталогов. Как правило, с этим источником работают непосредственно из скриптов. Псевдонимы перечислены в таблицах 16.13 - 16.16. Таблица 16.13 относится ко всем платформам.
В таблице 16.14 перечислены псевдонимы, которые поддерживаются только в системе Microsoft Windows. Константы CSIDL, приведенные в таблице, являются частью программного интерфейса (API) Microsoft Windows и используются в таких функциях Windows, как, например, SHGetFolderPath(). Каждый псевдоним соответствует известной папке. Полное описание этих констант приведено в документе по адресу: http://msdn.microsoft.com/library/en-us/shellcc/platform/shell/reference/enums/csidl.asp
Нужно иметь в виду, что использование псевдонимов с префиксом Cm в однопользовательских версиях Windows, например Microsoft Windows 98, приводит к возникновению исключительной ситуации. В таблице 16.15 приведены псевдонимы, поддерживаемые только на платформе Macintosh. Прочие псевдонимы перечислены в таблице 16.16. Псевдонимы, поддерживаемые в таких системах, как OS/2, BeOS, OpenVMS и т.д., в этой книге не приводятся.
16.5.2.2. Псевдонимы файловой системы прикладного уровняЭти псевдонимы предоставляются источником, который подключается к службе каталогов в момент ее создания. Этот источник всегда доступен, предоставляемые им псевдонимы поддерживаются на всех платформах. Платформа Mozilla не сводится к системе XPCOM. Последняя образует ядро платформы, поверх которого реализовано множество компонентов и инфраструктура, также составляющие часть платформы. В состав платформы входят папки, в которые установлены браузеры и другие продукты, система chrome, кэши, реестры и т.д. Их местонахождение определяется псевдонимами прикладного уровня, которые перечислены в таблице 16.17.
Псевдоним DefProtRt возвращает следующие значения в зависимости от платформы:
16.5.2.3 Псевдонимы файловой системы уровня профиля пользователяЭти псевдонимы предоставляются источником, который подключается к службе каталогов в момент запуска платформы. В полном дистрибутиве платформы (который не был специально "облегчен" с какой-либо целью, например, для использования в мобильных устройствах) они доступны всегда. Псевдонимы перечислены в таблице 16.18; они одинаковы для всех платформ.
16.5.2.3 Псевдонимы файловой системы, относящиеся к модулямПсевдонимы, относящиеся к модулям (plugins), предоставляются источником, который подключается к службе каталогов в тот момент, когда возникает необходимость в обращении к модулям. Эти псевдонимы используются для получения файла, реализующего модуль. Они доступны только в системе Microsoft Windows. Прочие источники службы каталогов просто транслируют псевдоним в путь к соответствующим файлу или папке. Данный источник тоже возвращает файловый объект, но лишь после выполнения некоторых проверок. Так, он проверяет, достаточна ли версия модуля, установленного в системе, для отображения содержимого и активизирован ли модуль в настройках платформы. Файл модуля возвращается лишь при выполнении этих условий. Для сравнения версий используется формат, описанный в главе 17 "Развертывание". Известные псевдонимы представлены в таблице 16.19.
16.5.3. НастройкиСкрипты позволяют изменять текущие настройки профиля пользователя, текущие глобальные настройки, а также файлы настроек, хранящиеся на локальном компьютере. Для этого используется следующая пара XPCOM: @mozilla.org/preferences-service;1 nsIPrefService По умолчанию скрипты, не установленные в chrome, не могут изменять настроек пользователя или платформы. Чтобы предоставить им такую возможность, необходимо отключить стандартные ограничения защиты. В версиях Mozilla начиная с 1.3 пользователь может изменять любые настройки в окне браузера, введя в строке адреса следующий URL: about:config. 16.5.4. ЗащитаВ этом разделе рассказано, как реализована система защиты информации на платформе Mozilla. Поскольку защита вообще представляет собой обширную тему, мы расскажем только о тех ограничениях защиты, которые непосредственно влияют на работу скриптов. В браузерах Netscape 4.x такого рода проверки выполнялись с помощью подсистемы Java. Платформа Mozilla содержит собственную подсистему защиты, которая обеспечивает необходимые проверки и ограничения, не используя Java. Фрагмент кода Mozilla может находиться в одном из четырех режимов защиты: Web Safe (защищенный для работы в Web), Trusted (режим доверия), Certified (защита на основе сертификатов) или Domain Policied (политика защиты на основе доменов). На практике эти режимы относятся, прежде всего, к скриптам JavaScript, однако они применимы и к любым загружаемым документам, включая HTML-документы. Поддержка протокола WDSL, недавно реализованная в составе платформы, привела к добавлению дополнительных мер защиты. Они подразумевают дополнительную проверку при первом обращении к удаленному Web-сервису - платформа должна запросить разрешение на его использование. Это делается с целью защиты сервера, предоставляющего Web-сервис, а не локальной платформы, которая обращается к нему. В момент подготовки книги к печати предполагалось, что на стороне клиента для такой проверки будет использоваться интерфейс nsIWebScriptsAccessService. Большинство механизмов защиты, хотя и не все, реализованы в составе кода XPConnect, который обеспечивает доступ скриптов JavaScript к функциональности платформы Mozilla. В любом случае, сообщение о попытке нарушения ограничений защиты выдается на консоль JavaScript. 16.5.4.1. Режим защиты Web SafeРежим Web Safe (защищенный для работы в Web) - режим защиты, применяемый к приложениям Mozilla по умолчанию. В частности, в этом режиме выполняются приложения XUL, установленные за пределами chrome, а также любые Web-приложения, выполняемые в контексте окон браузера, содержащих документы XML или HTML. Режим Web Safe обеспечивает высокий уровень защиты, налагая два типа ограничений на операции, выполняемые скриптами. Первая группа ограничений призвана обеспечить контроль пользователя над интерфейсом и сделать заметными любые действия с ним. Пример такого ограничения - требование, чтобы любые окна имели размер не менее 100 пикселей в ширину и высоту и, следовательно, были заметны для пользователя. Второй тип ограничений связан с принципом "общего источника" (Same Origin), который широко применяется в рамках платформы Mozilla. Согласно этому принципу, скрипт может использовать лишь ресурсы, доступные при помощи того же протокола, по тому же доменному имени и номеру порта IP, что и сам скрипт или содержащий его документ. Таким образом, скрипт, полученный по протоколу HTTP с сервера www.test.com, не может взаимодействовать с Web-страницами, полученными с таких ресурсов, как www.pages.com, ftp://www.test.com или даже www.test.com:99 (если сам скрипт не был получен с порта 99). Принцип "общего источника" не позволяет скриптам воздействовать на содержимое других окон приложения или даже на содержимое других фреймов в том же окне, если это содержимое было получено из других источников. Все содержимое chrome, а также вся совокупность компонентов XPCOM считаются имеющими другой источник с точки зрения любого документа, полученного из Internet. Таким образом, при режиме защиты по умолчанию все эти компоненты и ресурсы недоступны для любого скрипта, полученного из удаленного источника. Они также недоступны для локальных скриптов, расположенных за пределами chrome. Принцип "общего источника" не распространяется на специальный URL about:blank, который доступен для любых скриптов. 16.5.4.2. Режим защиты TrustedРежим Trusted (режим доверия) представляет собой противоположность режиму Web Safe. В режиме Trusted на выполнение скриптов не налагается никаких ограничений. Они могут осуществлять доступ к любым компонентам XPCOM, а также скриптам и документам из любого источника без каких-либо ограничений или подтверждений пользователя. Скрипты и другие ресурсы, установленные в chrome, выполняются в режиме Trusted. В частности, они никогда не запрашивают разрешения пользователя на доступ к тем или иным объектам. Некоторая проблема заключается в том, что при добавлении к chrome нового содержимого практически невозможно удостовериться в отсутствии у него вредоносных функций. Система XPInstall, о которой идет речь в главе 17 "Развертывание", в настоящее время не требует аутентификации пакетов, устанавливаемых в chrome. Для такой аутентификации было бы необходимо использование сертификатов или цифровых подписей. Это означает, что в настоящее время подлинность указанного источника пакета, устанавливаемого в chrome, не гарантирована. Теоретически возможна ситуация, при которой пользователь соглашается установить пакет в chrome, будучи введен в заблуждение недостоверной информацией о его происхождении, приведенной в пакете. В результате вредоносный скрипт может получить все права, предоставляемые режимом Trusted. На практике сведения о таких атаках на платформу Mozilla отсутствуют. 16.5.4.3. Режим защиты CertifiedРежим Certified (защита на основе сертификатов) можно рассматривать как промежуточный между режимами Web Safe и Trusted. Скрипты и другие ресурсы могут быть защищены при помощи цифровой подписи. В свою очередь, подлинность открытого ключа, используемого для проверки этой подписи, (принадлежность ключа определенному владельцу) может быть подтверждена специальной организацией - центром сертификации. В режиме Certified на любые скрипты до проверки их цифровой подписи распространяются те же ограничения, что и в режиме Web Safe. После того, как подпись проверена и сертификат, удостоверяющий подлинность ее открытого ключа, принят пользователем (непосредственно или в силу ранее выбранных установок), скрипт выполняется в режиме Trusted. Цифровые подписи и сертификаты - самостоятельная обширная тема, поэтому здесь мы затронем лишь те ее аспекты, которые значимы для прикладных скриптов. Для цифровой подписи скриптов и других ресурсов используется утилита SignTool. Эта утилита не входит в состав Mozilla, но доступна вместе с документацией на ресурсе компании Netscape http://devedge.netscape.com. SignTool позволяет не только подписывать файлы, но и генерировать тестовые сертификаты, которые могут использоваться в процессе отладки вместо "настоящих" сертификатов. Последние, как правило, выдаются центрами сертификации за плату. С использованием цифровых сертификатов связаны два аспекта конфигурации. Во-первых, платформа должна поддерживать базу данных по сертификатам. В классической Mozilla это делается автоматически, хотя некоторые операции по управлению сертификатами доступны и при помощи диалоговых окон настроек. Во-вторых, пользователь должен дать согласие на выполнение подписанного скрипта, ознакомившись с информацией о его подписи и сертификате. Поскольку давать такое согласие при каждом выполнении скрипта было бы утомительно, платформа может хранить информацию об уже данном согласии и следовать ей в дальнейшем. Вся эта информация хранится в составе профиля пользователя. Разница между режимами защиты Trusted и Certified состоит в том, что последний требует, как минимум, одного интерактивного подтверждения со стороны пользователя. Единственный способ избежать этого - создать специализированный вариант платформы, где необходимая информация о сертификатах и разрешениях уже содержится в профиле пользователя с момента установки. Режим защиты Certified может использоваться и без сертификатов. Так, следующая настройка позволяет обойтись без проверки сертификатов и цифровых подписей на данном компьютере. Однако и в этом случае скрипт должен в явном виде запросить необходимые привилегии и получить разрешение пользователя: user_pref("signed.applets.codebase_principal_support",
true);
Эта настройка полезна, главным образом, при разработке и отладке приложений, которые будут выполняться в режиме защиты Certified. Если приложение использует модель защиты Certified, каждый фрагмент кода (скрипт) перед тем, как выполнить операцию, запрещенную в режиме Web Safe (например, обращение к объекту XPCOM), должен запросить у пользователя необходимые привилегии. Это делается при помощи следующей функции: window.netscape.security.PrivilegeManager.enablePrivilege("
P1 P2 P3");
Эта функция запрашивает у пользователя подтверждение, открывая диалоговое окно, и, в случае согласия, предоставляет скрипту необходимые привилегии. Если соответствующее разрешение было дано раньше и сохранено в настройках пользователя, привилегии предоставляются без обращения к пользователю. При этом скрипт получает не все права, соответствующие режиму Trusted, а лишь запрошенные привилегии. Действие привилегий прекращается с окончанием текущей области видимости JavaScript (как правило - при выходе из данной функции или метода). В данном примере "P1 P2 P3" представляет собой список ключевых слов привилегий, разделенных пробелами. В вызове метода enablePrivilege должно быть использовано, по крайней мере, одно ключевое слово. Допустимые ключевые слова, а также функциональность, на которую распространяются соответствующие привилегии, приведены в таблице 16.20. Во внутренней реализации платформы наличие необходимых привилегий проверяется в разных местах, что обеспечивает высокий уровень защиты.
Данные, приведенные в таблице, любезно предоставлены Джесси Рудерманом и mozilla.org. 16.5.4.4. Режим защиты Domain PoliciedВ режиме защиты Domain Policied (политика защиты на основе доменов) те или иные действия разрешаются или запрещаются всем документам, происходящим из определенного источника. Под источником, как и в принципе "общего источника", понимается совокупность протокола, доменного имени и номера порта. Этот режим защиты позволяет разрешать или запрещать скриптам JavaScript выполнение определенных операций. Совокупность разрешений и запретов объединяется в элемент конфигурации, называемый политикой. Одна политика может применяться к нескольким источникам. Эта модель защиты наиболее сложна и редко используется в приложениях Mozilla. С другой стороны, она является наиболее гибкой - при ее использовании на выполнение скриптов может быть наложено как меньше, так и больше ограничений, чем в режиме Web Safe. Таким образом, в зависимости от конкретных настроек режим Domain Policied может быть как наиболее свободным, так и наиболее строгим режимом защиты. Большинство параметров, связанных с режимом Domain Policied, недоступны пользователю через графический интерфейс настроек Mozilla. Некоторые из доступных настроек реализованы с помощью этой системы защиты, однако данный факт для конечного пользователя неочевиден. Данная система защиты реализована для следующих целей:
Чтобы использовать эту модель защиты, необходимо добавить к пользовательским настройкам определенные правила. Это можно сделать в три этапа: определить имя политики защиты; задать источники, к которым применима эта политика; задать правила доступа к конкретным объектам для данной политики. Ниже мы последовательно рассмотрим все эти этапы. Существует три типа имен политик защиты - явные имена, групповое имя и политика по умолчанию. Эти имена образуют иерархию. Каждое свойство или объект, для которых может быть определено правило доступа, могут быть связаны с одним из имен каждого типа. На нижнем уровне иерархии находятся политики по умолчанию. Для каждого свойства JavaScript существует одна политика по умолчанию, которая применяется в том случае, если для этого свойства не определено других политик. Если никакие политики по умолчанию в явном виде не определены, ко всем свойствам применяется единственная политика по умолчанию, имеющая имя "default". Вы можете изменять эту политику, как и другие политики по умолчанию. Из дальнейшего изложения станет ясно, почему целесообразно использовать несколько политик по умолчанию. На следующем уровне находится групповая политика, обозначенная именем "*" (звездочка). Она применяется в том случае, если задана в явном виде, и имеет приоритет над политиками по умолчанию. На вершине иерархии находятся политики, заданные явными именами. Их имена всегда должны быть определены в явном виде. Эти политики имеют приоритет над всеми прочими. Для задания имен политик используются следующие настройки: user_pref("capability.policy.policynames","p1 test foo");
user_pref("capability.policy.default_policynames","normal,off");
Имена политик не могут содержать символ точки, списки имен разделяются пробелами или запятыми. В первой строке заданы имена трех политик; во второй строке заданы имена двух политик по умолчанию. Существует единственная групповая политика с именем "*", поэтому имя для нее не нужно задавать в явном виде. Определив имена политик, необходимо задать для каждой политики список источников. Каждая политика применяется лишь к документам, полученным из указанных для нее источников. Ниже приведен пример задания источников для политики с именем mypol: user_pref("capability.policy.mypol.sites", "http://test.com http://x.org");
Значением свойства в данном случае является список URL, разделенных пробелами или запятыми. URL может относиться к серверу в целом, но не к отдельным его каталогам. Каждый сайт не может входить более чем в одну строку настроек такого вида. Если указанная политика является политикой по умолчанию, именно она будет политикой по умолчанию для перечисленных сайтов. Это позволяет использовать для различных сайтов различные политики по умолчанию. Если вы хотите задать сайты, к которым должна применяться групповая политика, укажите * вместо mypol. После того, как заданы имена политик и соответствующие источники, остается определить правила доступа. Существует три типа правил. Каждому правилу соответствует одна строка в файле настроек пользователя. Первый и наиболее общий тип синтаксиса правил применим ко всем свойствам JavaScript независимо от того, являются ли они простыми значениями или же методами. В случае политики mypol правило имеет следующий вид: user_pref("capabilities.policy.mypol.Iface.Prop","Keywords")
Iface, Prop и Keywords необходимо заменить соответствующими строками.
Ниже приведен пример правила: user_pref("capabilities.policy.*.History.back","NoAccess");
Это правило означает, что групповая политика запрещает использование метода back() объекта nsIDOMHistory. Этот объект используется только в браузере Mozilla, и приведенное правило отключает функцию возврата к ранее просмотренным страницам. Второй тип синтаксиса применяется только к атрибутам JavaScript (свойствам, не являющимся методами) и позволяет разрешать или запрещать операции ECMAScript [[Get]] и [[Set]] для этих атрибутов. Правила имеют следующий вид: user_pref("capabilities.policy.mypol.Iface.Prop.Access","Keyword");
Iface и Prop имеют то же значение, что и в предыдущем случае. Keywords должно иметь одно из следующих значений: AllAccess, NoAccess или sameOrigin. Access должно быть одной из двух строк - set или get. Таким образом, этот синтаксис допускает два правила для каждого свойства - для чтения и для записи. Ниже приведен пример правила, которое запрещает изменять текст заголовка окон XUL: user_pref("capabilities.policy.default.ChromeWindow.title.set","NoAccess");
Третий тип синтаксиса относится к JavaScript в целом. Он позволяет при помощи единственного правила полностью запретить или разрешить выполнение скриптов JavaScript для группы источников: user_pref("capabilities.policy.mypol.javascript.enabled","Keyword");
В этом случае можно задать лишь имя политики и значение строки Keyword. Вместо Keyword можно поставить одно из двух значений: NoAccess (отключить JavaScript) или AllAccess (активизировать JavaScript). Если JavaScript отключен глобально, правила такого типа игнорируются. Типичная политика содержит ряд правил такого рода, разрешающих или запрещающих определенные действия. Если вы хотите запретить какое-либо действие, будьте внимательны и задайте правила для всех свойств, которые могут обеспечивать доступ к этому действию. Чтобы получить полный список свойств, следует изучить нужный объект при помощи Инспектора DOM, выбрав для правой панели Инспектора режим JavaScript Object. Особенно тщательно следует подходить к ограничению доступа к связкам XBL. Такая связка часто содержит множество вспомогательных методов и свойств, функциональность которых может пересекаться. Поэтому при необходимости запретить изменение какого-либо свойства одного из связанных объектов простое ограничение доступа к нему может оказаться недостаточным. Следует также создать правила типа NoAccess для всех свойств или методов связки, обращение к которым может повлиять на значение нужного свойства. Согласно "Оранжевой книге" Министерства обороны США, защита на основе политики является ограниченной формой защиты. Она основана на так называемом дискреционном контроле доступа; принятие любых мер по защите оставлено на усмотрение администратора (составителя политики). Кроме того, для обеспечения эффективной защиты составитель политики должен предусмотреть все возможные обходные пути доступа к защищаемым свойствам. 16.5.4.5. Специальные ограниченияСледует упомянуть еще несколько ограничений, которые не относятся к описанным режимам защиты. Эти ограничения действуют, по крайней мере, начиная с версии Mozilla 1.4.
На этом обсуждение системы защиты платформы Mozilla заканчивается. 16.5.5. Профили пользователяСлужба каталогов Mozilla обеспечивает доступ к папкам и каталогам текущего профиля пользователя. Также можно управлять набором существующих профилей. Для этого используется следующая пара XPCOM: @mozilla.org/profile/manager;1 nsIProfile Однако интерфейс nsIProfile не позволяет осуществлять доступ к файлам внутри заданного профиля. Для этого используется другая пара XPCOM: @mozilla.org/profile/manager;1 nsIProfileInternal 16.6. Практика: сохранение и загрузка заметок NoteTakerЭто практическое занятие посвящено чтению данных с диска и их записи при помощи объектов XPCOM. В нем показано, как работать с механизмами поддержки RDF в составе платформы непосредственно из скриптов JavaScript, не используя шаблонов XUL. Кроме того, в этом разделе продемонстрирован доступ к данным текущего профиля пользователя, что, впрочем, является довольно простой задачей. В этом разделе мы завершим работу над приложением NoteTaker, добавив к нему механизмы сохранения, удаления и загрузки заметок. Для этого нам нужно создать необходимые источники данных RDF. Чтобы лучше познакомиться с инфраструктурой поддержки RDF, мы будем работать с ними при помощи интерфейсов XPCOM низкого уровня, не используя библиотеки RDFLib. Текущая заметка всегда хранится в виде структуры данных JavaScript; хранилище фактов, связанное с источником данных RDF, используется для хранения данных всей совокупности заметок. Мы также попытаемся усовершенствовать запросы RDF. Запросы, основанные на шаблонах, имеют ограничения, которые можно преодолеть, работая с запросами из скриптов. До настоящего момента мы не могли найти заметку по данному URL, если только URL заметки не совпадал с образцом полностью. Теперь мы исправим эту ситуацию. Кроме того, текстовое поле для данных заметки в панели инструментов слишком просто для того, чтобы оправдать использование шаблона, и мы реализуем соответствующий запрос в форме скрипта. Фактически, в той или иной мере мы добавим скрипты ко всем используемым шаблонам. Как подобает при разработке программ, мы начнем с проектирования. 16.6.1. Проектирование источников данныхВ главе 14 "Шаблоны" мы сделали содержимое динамическим, используя атрибуты элементов XUL. Для каждого шаблона был определен собственный источник данных. Хотя это простой и удобный способ работы с источниками, он предполагает, что разработчику известен точный URL файла notetaker.rdf на машине пользователя. Поскольку теперь мы решили, что notetaker.rdf будет храниться в составе профиля пользователя, его URL не может быть известен заранее. Чтобы учесть это изменение, мы перенесем интеграцию с данными RDF из шаблонов XUL в скрипте JavaScript. Вместо указания источника данных в качестве атрибута XUL мы будем работать с ним как с объектом XPCOM в скрипте JavaScript. В этом же скрипте мы можем использовать другие объекты и интерфейсы, чтобы динамически установить местонахождение файла RDF. При описании шаблонов нам все равно понадобится указать источник данных в коде XUL. Для этого мы используем "нулевой" источник rdf:null, предоставляемый платформой Mozilla. После загрузки шаблонов мы создадим новый источник данных на основе объекта, представляющего URL, и подключим его к каждому из шаблонов с помощью JavaScript. В этом случае весь обмен данными RDF будет управляться единственным объектом-источником. Это не единственный метод создания источника данных, совместно используемого несколькими шаблонами XUL. Если два шаблона имеют один и тот же атрибут, определяющий источник данных, оба они будут совместно использовать один набор фактов (общее хранилище фактов). В противном случае код, написанный нами в главе 14, просто не смог бы корректно работать. Поэтому здесь мы всего лишь отделяем использование общего источника данных от XUL, чтобы иметь возможность работать с этим источником в виде отдельного объекта. В принципе, мы могли бы создать отдельный источник данных для каждого шаблона. Даже разные источники, основанные на одном и том же URL, фактически работают с одним общим набором фактов. Получив объект источника данных, мы можем читать и записывать данные при помощи функций JavaScript, а также многочисленных интерфейсов для работы с RDF. В то же время шаблоны XUL будут получать данные из того же источника, используя внутренние механизмы шаблонов. Чтобы усовершенствовать нашу объектную модель, мы дополним объект Note объектом NoteDataSource, представляющим источник данных. В последний раз мы работали с объектом Note в практическом разделе главе 14. Всякий раз, когда нам нужно добавить новую операцию с источником данных, мы можем реализовать ее как метод нашего нового объекта. 16.6.2. Создание источника данныхПрежде всего, следует поместить копию файла notetaker.rdf в папку текущего профиля пользователя. Необходимое условие успешного создания источника данных - получение доступа к этому файлу. Мы начинаем, зная точное имя файла и имея представление о его местонахождении, а закончить должны, имея объект nsIRDFDataSource. Мы включим в код приложения имя файла, но не путь к нему. Чтобы создать источник данных, мы используем некоторые приемы, описанные в этой главе. Чтобы обнаружить файл независимо от платформы, мы используем службу каталогов Mozilla. Изучая таблицы псевдонимов, приведенные выше в этой главе, мы обнаруживаем, что псевдоним ProfD, приведенный в таблице 16.18, позволяет получить доступ к папке текущего профиля. На основе этого псевдонима мы создадим объект nsIFile, представляющий папку профиля, дополним путь к папке, чтобы получить нужный файл, преобразуем файловый объект в URL и наконец создадим источник данных на основе этого URL. Все эти операции представлены в листинге 16.9. var Cc = Components.classes;
var Ci = Components.interfaces;
// Объект сеанса работы с NoteTaker
function NoteSession() {
this.init();
}
NoteSession.prototype = {
config_file : "notetaker.rdf",
datasource : null,
init : function (otherfile) {
var fdir, conv, rdf, file, url;
if (otherfile) this.config_file = otherfile;
with (window) {
fdir = Cc["@mozilla.org/file/directory_service;1"];
fdir = fdir.getService(Ci.nsIProperties);
conv = Cc["@mozilla.org/network/protocol;1?name=file"];
conv = conv.createInstance(Ci.nsIFileProtocolHandler);
rdf = Cc["@mozilla.org/rdf/rdf-service;1"];
rdf = rdf.getService(Ci.nsIRDFService);
}
file = fdir.get("ProfD", Ci.nsIFile);
file.append(this.config_file);
if (!file.exists())
throw this.config_file + " is missing";
if (!file.isFile() || !file.isWritable() || !file.isReadable())
throw this.config_file + " has type or permission problems";
url = conv.newFileURI(file);
this.datasource = rdf.GetDataSource(url.spec);
}
};
var noteSession = new NoteSession();
Листинг
16.9.
Обнаружение и инициализация локального источника данных.Вся работа выполняется в методе init() объекта NoteSession. Сначала мы создаем три объекта XCOM. Затем мы получаем папку текущего профиля в виде объекта nsIFile. Метод append(), не возвращающий никакого результата, изменяет этот объект так, что он в точности соответствует нашему конфигурационному файлу. Затем мы убеждаемся, что нужный файл существует, и что он доступен для чтения и записи. Предполагается, что в нашем случае такой файл существует всегда, поскольку он будет создаваться при установке приложения. Однако к реальному приложению все же следовало бы добавить код, автоматически создающий файл в случае его отсутствия - нельзя исключить возможность случайного удаления файла. Затем мы преобразуем nsIFile в nsIURL с помощью метода newFileURI(), получаем URL в виде строки, используя свойство spec, и, наконец, создаем источник данных на основе этой строки при помощи метода GetDataSource(). Эта последовательность шагов - стандартные действия при подготовке источников данных. При использовании внутреннего или удаленного источника действия могут несколько отличаться от приведенного примера. Так, если URL источника данных известен заранее, вся процедура может свестись к вызову метода GetDataSource(). 16.6.3. Динамическое подключение источников данных к шаблонамТеперь, когда мы получили источник данных, давайте используем его. Мы хотим модифицировать существующие шаблоны так, чтобы они получали данные от созданного нами объекта, а не из файла, указанного в коде шаблона. Поэтому в коде шаблона мы укажем "нулевой" источник данных datasources="rdf:null", а реальный источник подключим при помощи скрипта. 16.6.3.1. Модификация панели инструментовМы полностью отказываемся от использования шаблона для текстового поля <textbox> в панели инструментов NoteTaker. Это слишком сложное решение для простого текстового поля. В предыдущих главах мы использовали его с единственной целью: продемонстрировать один из возможных способов работы с шаблонами. Однако шаблоны не являются универсальным инструментом. Итак, код для текстового поля принимает следующий вид: <textbox id="notetaker-toolbar.summary"/> Поле заполняется с помощью функции refresh_toolbar(), которая копирует нужное значение из объекта заметки. Таким образом, задача обновления текстового поля решена без обращения к шаблонам. Раскрывающийся список ключевых слов в панели инструментов основан на стандартном использовании шаблона, и мы могли бы оставить его без изменений, если бы источник данных можно было указать в коде XUL. Однако, поскольку теперь местонахождение файла заметок нам заранее неизвестно, мы должны изменить код XUL и JavaScript. Содержимое этого списка генерировалось на основе данных, начиная с главе 14 "Шаблоны", однако оно было "недостаточно динамическим". Список заполнялся в момент создания страницы XUL и с этого момента оставался неизменным. Теперь он должен обновляться всякий раз при добавлении нового ключевого слова. Любое добавление или удаление содержимого XUL может вызвать полную перерисовку документа, включая список. Перерисовка выполняется автоматически, однако для сложных тегов, подобных <menulist>, она может выполняться неправильно. Необходимо использовать XUL аккуратно, иначе список после перерисовки будет выглядеть некорректно. Чтобы отслеживать ошибки при перерисовке, обратимся к коду для тега <menulist> и шаблона, который представлен в листинге 16.10. В качестве источника данных в этом коде указан "rdf:null". <menulist id="notetaker-toolbar.keywords" editable="true">
<menupopup datasources="rdf:null" ref="urn:notetaker:keywords">
<template>
<menuitem uri="rdf:*"
label="rdf:http://www.mozilla.org/notetaker-rdf#label"/>
</template>
</menupopup>
</menulist>
Листинг
16.10.
Тег <menupopup> приложения NoteTaker до добавления динамической перерисовкиВ данном случае в состав шаблона входят только теги <menuitem>. Если источником данных является "rdf:null", код XUL, полученный в результате обработки шаблона, будет иметь следующий вид: <menulist id="notetaker-toolbar.keywords" editable="true"> <menupopup datsources="rdf:null" ref="urn:notetaker:keywords"> </menupopup> </menulist> Панель инструментов, построенная на основе такого кода, показана на рисунке 16.2.  Рис. 16.2. Отображение списка с нулевым количеством элементов Этот интерфейс имеет существенные недостатки, как в части отображения, так и в части взаимодействия с пользователем. Мы могли бы проигнорировать эти проблемы, понадеявшись на то, что при отображении документа (событие onload) к нему будет подключен созданный нами источник данных, на основе которого будут созданы элементы <menuitem> для списка. К сожалению, дела обстоят не так хорошо. Размер содержимого списка определяется тегом <menupopup>, в состав которого входит фрейм. С момента создания размер этого фрейма не изменяется динамически, хотя в последующих версиях платформы ситуация может измениться. Это означает, что после первоначального отображения раскрывающегося списка его размер не будет изменяться, несмотря на изменение шаблона, определяющего содержимое списка. Усовершенствованный вариант кода, позволяющий обойти эту проблему, представлен в листинге 16.11: <menulist id="notetaker-toolbar.keywords"
editable="true"
datasources="rdf:null"
ref="urn:notetaker:keywords"
>
<template>
<menupopup>
<menuitem uri="rdf:*"
label="rdf:http://www.mozilla.org/notetaker-rdf#label"/>
</menupopup>
</template>
</menulist>
Листинг
16.11.
Тег <menupopup>, обеспечивающий динамическую перерисовку.В этом варианте тег <template> поднят на один уровень иерархии, так что тег <menupopup> оказался вложенным в него. В результате <menupopup> будет генерироваться заново при каждом обновлении шаблона. При этом будет создаваться лишь одна пара тегов, поскольку <menupopup> находится снаружи тега, в котором указан источник данных (атрибут uri). Вспомним, что при обработке шаблона именно тег, имеющий атрибут uri, вместе со своим содержимым создается многократно - по числу элементов, возвращаемых в результате запроса. Поскольку теперь <menupopup> генерируется заново при каждом обновлении содержимого списка, раскрывающийся список будет иметь корректный размер. Это рекомендуемый подход для создания раскрывающихся списков на основе шаблонов, если содержимое списка может динамически изменяться после первоначального отображения. Даже с учетом сделанных исправлений возможна еще одна проблема с отображением раскрывающегося списка, создаваемого на основе шаблона, хотя эта проблема не затрагивает нашего приложения. На рисунке 16.3 показана тестовая панель до и после однократного щелчка по кнопке, вызывающей раскрытие списка, - сверху и снизу соответственно.  Рис. 16.3. Проблема с перерисовкой раскрывающегося списка, основанного на шаблоне. В этом примере текстовое поле в верхней части раскрывающегося списка первоначально имеет ширину по умолчанию для тега <textbox>. При щелчке по кнопке раскрывается список с элементами, и текстовое поле перерисовывается заново с новой шириной, которая определяется самым широким элементом списка. В результате ширина элемента управления скачкообразно изменяется, что является недостатком пользовательского интерфейса. Чтобы решить эту проблему, достаточно в явном виде указать ширину (атрибут width) для тега <menulist>. К счастью, эта проблема не затрагивает NoteTaker, по крайней мере, при отображении реальных Web-страниц. Необходимые изменения кода JavaScript очень просты. В функциях refresh_toolbar() и init_toolbar() следует подключить источник данных к шаблону раскрывающегося списка. Эти изменения представлены в листинге 16.12. // слушатели onload работают в фазе перехвата
window.addEventListener("load", init_handler, true);
// загрузить содержимое RDF для панели инструментов. Используется объект заметки (note).
function init_toolbar(origin)
{
if ( origin != "timed" ) {
// избежать выполнения внутри любого обработчика onload
setTimeout("init_toolbar('timed')",1);
}
else
{
var menu = window.document.getElementById('notetakertoolbar.keywords');
menu.database.AddDataSource(noteSession.datasource);
menu.ref = 'urn:notetaker:keywords';
setInterval("content_poll()", 1000);
}
}
// обновить панель инструментов на основе текущей заметки.
function refresh_toolbar()
{
var box = document.getElementById('notetaker-toolbar.summary');
box.value = note.summary;
var menu = document.getElementById('notetaker-toolbar.keywords');
menu.ref = 'urn:notetaker:keywords';
}
Листинг
16.12.
Изменение кода панели инструментов NoteTaker с учетом динамического подключения источников данных.Варианты этих функций, приведенные в практическом разделе главе 14 "Шаблоны", вели себя беспокойно, вызывая rebuild() при малейшем изменении данных шаблона. В данном случае, однако, это излишне, поскольку шаблоны основаны на источнике данных типа xml-datasource, который сам инициирует все необходимые действия при изменении шаблона. Однако если при разработке собственного приложения вы не знаете точно, стоит ли вызвать rebuild(), всегда вызывайте эту функцию. Обновленная функция init_toolbar(), приведенная в листинге, подключает источник данных к шаблону раскрывающегося списка, обновляет свойство ref шаблона, а также обеспечивает периодическое выполнение функции content_poll(), которая следит за изменениями URL содержимого браузера. Даже если значение свойства ref в результате присваивания не изменилось, выполняется запрос к источнику данных и список строится заново на основе результатов запроса. Вызов setTimeout(), как и раньше, представляет собой меру предосторожности на случай непредвиденных проблем в обработчике события onload. Функцию refresh_toolbar() можно сравнить с методом Refresh() интерфейса nsIRDFRemoteDataSource. Этот метод обновляет хранилище фактов, лежащее в основе источника данных. Функция refresh_toolbar() обновляет только содержимое XUL, включая содержимое, основанное на шаблоне. На этом мы завершаем обсуждение изменений в коде панели инструментов, относящихся к отображению данных. Мы вернемся к панели инструментов, когда речь пойдет об обработке данных, вводимых пользователем. 16.6.3.2 Модификация диалогового окна EditДиалоговое окно Edit (окно редактирования заметки) - еще одна часть приложения NoteTaker, использующая шаблоны. Источники данных для этих шаблонов также должны динамически подключаться с использованием скриптов JavaScript. Панель Edit (Правка) диалогового окна не содержит никаких шаблонов. Панель Keyword (Ключевые слова) использует шаблоны для заполнения двух элементов - <listbox> и <tree>. Процедура подключения источников данных к этим шаблонам очень похожа на использованную для панели инструментов. Мы заменяем datasources="notetaker.rdf" на datasources="rdf:null" в двух местах документа editDialog.xul. Затем мы создаем новую функцию init_dialog() в файле dialog_action.js и модифицируем функцию refresh_dialog(). Результаты модификации скриптов приведены в листинге 16.13. window.addEventListener("load", init_dialog, "true");
function init_dialog()
{
if ( origin != "timed" ) {
// избежать выполнения внутри любого обработчика onload
setTimeout("init_dialog('timed')",1);
}
else
{
var listbox = document.getElementById('notetaker.keywords');
listbox.database.AddDataSource(window.opener.noteSession.datasource);
var tree = document.getElementById('notetaker.related');
tree.database.AddDataSource(window.opener.noteSession.datasource);
refresh_dialog();
}
}
function refresh_dialog()
{
var listbox = document.getElementById('dialog.keywords');
listbox.ref = window.opener.note.url;
//listbox.ref = "http://saturn/test1.html"; // для тестирования
var tree = document.getElementById('dialog.related');
tree.ref = window.opener.note.url;
//tree.ref = "http://saturn/test1.html"; // для тестирования
}
Листинг
16.13.
Изменение кода диалогового окна NoteTaker с учетом динамического подключения источников данных.Функция init_dialog(), добавляющая один источник данных к двум шаблонам, практически идентична функции init_toolbar(). Функция refresh_dialog() также аналогична функции refresh_toolbar() и для целей тестирования содержит некоторые URL, находящиеся в файле notetaker.rdf. Все эти изменения не затрагивают пользовательского интерфейса, они лишь позволяют работать с файлом notetaker.rdf, местонахождение которого определяется динамически. В практическом разделе главе 13 "Списки и деревья" мы экспериментировали с динамическим заполнением списков при помощи интерфейсов DOM. Решение этой задачи потребовало около 30 строк JavaScript. В этой главе мы достигли того же результата при помощи шаблона и всего нескольких строк кода. В результате всех этих изменений все шаблоны NoteTaker могут работать с файлом notetaker.rdf, находящимся в папке профиля пользователя, местонахождение которой в момент разработки приложения неизвестно. 16.6.4. Работа с запросами RDF при помощи интерфейсов XPCOMМеханизм шаблонов XUL - лишь один из способов формировать запросы к набору фактов RDF. Это декларативный подход, подобный языку SQL. Другой способ - самостоятельно перебирать факты RDF при помощи скрипта. Этот подход, аналогичный перемещению по структуре данных, можно назвать алгоритмическим. Он подразумевает использование множества интерфейсов XPCOM, предназначенных для работы с содержимым RDF. Эти интерфейсы облегчают перемещение между фактами, поэтому алгоритмический подход требует от разработчика меньше усилий, чем можно было бы ожидать. В приложении NoteTaker используется один запрос, который было бы разумно реализовать на основе скрипта. Это запрос, выполняющий поиск заметки, существующей для данного URL. Шаблоны не подходят для решения этой задачи по следующим причинам:
Поиск выполняется при помощи метода resolve() объекта заметки в файле notes.js. Мы уже создали каркас этого метода в предыдущих главах, а теперь добавим его полную реализацию. Метод загружает данные RDF для нужной заметки в соответствующие свойства объекта заметки. Реализация метода показана в листинге 16.14. resolve : function (url) {
var ds = window.noteSession.datasource;
var ns = "http://www.mozilla.org/notetaker-rdf#";
var rdf = Cc["@mozilla.org/rdf/rdf-service;1"];
rdf = rdf.getService(Ci.nsIRDFService);
var container = Cc["@mozilla.org/rdf/container;1"];
container = container.getService(Ci.nsIRDFContainer);
var cu = Cc["@mozilla.org/rdf/container-utils;1"];
cu = cu.getService(Ci.nsIRDFContainerUtils);
var seq_node = rdf.GetResource("urn:notetaker:notes");
var url_node = rdf.GetResource(url);
var chopped_node = rdf.GetResource(url.replace(/\?.*/,""));
var matching_node, prop_node, value_node;
if (!cu.IsContainer(ds,seq_node)) {
throw "Missing <Seq> 'urn:notetaker:notes' in " + noteSession.config_file;
return;
}
container.Init(ds,seq_node);
// Сначала попробовать полный URL, потом усеченный URL, если не найдены - заметки нет
if ( container.IndexOf(url_node) != -1) {
matching_node = url_node;
this.url = url;
this.chop_query = false;
}
else if ( container.IndexOf(chopped_node) != -1 ) {
matching_node = chopped_node;
this.url = url.replace(/\?.*/,"");
}
else {
this.url = null;
return;
}
else
return;
// Если заметка найдена, получить все ее свойства.
var props = ["summary", "details", "width", "height", "top", "left"];
for (var i=0; i<props.length; i++)
{
pred_node = rdf.GetResource(ns + props[i]);
value_node = ds.GetTarget(matching_node, pred_node, true);
value_node = value_node.QueryInterface(Ci.nsIRDFLiteral);
this[props[i]] = value_node.Value;
}
}
Листинг
16.14.
Выполнение запроса RDF из скрипта.Прежде всего, метод создает три служебных объекта XPCOM для работы с RDF. Объект nsIRDFService используется для преобразования простой строки URL в объект nsIRDFResource, являющийся подтипом более общего типа nsIRDFNode. Большинство методов для работы с RDF принимают в качестве аргумента не простые строки, а объекты типа nsIRDFNode. Мы создаем такие объекты как для полных, так и для усеченных URL. Единственное применение объекта nsIContainerUtils в нашем методе - убедиться, что в файле notetaker.rdf содержится ресурс urn:notetaker:notes, который является контейнером. Если это условие не выполнено, работа метода прерывается и генерируется исключение. Затем мы используем интерфейс nsIRDFContainer для того, чтобы связать URI контейнера (<Seq>) с источником данных и инициализировать эту связь. Как правило, доступ к источнику данных осуществляется путем обращения к отдельным фактам. Интерфейс nsIRDFContainer позволяет работать с контейнером и его элементами как со структурой данных. После инициализации служебных объектов мы переходим к выполнению собственно запроса, который в данном случае несложен. Его алгоритм таков: найти в источнике данных ресурс, соответствующий полному URL; если таковой отсутствует, найти ресурс, соответствующий URL без параметров; если и этот поиск завершился неудачей, отказаться от дальнейшего выполнения метода. В оставшейся части метода мы извлекаем все факты, описывающие пары свойство/значение для данной заметки. Метод rdf.GetTarget() всегда возвращает объект nsIRDFNode, который необходимо преобразовать к тому типу, который мы используем для свойств заметки. Во всех случаях это простая строка (мы не храним размеры окна как целые). Наконец, полученные значения свойств присваиваются свойствам объекта заметки. Эта часть кода предполагает, что заметка описана в файле notetaker.rdf корректным образом. Запрос, выполняемый в этом методе, основан на двух фактах и в целом аналогичен тем простым запросам, которые мы применяли в шаблонах, за исключением некоторых проверок в начале метода и использования двух различных URL для поиска. Если попытаться протестировать метод resolve(), например, добавив код вида: note.resolve("http://saturn/test1.html");
Система, скорее всего, выдаст неожиданные сообщения об ошибках. Как правило, ошибки такого рода возникают при первом обращении к интерфейсам для работы с RDF, однако могут возникать и позднее, и, что хуже всего, нерегулярно. Виновник ошибок находится за пределами объекта заметки - это объект noteSession. Источник данных инициализируется в функции init() в составе этого объекта следующим образом: this.datasource = GetDataSource(url.spec); Этот способ инициализации не подходит для наших задач. Он осуществляет асинхронную загрузку данных, поэтому хранилище данных заполняется постепенно. Тем временем скрипт переходит к выполнению дальнейших инструкций и, возможно, пытается запросить данные до того, как они загружены. Поэтому неудивительно, что методы RDF сообщают об отсутствии контейнеров и ресурсов, которые заведомо присутствуют в файле с данными. Решение проблемы - синхронная загрузка данных: this.datasource = GetDataSourceBlocking(url.spec); Это может привести к незначительной задержке при загрузке браузера, однако допустимо для нашего простого приложения. Впрочем, мы могли бы избежать этой задержки, не отказываясь от асинхронной загрузки, но используя дополнительные интерфейсы nsIRequestObserver или nsIStreamListener компонента xml-datasource. С помощью наблюдателя или слушателя мы могли бы определить момент завершения загрузки. Некоторые из объектов XPCOM, созданных для этой цели, могли бы найти применение и в других методах. Сделав эти объекты доступными через объект noteSession, мы могли бы обеспечить возможность их повторного использования. Дальнейшие подробности реализации этой стратегии выходят за рамки данной книги. В предыдущих главах мы написали код, который помещает данные объекта заметки в поля формы или HTML-документ, отображаемый в окне браузера. В этой главе мы подключили объект заметки к хранилищу фактов RDF, основанному на постоянно хранимом файле. В результате данные ранее сохраненных заметок должны корректно отображаться на экране. Необходимо лишь внести небольшое исправление в функцию content_poll() находящуюся в файле toolbar_action.js. Необходимо заменить эту строку: display_note() на следующую: if (note.url != null ) display_note() Это позволит не отображать никаких дополнительных элементов для страниц, для которых не созданы заметки. Так гораздо лучше! 16.6.5. Когда перемещать данные, введенные пользователем, в хранилище RDFNoteTaker позволяет не только просматривать уже сохраненные данные заметок, но и изменять или добавлять их. Последний раз мы работали с вводом данных в главе 7 "Формы и меню", где введенные данные пересылались на Web-сервер. В этой главе мы будем сохранять данные в хранилище файлов RDF и, в конечном счете, в локальном файле. Основная альтернатива этому решению - использование реляционной базы данных. Для наших целей сохранить данные означает добавить их к источнику данных. После этого они будут находиться в оперативной памяти до тех пор, пока пользователь не выполнит какие-либо действия, приводящие к синхронизации хранилища фактов с файлом, или до завершения работы платформы. Какие именно действия пользователя должны приводить к сохранению данных на диске - решать разработчику. Пользователь может вводить и изменять данные как в панели инструментов NoteTaker, так и в диалоговом окне. Мы последовательно рассмотрим эти варианты, начав с панели инструментов. Пользователь может легко создать или изменить заметку, используя поля аннотации (summary) и ключевых слов (keyword) в панели инструментов. Любого изменения в поле аннотации или добавленного ключевого слова достаточно для того, чтобы заметка считалась измененной. Если пользователь изменяет эти поля, но не нажимает ни одной кнопки панели инструментов (Edit, Save или Delete), происходить ничего не должно. Поэтому данные, измененные пользователем, могут обрабатываться при помощи команд, доступных из панели инструментов. Прибегать к обработчикам событий onchange или другим подобным механизмам не требуется. Панель Edit диалогового окна в этом отношении аналогична панели инструментов. Изменения, сделанные пользователем, должны сохраняться лишь в том случае, если пользователь нажимает кнопку OK. Если пользователь закрывает окно, нажав кнопку Cancel, изменения сохраняться не должны. Однако ситуация с панелью Keywords более сложна. Панель Keywords позволяет пользователю добавить или удалить любое количество ключевых слов, используя соответствующие кнопки. Проблема состоит в следующем: где должны храниться эти изменения, пока диалоговое окно не закрыто? Если пользователь, в конечном счете, нажимает Cancel, добавленные слова не должны быть сохранены. Если пользователь принимает сделанные изменения, они должны быть сохранены. Однако мы хотим, чтобы в процессе работы пользователя с окном вносимые изменения отображались в соответствующих элементах <listbox> и <tree>. Это означает, что ключевые слова должны добавляться к хранилищу RDF, даже если мы еще не знаем, примет пользователь эти изменения или отменит их. Таким образом, мы столкнулись с проблемой отмены сделанных действий, иными словами - отката транзакций. Мы хотим немедленно добавлять ключевые слова к источнику данных, чтобы они были доступны всем элементам, использующим этот источник, однако нам необходимо иметь возможность удалить их, если пользователь, в конце концов, не принимает сделанных изменений. Для решения этой проблемы мы реализуем новый контроллер команды. Этот контроллер будет записывать выполняемые операции с ключевыми словами в буфер отмены. Если будет получена команда на отмену транзакции, контроллер, используя сохраненную информацию, сможет вернуть источник данных к исходному состоянию. Платформа Mozilla не предоставляет готового объекта с такой функциональностью, но в большинстве случаев его реализация не должна вызывать затруднений. Таким образом, вся обработка пользовательских данных основана на инфраструктуре команд. Это простое и изящное архитектурное решение. Данные пребывают в полях форм, не вызывая какой-либо активности программы, до тех пор, пока пользователь не запускает одну из команд. Эта команда может поместить данные в хранилище фактов, после чего они станут доступны всему приложению, в частности, любым шаблонам. Если команда также ответственна за сохранение данных в постоянном хранилище, данные RDF могут быть синхронизированы с локальным диском или переданы по сети. 16.6.6. Усовершенствование команд для работы с содержимым RDFТеперь мы обратимся к конкретному коду, который обеспечивает сохранение на диске введенных пользователем данных. Мы усовершенствуем функции action(), вызываемые из панели инструментов и диалогового окна, а также реализуем дополнительный контроллер команды для работы с ключевыми словами в диалоговом окне. Функция action() панели инструментов поддерживает команды notetaker-open-dialog, notetaker-save, notetaker-display и notetaker-delete. Только команды -save и -delete связаны с изменением содержимого RDF. Реализация обеих команд довольно громоздка, поэтому в листинге 16.15 показан только код, относящийся к более простой команде notetaker-save. function action(task)
{
var ns = "http://www.mozilla.org/notetaker-rdf#";
var rdf = Cc["@mozilla.org/rdf/rdf-service;1"];
rdf = rdf.getService(Ci.nsIRDFService);
var container = Cc["@mozilla.org/rdf/container;1"];
container = container.getService(Ci.nsIRDFContainer);
var url_node;
// ... реализация других команд удалена ...
if ( task == "notetaker-save" )
{
var summary = document.getElementById("notetaker-toolbar.summary");
var keyword = document.getElementById("notetaker-toolbar.keywords");
var update_type = null;
if ( note.url != null )
{
if ( keyword.value != "" || summary.value != note.summary )
{
update_type = "partial"; // существующая заметка: обновить аннотацию, ключевые слова
url_node = rdf.GetResource(note.url);
}
}
else if ( window.content && window.content.document && window.content.document.visited )
{
update_type = "complete"; // a new note
url_node = window.content.document.location.href;
url_node = url_node.replace(/\?.*/,""); // toolbar chops any query
url_node = rdf.GetResource(url_node);
}
if ( update_type == "complete" )
{
// добавить url заметки к контейнеру
var note_cont = rdf.GetResource("urn:notetaker:notes");
container.Init(noteSession.datasource,note_cont);
container.AppendElement(url_node);
// добавить поля заметки, за исключением ключевых слов
var names = ["details", "top", "left", "width", "height"];
var prop_node, value_node;
for (var i=0; i < names.length; i++)
{
prop_node = rdf.GetResource(ns + names[i]);
value_node = rdf.GetLiteral(note[names[i]]);
noteSession.datasource.Assert(url_node, prop_node, value_node, true);
}
}
if ( update_type != null)
{
// обновить/добавить аннотацию
var summary_pred = rdf.GetResource(ns + "summary");
var summary_node = rdf.GetLiteral(summary.value);
noteSession.datasource.Assert(url_node, summary_pred, summary_node, true);
// начать работу с новым ключевым словом
var keyword_node = rdf.GetResource("urn:notetaker:keyword:" + keyword.value);
var keyword_value = rdf.GetLiteral(keyword.value);
// сделать ключевое слово связанным с одним из ключевых слов для данной заметки
var keyword_pred = rdf.GetResource(ns + "keyword");
var related_pred = rdf.GetResource(ns + "related");
var keyword2 = noteSession.datasource.GetTarget(url_node, keyword_pred, true);
if (keyword2)
noteSession.datasource.Assert(keyword_node, related_pred, keyword2, true);
// добавить ключевое слово к данной заметке
noteSession.datasource.Assert(url_node, keyword_pred, keyword_node, true);
// добавить текст ключевого слова
var label_pred = rdf.GetResource(ns + "label");
noteSession.datasource.Assert(keyword_node, label_pred, keyword_value, true);
// добавить ключевое слово к контейнеру, содержащему все ключевые слова
var keyword_cont = rdf.GetResource("urn:notetaker:keywords");
container.Init(noteSession.datasource,keyword_cont);
container.AppendElement(keyword_node);
}
// записать на диск
noteSession.datasource.QueryInterface(Ci.nsIRDFRemoteDataSource)
.Flush();
note.resolve();
display_note();
}
Листинг
16.15.
Обновление и сохранение данных RDF в приложении NoteTakerЭтот код содержит эквивалент одной транзакции применительно к данным RDF. Вначале выполняются стандартные подготовительные действия - инициализация интерфейсов XPCOM. Затем код обращается к пользовательскому интерфейсу, чтобы решить, какой тип сохранения необходим в данной ситуации. На основе содержимого полей аннотации и ключевых слов, состояния объектов note и noteSession, а также состояния текущего URL принимается решение о том, существует ли уже заметка для данного URL. Чтобы облегчить себе задачу, мы используем некоторые данные, полученные функцией content_poll(), например значение свойства visited. Если заметка уже существует, сохранение подразумевает частичное обновление уже существующих фактов. Если же заметки для данного URL еще нет, необходимо создать ее, что подразумевает создание всех необходимых фактов. Если новая заметка создается при помощи панели инструментов, мы удаляем все параметры запроса GET из URL. Значение, указывающее на характер необходимого обновления, присваивается переменной update_type. Поскольку частичное обновление представляет собой подмножество полного обновления (создания новой заметки), существует часть кода, которая выполняется при любом обновлении. Ветвь кода, следующая за оператором: if ( update_type == "complete" ) содержит действия, необходимые для полного обновления, за исключением общей части. Общая часть содержится в следующей ветви, которая выполняется при любом типе обновления: if (update_type != null ) Рассмотрим каждую из ветвей поочередно. При создании новой заметки сначала мы получаем доступ к контейнеру urn:notetaker:notes, а затем добавляем к нему URL, соответствующий заметке. Затем создаются факты для каждого из свойств заметки, кроме аннотации и ключевых слов. Любые строки перед передачей интерфейсам RDF должны быть преобразованы к типу nsIRDFNote или его подтипам. Всего создается шесть новых фактов (один для URL и пять для свойств заметки). Затем вызывается код для частичного обновления. Он выполняется всегда за исключением случаев, когда новую заметку создать нельзя. Заметку невозможно создать, например, для URL about:blank или FTP-сайта; в этом случае команда notetaker-save не приведет ни к каким действиям. Для сохранения аннотации мы просто добавляем еще один факт. Для добавления мы используем метод Assert(), который не выполняет никаких действий, если такой факт уже существует. Поскольку в нормальных условиях в хранилище не должно существовать несколько копий одного и того же факта, для добавлении новых фактов рекомендуется использовать этот метод. Затем код выполняет более сложную работу по добавлению ключевого слова. Если заметке уже были присвоены ключевые слова, мы хотим, чтобы новое слово было связано с остальными. Для этого мы должны добавить факт, связывающий новое слово с одним из ранее присвоенных слов. Для этого мы пытаемся найти ключевое слово, уже присвоенное данной заметке, и в случае успеха добавляем факт, связывающий его с новым словом. Мы делаем это перед тем, как связать новое ключевое слово с заметкой, чтобы избежать ситуации, в которой новое слово окажется связанным с самим собой. Логика оставшегося кода прямолинейна - мы добавляем ключевое слово к заметке, к контейнеру ключевых слов urn:notetaker:keywords и, наконец, сохраняем само слово (его значение). Таким образом, в этой ветви кода мы добавили пять фактов - один для аннотации и четыре для ключевых слов. Поскольку источник данных основан на полноценном xml-datasource, эти изменения будут автоматически переданы всем шаблонам, использующим данный источник. Затем мы вызываем метод Flush(), чтобы записать состояние источника данных на локальный диск. Имейте в виду, что этот метод полностью переписывает файл notetaker.rdf практически в произвольном порядке, и любое форматирование файла будет утрачено. Наконец, мы обновляем объект note и отображаем данные заметки, чтобы привести структуры данных JavaScript и пользовательский интерфейс в соответствие с данными RDF. На этом мы заканчиваем обсуждение реализации команды notetaker-save. Команда notetaker-delete реализуется аналогичным образом. Наибольшую сложность при этом представляет определение того, какие из ключевых слов, связанных с заметкой, могут быть удалены, а какие нужны для других заметок. Это требует анализа многих возможных вариантов, и мы не будем рассматривать их здесь. С кнопкой Delete (Удалить) на панели Keywords связана аналогичная логика; мы обсудим ее ниже. Функция action() диалогового окна Edit поддерживает следующие команды: notetaker-nav-edit, notetaker-nav-keywords, notetaker-save, notetaker-load и notetaker-close-dialog. Из них лишь команда notetaker-save требует работы с данными RDF. Как показано в листинге 16.16, для ее реализации мы можем использовать команду notetaker-save панели инструментов. if (task == "notetaker-save")
{
var field, widget, note = window.opener.note;
for (field in note)
{
widget = document.getElementById("dialog." + field.replace(/_/,"-"));
if (!widget) continue;
if (widget.tagName == "checkbox")
note[field] = widget.checked;
else
note[field] = widget.value;
}
window.opener.setTimeout('execute("notetaker-save")',1);
}
Листинг
16.16.
Усовершенствованная команда notetaker-save для диалогового окна.Последняя инструкция этого фрагмента представляет собой вызов команды notetaker-save панели инструментов. Мы не можем вызвать метод window.opener.execute() непосредственно, поскольку в этом случае функция будет выполняться в контексте диалогового окна, а не окна браузера. Обращаясь к методу setTimeout() окна браузера, мы обеспечиваем необходимый контекст выполнения функции. Наконец, нам нужны дополнительные команды для работы с ключевыми словами в панели Keywords диалогового окна Edit. Эти команды будут объединены в контроллер, поддерживающий принятие или отмену изменений (фиксацию и откат транзакций). Контроллер будет поддерживать следующие команды: notetakerkeyword-add, notetaker-keyword-delete, notetaker-keyword-commit и notetaker-keyword-undo-all. Поскольку эти команды тесно связаны друг с другом и используют общие данные, их нецелесообразно реализовывать по отдельности в составе функции action(). Вместо этого мы реализуем их непосредственно в составе контроллера, создав специально для этого новый файл keywordController.js. Общая структура контроллера показана в листинге 16.17. var keywordController = {
_cmds : { },
_undo_stack : [],
_rdf : null,
_ds : null,
_ns : "http://www.mozilla.org/notetaker-rdf#",
_related : null,
_label : null,
_keyword : null,
init : function (ds) { ... initialize ... },
_LoggedAssert : function (sub, pred, obj) { ... },
_LoggedUnassert : function (sub, pred, obj) { ... },
supportsCommand : function (cmd)
{ return (cmd in this._cmds); },
isCommandEnabled : function (cmd) { return true; },
onEvent : function (cmd) { return true; },
doCommand : function (cmd) {
... подготовительные операции ...
switch (cmd) {
case "notetaker-keyword-add":
case "notetaker-keyword-delete":
case "notetaker-keyword-commit":
case "notetaker-keyword-undo-all":
}
}
};
keywordController.init(window.opener.noteSession.datasource);
Листинг
16.17.
Контроллер команд для работы с ключевыми словами в диалоговом окнеКак и любой контроллер команд, этот контроллер поддерживает четыре стандартных метода, начиная с supportsCommand(). Метод doCommand() выполняет различные действия в зависимости от переданного имени команды; код в нем организован при помощи оператора case. Контроллер также поддерживает ряд других действий. В массиве _undo_stack сохраняются действия, которые могут быть отменены. Реализованные нами методы _LoggedAssert() и _LoggedUnassert() аналогичны стандартным методам для работы с RDF Assert() и Unassert(), однако кроме этого они выполняют журналирование - оставляют запись о выполненных действиях в массиве _undo_stack. Давайте начнем анализ контроллера с метода init(), который показан в листинге 16.18: init : function (ds) {
this._rdf = Cc["@mozilla.org/rdf/rdf-service;1"];
this._rdf = this._rdf.getService(Ci.nsIRDFService);
this._ds = ds;
this._related = this._rdf.GetResource(this._ns + "related");
this._label = this._rdf.GetResource(this._ns + "label");
this._keyword = this._rdf.GetResource(this._ns + "keyword");
window.controllers.insertControllerAt(0,this);
},
Листинг
16.18.
Инициализация контроллера команд для работы с ключевыми словами.Этот метод создает доступные для контроллера ссылки на ряд полезных объектов - службу RDF, источник данных и три часто используемых предиката фактов. Затем контроллер регистрируется в диалоговом окне. Поскольку он оказывается первым в цепочке контроллеров, мы можем быть уверены, что любая команда, поддерживаемая этим контроллером, будет обработана именно им. Реализация двух следующих функций - _LoggedAssert() и _LoggedUnassert() - иллюстрирует, каким образом контроллер может сохранять информацию о выполняемых командах. В данном случае речь идет об истории добавления и отмены фактов RDF, которая в дальнейшем может использоваться для отмены выполненных действий. Реализация двух этих функций показана в листинге 16.19. _LoggedAssert : function (sub, pred, obj)
{
if ( !this._ds.HasAssertion(sub, pred, obj, true))
{
this._undo_stack.push( { assert:true, sterm:sub,
pterm:pred, oterm:obj } );
this._ds.Assert(sub, pred, obj, true);
}
},
_LoggedUnassert : function (sub, pred, obj)
{
if ( this._ds.HasAssertion(sub, pred, obj, true))
{
this._undo_stack.push( { assert:false, sterm:sub,
pterm:pred, oterm:obj } );
this._ds.Unassert(sub, pred, obj, true);
}
},
Листинг
16.19.
Журналирование добавления и удаления фактовЭти функции представляют собой замену стандартных методов nsIRDFDataSource.Assert() и nsIRDFDataSource.Unassert(). В обоих случаях сначала выполняется проверка того, изменит ли предполагаемое действие состояние хранилища фактов. Если это так, создается запись о действии в форме объекта с четырьмя свойствами, которая добавляется в журнал (стек). Свойство assert указывает на характер выполняемого действия. После этого вызывается стандартный метод для изменения фактов RDF. Журнал изменений, создаваемый при помощи этих двух функций, может использоваться командами notetaker-keyword-commit и notetaker-keyword-undo-all. Реализация этих команд в составе метода doCommand() представлена в листинге 16.20. case "notetaker-keyword-commit":
this._undo_stack = [];
break;
case "notetaker-keyword-undo-all":
while (this._undo_stack.length > 0 )
{
var cmd = this._undo_stack.pop();
if ( cmd.assert )
this._ds.Unassert(cmd.sterm, cmd.pterm, cmd.oterm, true);
else
this._ds.Assert(cmd.sterm, cmd.pterm, cmd.oterm, true);
}
break;
Листинг
16.20.
Принятие и отмена изменений с использованием журналаРеализация команды notetaker-keyword-commit тривиальна - она просто удаляет из журнала все записи, чтобы выполненные действия нельзя было отменить в дальнейшем. Команда notetaker-keyword-undo-all чуть более сложна. Она перебирает элементы стека, выполняя Unassert() для каждого Assert()'а, записанного в журнале, и наоборот. В конце концов стек оказывается пустым, так что "отмена отмены" в данной реализации невозможна. Хотя в данном случае в журнал записываются добавления и удаления отдельных фактов, столь же просто организовать журналирование целых команд. Эта возможность обсуждалась в главе 9 "Команды". Оставшаяся часть метода doCommand() приведена в листинге 16.21. doCommand : function (cmd) {
var url = window.opener.content.document.location.href;
var keyword = window.document.getElementById("dialog.keyword").value;
if (keyword.match(/^[ \t]*$/))
return;
var keyword_node = this._rdf.GetResource("urn:notetaker:keyword:" + keyword);
var keyword_value = this._rdf.GetLiteral(keyword);
var url_node = this._rdf.GetResource(url);
var test_node, keyword2, enum1, enum2;
switch (cmd) {
case "notetaker-keyword-add":
// Связать ключевое слово с другим, если таковое существует
keyword2 = this._ds.GetTarget(url_node, this._keyword, true);
if (keyword2)
this._LoggedAssert(keyword_node, this._related, keyword2);
// добавить данное ключевое слово
this._LoggedAssert(keyword_node, this._label, keyword_value);
// добавить ключевое слово к текущей заметке
this._LoggedAssert(url_node, this._keyword, keyword_node);
break;
case "notetaker-keyword-delete":
// удалить связь ключевого слова с текущей заметкой.
this._LoggedUnassert(url_node, this._keyword, keyword_node);
// если ключевое слово не используется в других местах, удалить его и связанные с ним факты
enum1 = this._ds.GetSources( this._keyword, keyword_node, true);
if (!enum1.hasMoreElements())
{
// данное ключевое слово
this._LoggedUnassert(keyword_node, this._label, keyword_value);
// ключевое слово, с которым связано данное слово
enum2 = this._ds.GetTargets(keyword_node, this._related, true);
while (enum2.hasMoreElements())
this._LoggedUnassert(keyword_node, this._related,
enum2.getNext().QueryInterface(Ci.nsIRDFNode));
// ключевое слово, которое связано с данным словом
enum2 = this._ds.GetSources(this._related, keyword_node, true);
while (enum2.hasMoreElements())
this._LoggedUnassert(enum2.getNext().QueryInterface(Ci.nsIRDFNode), this._related, keyword_node);
}
else // ключевое слово используется в других местах
{
// удалить факты, если слова, с которыми связано данное ключевое слово, относятся только к данной заметке
enum1 = this._ds.GetTargets(keyword_node, this._related, true);
while (enum1.hasMoreElements())
{
keyword2 = enum1.getNext().QueryInterface(Ci.nsIRDFNode);
enum2 = this._ds.GetSources(this._keyword, keyword2, true);
test_node = enum2.getNext().QueryInterface(Ci.nsIRDFNode);
if (!enum2.hasMoreElements() && test_node.EqualsNode(url_node))
this._LoggedUnassert(keyword_node, this._related, keyword2);
// удалить факты, если слова, которые связаны с данным ключевым словом, относятся только к данной заметке
enum1 = this._ds.GetSources(this._related, keyword_node, true);
while (enum1.hasMoreElements())
{
keyword2 = enum1.getNext().QueryInterface(Ci.nsIRDFNode);
enum2 = this._ds.GetSources(this._keyword, keyword2, true);
test_node = enum2.getNext().QueryInterface(Ci.nsIRDFNode);
if (!enum2.hasMoreElements() && test_node.EqualsNode(url_node))
this._LoggedUnassert(keyword2, this._related, keyword_node);
}
}
}
break;
Листинг
16.21.
Инициализация метода doCommand(), добавление и удаление ключевых словОколо десятка строк, находящихся до оператора switch(), выполняют инициализацию локальных переменных и прекращают выполнение команды в том случае, если текущая заметка отсутствует. В листинге показаны только ветви оператора switch(), соответствующие командам notetaker-keyword-add и notetaker-keyword-delete. Добавление и удаление ключевых слов было бы проще, если бы мы не пытались поддерживать логику связей между ключевыми словами. Значительная часть кода, особенно для удаления ключевых слов, связана с решением этой задачи. Обе команды предполагают, что заметка для данного URL уже существует или создается в данный момент. Поэтому ключевые слова добавляются и удаляются в контексте определенного URL. Основные действия отмечены в коде при помощи комментариев, однако ниже приводятся более подробные пояснения. Весь код написан с учетом того ограничения, что в хранилище фактов не могут находиться две копии одного и того же факта. Каждый факт в хранилище уникален. Поэтому мы должны работать с хранилищем глобально, учитывая последствия добавления или удаления отдельных фактов для хранилища в целом. Добавление факта - более простой случай, чем удаление. Необходимо добавить к хранилищу следующие факты: <- keyword-urn, related, keyword2-urn -> (не обязательно) <- note-url, keyword, keyword-urn -> <- keyword-urn, label, keyword-literal -> Мы должны сделать так, чтобы все ключевые слова, присвоенные одной заметке, были связаны между собой. В нашей модели RDF для этого достаточно связать добавляемое слово хотя бы с одним из ключевых слов, уже присвоенных заметке. После этого вся совокупность слов, связанных между собой, может быть установлена путем перемещения по связям. Поэтому сначала мы проверяем наличие ключевых слов у данной заметки и, если таковые обнаружены, связываем новое слово с одним из них. После этого мы можем создать факты, отражающие принадлежность нового слова текущей заметке, а также значение (текст) этого слова. Каждый из фактов создается при помощи метода _LoggedAssert(). Процедура удаления ключевых слов значительно более сложна. Нетрудно удалить информацию, связанную с конкретной заметкой, но ключевое слово может быть присвоено нескольким заметкам. Это означает, что оно может быть включено в связи между ключевыми словами, также относящиеся к другим заметкам. Поэтому мы не можем просто удалить факты первого и третьего типа, не изучив вопрос, где еще используется данное ключевое слово. Наши дальнейшие действия будут зависеть от того, присвоено ли оно другим заметкам. Это требует довольно громоздкой логики, которая описана ниже. Если ключевое слово используется для единственной заметки, то вся информация об этом слове ограничена данной заметкой. Поэтому мы можем просто удалить все три факта. Если же слово используется для других заметок, следует действовать более аккуратно. Мы можем удалить факт о связи ключевого слова с данной заметкой, но мы не можем удалить само ключевое слово (факт о его значении). Самая сложная часть логики - удаление фактов, описывающих связь данного слова с другими ключевыми словами. Если факт о связи данного ключевого слова с другим сформирован на основе другой заметки, мы не должны удалять его. Поэтому, если другое слово присвоено какой-либо другой заметке наряду с данным, факт относится и к этой заметке и потому должен быть сохранен. В противном случае следует удалить этот факт. Мы выполняем проверку дважды, поскольку удаляемое ключевое слово может быть как субъектом, так и объектом факта о связи ключевых слов. Внимательный читатель может заметить, что контейнер urn:notetaker:keywords также должен быть обновлен командами -add и -delete. Мы не сделали этого, поскольку реализация команд и без того достаточно сложна, а для того, чтобы увязать дальнейшие обновления с нашей системой отмены, требуются определенные ухищрения. Более общим решением было бы связать объекты- наблюдатели источника данных со стеком-журналом, однако здесь мы не будем рассматривать это решение. На этом мы завершаем обсуждение команд NoteTaker для работы с данными RDF. Для того чтобы эта система заработала, необходимо связать контроллер и команды с диалоговым окном. Для этого требуется несколько фрагментов кода. Мы должны добавить к файлу editDialog.xul дополнительный тег <script>: Кроме того, мы должны добавить несколько обработчиков событий к тегу <dialog> в том же файле. Эти обработчики нужны для работы с ключевыми словами из диалогового окна. <dialog xmlns="http://www.mozilla.org/keymaster/
gatekeeper/there.is.only.xul"
id="notetaker.dialog"
title="Edit NoteTaker Note"
onload="execute('notetaker-load');"
ondialogaccept="execute('notetaker-keyword-commit');
execute('notetaker-save');
execute('notetaker-close-dialog');"
ondialogcancel="execute('notetaker-keyword-undo-all');
execute('notetaker-close-dialog');"
>
Обработчики разрастаются, и если по мере развития приложения придется добавлять новые, целесообразно объединить группы команд в функции. Некоторые другие обработчики для диалогового окна определены в файле dialog_handlers.js. Теперь, когда мы создали контроллер для работы с ключевыми словами, два из этих обработчиков превращаются в тривиальные вызовы команд: function add_click(ev)
{
execute("notetaker-keyword-add");
}
function delete_click(ev)
{
execute("notetaker-keyword-delete");
}
Теперь мы можем считать, что приложение NoteTaker завершено - по крайней мере, в той степени, в какой это позволяет сделать объем книги. 16.6.7. Кадры (views) деревьев RDF и источники данных.В практическом разделе главе 13 "Списки и деревья" мы экспериментировали с "кадрами". При желании этот эксперимент может быть распространен на данные RDF. В таком случае тег <tree>, содержащий кадр, может получать содержимое из источника данных без помощи шаблона. Поскольку объем книги не позволяет подробно обсудить этот вопрос, сделаем несколько кратких замечаний. В главе 13 мы реализовали метод calcRelatedMatrix(), который получал данные из массива treedata. Мы можем изменить этот метод так, чтобы он получал связанные пары ключевых слов не из массива JavaScript, а от источника данных. В этом случае наш код заработает немедленно, но уже на основе данных RDF. Однако такая стратегия - довольно примитивное использование возможностей источников данных. Более разумное решение - использовать интерфейс nsIRDFObserver. Если объект JavaScript, реализующий кадр, поддерживает этот интерфейс, он может быть зарегистрирован в качестве наблюдателя в источнике данных (источник, в свою очередь, должен поддерживать интерфейс nsIRDFCompositeDataSource). В результате кадр будет получать уведомление всякий раз, когда факт в источнике изменяется, и сможет отразить это изменение в элементе <tree>, не перестраивая дерево полностью. Эта более сложная стратегия совместима с системами управления событиями, в которых события могут поступать с удаленного сервера. В заключение отметим, что объект с интерфейсом nsIRDFDataSource может быть полностью реализован на JavaScript. Такой объект может имитировать источник данных RDF. С другой стороны, в него могут быть "завернуты" один или несколько источников данных, так что фактически он будет выступать в качестве составного источника. В любом случае, такой объект может быть подключен к шаблону точно так же, как и источники, предоставляемые платформой. 16.7. Отладка: работа с источниками данныхВот некоторые из типичных проблем, возникающих при работе с источниками данных: Регистр символов. В отличие от остальных методов XPCOM, имена методов интерфейсов источников данных начинаются с прописной буквы - InitCaps, а не initCaps. Поэтому, например, метод называется GetResource(), а не getResource(). Асинхронная загрузка. Если для создания источника данных используется метод GetDataSource() интерфейса nsIRDFDataSource, а не GetDataSourceBlocking(), данные загружаются в источник параллельно с выполнением других инструкций. В результате попытка обратиться к данным немедленно после создания источника может привести к ошибке. Данные, заведомо присутствующие в источнике с точки зрения разработчика, могут оказаться еще не загружены. Синтаксические ошибки в тестовых данных. Тестовые данные из файла RDF, содержащего синтаксические ошибки, будут загружены лишь до места первой ошибки. При этом сообщение об ошибке выдано не будет. Попытка сохранить данные по сети. Если вы вносите изменения в источники, получающие данные из сети (с Web-ресурса или FTP-сайта), такие изменения не могут быть непосредственно "сохранены". Этот механизм применим только к локальным файлам. Чтобы передать сделанные изменения на удаленный сервер, необходимо создать на основе источника данных документ RDF, используя интерфейс источника содержимого. Затем полученный документ можно загрузить на сервер при помощи механизма передачи файлов. Решение более низкого уровня может быть основано на использовании сокета. Использование false в качестве аргумента методов Assert() и Unassert(). Четвертым аргументом этих методов всегда должно быть true. Использование false расширяет логику методов RDF непродуктивным образом. Всегда используйте true. Передача строк методам Assert() и Unassert(). Эти методы принимают только объекты типа nsIRDFNode и его подтипов. Проблемы с множественными возвращаемыми значениями. Такие методы, как GetTargets() возвращают объект-перечислитель nsISimpleEnumerator, содержащий список URI, соответствующих запросу. Все объекты, возвращаемые перечислителем, поддерживают интерфейс nsISupports. Используйте метод QueryInterface() для того, чтобы получить более полезный интерфейс nsIRDFNode или один из его подтипов. Объекты, реализующие интерфейс nsIRDFContainerUtils, являются служебными. Они используются для выполнения различных действий с другими объектами, передаваемыми им в качестве аргументов. 16.7.1. Получение содержимого источника данныхВнутренние источники данных RDF являются одним из наиболее сложных аспектов платформы Mozilla. В листинге 16.22 представлен фрагмент кода, который может использоваться для получения их содержимого. function _dumpFactSubtree(ds, sub, level)
{
var iter, iter2, pred, obj, objstr, result="";
// выйти, если передан nsIRDFLiteral или другой не-URI
try { iter = ds.ArcLabelsOut(sub); }
catch (ex) { return; }
while (iter.hasMoreElements())
{
pred = iter.getNext().QueryInterface(Ci.nsIRDFResource);
iter2 = ds.GetTargets(sub, pred, true);
while (iter2.hasMoreElements())
{
obj = iter2.getNext();
try {
obj = obj.QueryInterface(Ci.nsIRDFResource);
objstr = obj.Value;
}
catch (ex)
{
obj = obj.QueryInterface(Ci.nsIRDFLiteral);
objstr = '"' + obj.Value + '"';
}
result += level + " " + sub.Value + " , " +
pred.Value + " , " + objstr + "\n";
result += dumpFactSubtree(ds, obj, level+1);
}
}
return result;
}
function dumpFromRoot(ds, rootURI)
{
return _dumpFactSubtree(ds, rootURI, 0);
}
Листинг
16.22.
Получение содержимого источника данных.Для вывода всех данных источника следует вызвать функцию dumpFromRoot(). Этот код использует ограниченное подмножество функциональности интерфейса nsIRDFDataSource и должен работать с большинством внутренних источников данных, а также с простыми файлами RDF. Код выполняет рекурсивный поиск, начиная с указанного узла, и исходит из того, что граф RDF в источнике данных организован как дерево. В качестве аргументов функции должны быть переданы объекты nsIRDFDataSource и nsIRDFResource. Источник данных, представленный первым объектом, должен быть полностью загружен - в противном случае может быть выведена неполная информация о его содержимом. Аргумент rootURI должен быть контейнером или владельцем контейнера на графе RDF источника данных. В качестве примера можно привести URI, представленные в таблице 16.11. Если граф RDF содержит циклы, код будет выполнять бесконечную рекурсию, что может привести к зависанию платформы или аварийному прекращению ее работы. Это довольно примитивный инструмент для тестирования, так что следует относиться к нему соответствующим образом. 16.8. ИтогиИнфраструктура платформы Mozilla содержит множество полезных объектов, не все из которых были освещены в этой главе. Большинство из них являются объектами довольно высокого уровня в силу требований переносимости и ориентации на разработку приложений. Можно представить себе, что в дальнейшем в составе платформы будет реализован аналог интерфейса POSIX, однако в силу общей ориентированности платформы на разработку приложений высокого уровня потребность в таком интерфейсе невелика. Mozilla предоставляет богатые возможности для работы с XML, что неудивительно. Первоначально интенсивная обработка XML была характерна для приложений класса business-to-business, однако инициатива .NET компании Microsoft подразумевает активное использование XML на стороне клиента. К настоящему моменту мы рассмотрели как интерфейс приложений Mozilla, так и их инфраструктуру, и нам осталось лишь познакомиться с развертыванием этих приложений. Наряду с системой сборки Mozilla, которая используется для создания компилированных приложений, существует и система удаленной установки приложений Mozilla. Эта система, XPInstall, и является предметом заключительной главе курса. 2) Channel, в отличие от канала как средства взаимодействия между процессами (pipe). |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||